Geometric sparsification in recurrent neural networks

0

Sign in to get full access
Overview
- This paper presents a novel approach called "geometric sparsification" for recurrent neural networks (RNNs) that can significantly reduce the number of parameters while maintaining performance.
- The key idea is to leverage the geometric structure of the RNN's hidden state space to identify and remove redundant parameters without compromising the network's functionality.
- The authors demonstrate the effectiveness of their method on several benchmark tasks, showing that geometric sparsification can achieve high compression rates while preserving the model's accuracy.
Plain English Explanation
The paper introduces a technique called "geometric sparsification" that can make recurrent neural networks (RNNs) much smaller and more efficient, without sacrificing their performance. RNNs are a type of neural network commonly used for processing sequential data, like text or speech.
The core insight is that the hidden states of an RNN, which store information as the network processes input, actually live in a geometric space. By analyzing the structure of this geometric space, the researchers found that many of the network's parameters (the values that the network learns during training) are redundant and can be removed without significantly affecting the network's capabilities.
Imagine an RNN as a black box that takes in a sequence of inputs, like words in a sentence, and produces a sequence of outputs, like a translation or summary. Inside this black box, there are millions of interconnected "neurons" and parameters that determine how the network processes the information. Geometric sparsification allows the researchers to identify and remove many of these parameters without breaking the network.
By applying this technique, the researchers were able to reduce the size of RNNs by up to 90% while maintaining their performance on benchmark tasks. This could lead to more efficient and compact RNN models, which could be particularly useful for deploying these models on resource-constrained devices like smartphones or embedded systems.
Technical Explanation
The key innovation in this paper is the concept of "geometric sparsification" for recurrent neural networks (RNNs). The authors observe that the hidden state representations of RNNs live in a geometric space, and that this geometric structure can be exploited to identify and remove redundant parameters without significantly degrading the network's performance.
Specifically, the authors propose a three-step process:
-
Geometric analysis: They analyze the geometry of the RNN's hidden state space to identify directions in this space that are not critical for the network's functionality. This is done by examining the principal components of the hidden state covariance matrix.
-
Parameter pruning: Based on the geometric analysis, the authors selectively remove parameters from the RNN that are associated with the less important directions in the hidden state space. This results in a "geometrically sparse" version of the original RNN.
-
Fine-tuning: Finally, the geometrically sparse RNN is fine-tuned on the original task to recover any potential performance loss due to the parameter pruning.
The authors evaluate their geometric sparsification method on several benchmark tasks, including language modeling and machine translation. They demonstrate that their approach can achieve significant compression rates (up to 90% reduction in parameters) while preserving the original model's accuracy.
Critical Analysis
The geometric sparsification approach presented in this paper is a promising technique for reducing the parameter count of recurrent neural networks without sacrificing performance. By leveraging the underlying geometric structure of the RNN's hidden state space, the authors are able to identify and prune redundant parameters in a principled manner.
One potential limitation of the approach is that the geometric analysis and pruning steps may not generalize as well to more complex RNN architectures, such as those with skip connections or gating mechanisms. The authors acknowledge this and suggest that further research is needed to extend the geometric sparsification method to handle a broader range of RNN models.
Additionally, the paper does not explore the trade-offs between the level of sparsification and the resulting model performance. It would be valuable to understand how the compression rate and accuracy scale as the authors adjust the pruning thresholds or other hyperparameters of the geometric sparsification algorithm.
Despite these potential areas for improvement, the research presented in this paper represents an important step forward in the field of efficient neural network design. By leveraging the underlying geometric structure of RNNs, the authors have demonstrated a compelling approach for significantly reducing the parameter count of these models while preserving their functionality. This could lead to more compact and computationally efficient RNN-based systems, with applications in edge computing, mobile devices, and other resource-constrained environments.
Conclusion
This paper introduces a novel technique called "geometric sparsification" for compressing recurrent neural networks (RNNs) without compromising their performance. By analyzing the geometric structure of the RNN's hidden state space, the authors are able to identify and remove redundant parameters, resulting in significantly smaller and more efficient models.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, achieving compression rates of up to 90% while maintaining the original model's accuracy. This work represents an important contribution to the field of efficient neural network design, as it provides a principled way to reduce the computational and memory footprint of RNNs, which are widely used in a variety of applications, such as language modeling, machine translation, and speech recognition.
The geometric sparsification method proposed in this paper could have far-reaching implications, enabling the deployment of high-performance RNN models on resource-constrained devices and opening up new possibilities for building more energy-efficient and scalable AI systems. As the demand for deploying advanced neural networks in edge and mobile environments continues to grow, techniques like geometric sparsification will become increasingly crucial for realizing the full potential of these powerful machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Geometric sparsification in recurrent neural networks
Wyatt Mackey, Ioannis Schizas, Jared Deighton, David L. Boothe, Jr., Vasileios Maroulas
A common technique for ameliorating the computational costs of running large neural models is sparsification, or the removal of neural connections during training. Sparse models are capable of maintaining the high accuracy of state of the art models, while functioning at the cost of more parsimonious models. The structures which underlie sparse architectures are, however, poorly understood and not consistent between differently trained models and sparsification schemes. In this paper, we propose a new technique for sparsification of recurrent neural nets (RNNs), called moduli regularization, in combination with magnitude pruning. Moduli regularization leverages the dynamical system induced by the recurrent structure to induce a geometric relationship between neurons in the hidden state of the RNN. By making our regularizing term explicitly geometric, we provide the first, to our knowledge, a priori description of the desired sparse architecture of our neural net. We verify the effectiveness of our scheme for navigation and natural language processing RNNs. Navigation is a structurally geometric task, for which there are known moduli spaces, and we show that regularization can be used to reach 90% sparsity while maintaining model performance only when coefficients are chosen in accordance with a suitable moduli space. Natural language processing, however, has no known moduli space in which computations are performed. Nevertheless, we show that moduli regularization induces more stable recurrent neural nets with a variety of moduli regularizers, and achieves high fidelity models at 98% sparsity.
Read more6/11/2024
🧠
0
Investigating Sparsity in Recurrent Neural Networks
Harshil Darji
In the past few years, neural networks have evolved from simple Feedforward Neural Networks to more complex neural networks, such as Convolutional Neural Networks and Recurrent Neural Networks. Where CNNs are a perfect fit for tasks where the sequence is not important such as image recognition, RNNs are useful when order is important such as machine translation. An increasing number of layers in a neural network is one way to improve its performance, but it also increases its complexity making it much more time and power-consuming to train. One way to tackle this problem is to introduce sparsity in the architecture of the neural network. Pruning is one of the many methods to make a neural network architecture sparse by clipping out weights below a certain threshold while keeping the performance near to the original. Another way is to generate arbitrary structures using random graphs and embed them between an input and output layer of an Artificial Neural Network. Many researchers in past years have focused on pruning mainly CNNs, while hardly any research is done for the same in RNNs. The same also holds in creating sparse architectures for RNNs by generating and embedding arbitrary structures. Therefore, this thesis focuses on investigating the effects of the before-mentioned two techniques on the performance of RNNs. We first describe the pruning of RNNs, its impact on the performance of RNNs, and the number of training epochs required to regain accuracy after the pruning is performed. Next, we continue with the creation and training of Sparse Recurrent Neural Networks and identify the relation between the performance and the graph properties of its underlying arbitrary structure. We perform these experiments on RNN with Tanh nonlinearity (RNN-Tanh), RNN with ReLU nonlinearity (RNN-ReLU), GRU, and LSTM. Finally, we analyze and discuss the results achieved from both the experiments.
Read more7/31/2024

0
Robust Training of Neural Networks at Arbitrary Precision and Sparsity
Chengxi Ye, Grace Chu, Yanfeng Liu, Yichi Zhang, Lukasz Lew, Andrew Howard
The discontinuous operations inherent in quantization and sparsification introduce obstacles to backpropagation. This is particularly challenging when training deep neural networks in ultra-low precision and sparse regimes. We propose a novel, robust, and universal solution: a denoising affine transform that stabilizes training under these challenging conditions. By formulating quantization and sparsification as perturbations during training, we derive a perturbation-resilient approach based on ridge regression. Our solution employs a piecewise constant backbone model to ensure a performance lower bound and features an inherent noise reduction mechanism to mitigate perturbation-induced corruption. This formulation allows existing models to be trained at arbitrarily low precision and sparsity levels with off-the-shelf recipes. Furthermore, our method provides a novel perspective on training temporal binary neural networks, contributing to ongoing efforts to narrow the gap between artificial and biological neural networks.
Read more9/17/2024
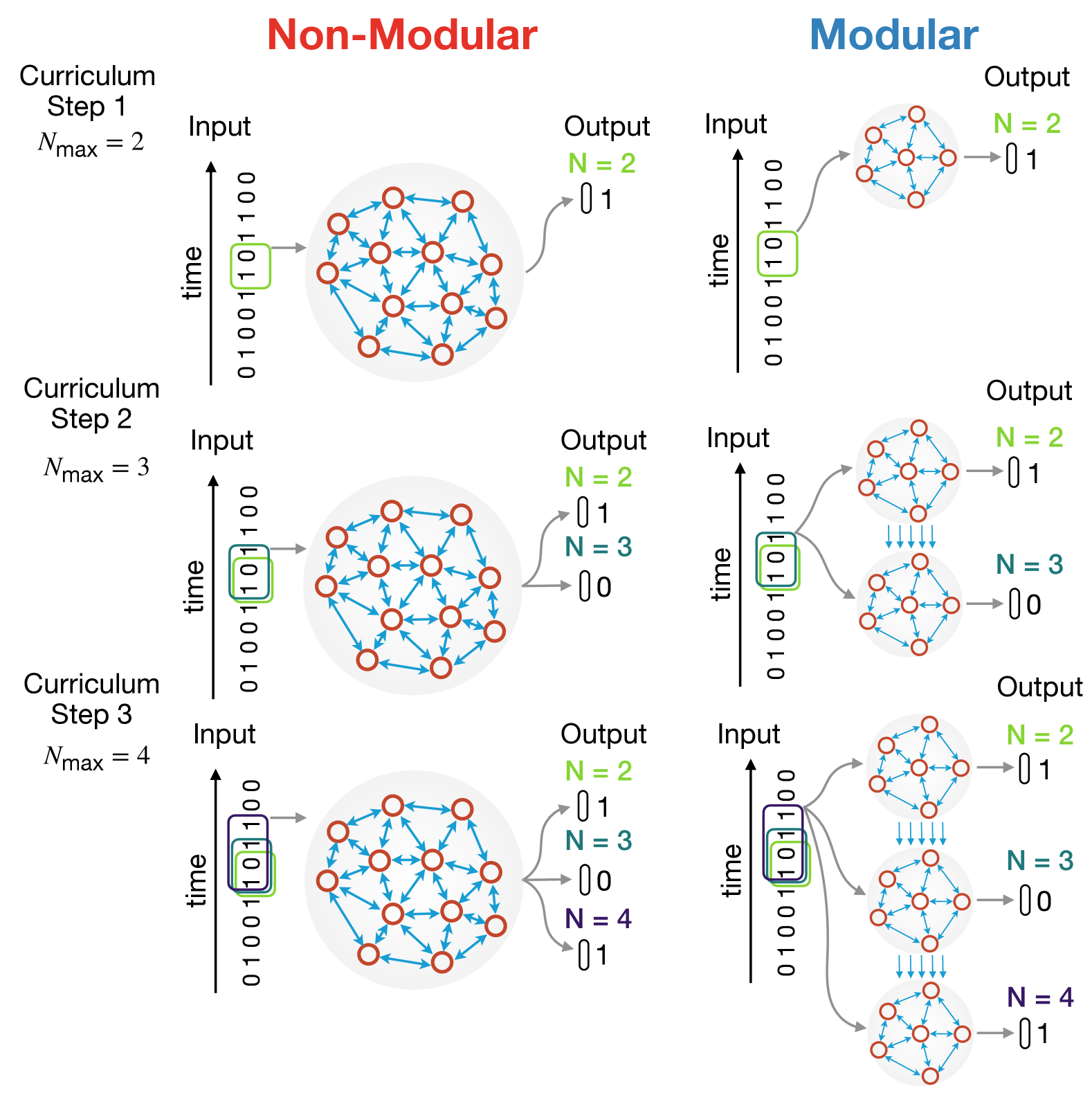
0
Modular Growth of Hierarchical Networks: Efficient, General, and Robust Curriculum Learning
Mani Hamidi, Sina Khajehabdollahi, Emmanouil Giannakakis, Tim Schafer, Anna Levina, Charley M. Wu
Structural modularity is a pervasive feature of biological neural networks, which have been linked to several functional and computational advantages. Yet, the use of modular architectures in artificial neural networks has been relatively limited despite early successes. Here, we explore the performance and functional dynamics of a modular network trained on a memory task via an iterative growth curriculum. We find that for a given classical, non-modular recurrent neural network (RNN), an equivalent modular network will perform better across multiple metrics, including training time, generalizability, and robustness to some perturbations. We further examine how different aspects of a modular network's connectivity contribute to its computational capability. We then demonstrate that the inductive bias introduced by the modular topology is strong enough for the network to perform well even when the connectivity within modules is fixed and only the connections between modules are trained. Our findings suggest that gradual modular growth of RNNs could provide advantages for learning increasingly complex tasks on evolutionary timescales, and help build more scalable and compressible artificial networks.
Read more6/11/2024