A Geometric Unification of Distributionally Robust Covariance Estimators: Shrinking the Spectrum by Inflating the Ambiguity Set

0
Sign in to get full access
Overview
- This paper proposes a geometric unification of distributionally robust covariance estimators, which allows for the shrinking of the spectrum by inflating the ambiguity set.
- The authors introduce a novel approach that extends existing methods for robust covariance estimation, providing a more flexible and effective way to handle uncertainty in the data.
- The research connects concepts from robust optimization, statistical estimation, and matrix theory, offering a comprehensive framework for understanding and improving the performance of covariance estimators.
Plain English Explanation
In this paper, the authors present a new way to estimate the covariance, or how variables in a dataset are related to each other, in a robust and reliable manner. Covariance estimation is an important task in many areas of data analysis, but it can be challenging when the data is uncertain or noisy.
The key idea behind the authors' approach is to think of the covariance estimation problem from a geometric perspective. They show that by "inflating" the set of possible covariance matrices that the data could come from (the "ambiguity set"), they can then "shrink" the spectrum, or range of values, of the estimated covariance matrix. This allows them to obtain a more reliable and stable estimate of the covariance, even in the face of uncertainty or noise in the data.
The authors draw on concepts from robust optimization, statistical estimation, and matrix theory to develop their framework. This provides a unifying perspective that connects several existing methods for robust covariance estimation, and offers a more flexible and effective way to handle uncertainty in the data.
Technical Explanation
The authors introduce a novel approach to distributionally robust covariance estimation that leverages concepts from robust optimization, statistical estimation, and matrix theory. The key idea is to think of the covariance estimation problem from a geometric perspective, where the goal is to "shrink" the spectrum of the estimated covariance matrix by "inflating" the ambiguity set of possible covariance matrices.
Specifically, the authors propose a unified framework that encompasses several existing methods for robust covariance estimation, such as analysis of multi-target linear shrinkage covariance estimators, quantifying distribution shifts and uncertainties for enhanced model robustness, and robustness implies privacy in statistical estimation. By leveraging this geometric perspective, the authors are able to develop a more flexible and effective approach for handling uncertainty in the data, leading to improved performance of covariance estimators.
Critical Analysis
The authors present a comprehensive and theoretically sound framework for distributionally robust covariance estimation. However, the paper does not extensively discuss the practical implications and potential limitations of their approach.
For example, the authors mention that their framework can be computationally challenging for large-scale problems, and it would be useful to have a more in-depth discussion of the scalability and efficiency of their methods. Additionally, the authors do not explore the potential trade-offs between the degree of ambiguity set inflation and the resulting spectrum shrinkage, which could be an important consideration in real-world applications.
Furthermore, the paper does not provide a detailed comparison with other state-of-the-art methods for robust covariance estimation, nor does it explore the potential applications of the proposed approach beyond the theoretical framework. It would be valuable to see how the authors' methods perform in various domains and how they compare to alternative techniques.
Conclusion
This paper presents a geometric unification of distributionally robust covariance estimators, which allows for the shrinking of the spectrum by inflating the ambiguity set. The authors' approach offers a flexible and effective way to handle uncertainty in the data, drawing on concepts from robust optimization, statistical estimation, and matrix theory.
The proposed framework provides a comprehensive understanding of the connections between various methods for robust covariance estimation, and it has the potential to lead to improved performance in a wide range of applications. However, the paper could benefit from a more thorough discussion of the practical implications, limitations, and scalability of the authors' methods, as well as a more detailed comparison with other state-of-the-art techniques.
Overall, this research represents a significant contribution to the field of robust covariance estimation, and it opens up new avenues for further exploration and development in this important area of data analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Geometric Unification of Distributionally Robust Covariance Estimators: Shrinking the Spectrum by Inflating the Ambiguity Set
Man-Chung Yue, Yves Rychener, Daniel Kuhn, Viet Anh Nguyen
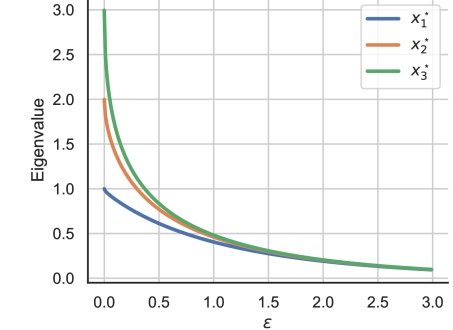
The state-of-the-art methods for estimating high-dimensional covariance matrices all shrink the eigenvalues of the sample covariance matrix towards a data-insensitive shrinkage target. The underlying shrinkage transformation is either chosen heuristically - without compelling theoretical justification - or optimally in view of restrictive distributional assumptions. In this paper, we propose a principled approach to construct covariance estimators without imposing restrictive assumptions. That is, we study distributionally robust covariance estimation problems that minimize the worst-case Frobenius error with respect to all data distributions close to a nominal distribution, where the proximity of distributions is measured via a divergence on the space of covariance matrices. We identify mild conditions on this divergence under which the resulting minimizers represent shrinkage estimators. We show that the corresponding shrinkage transformations are intimately related to the geometrical properties of the underlying divergence. We also prove that our robust estimators are efficiently computable and asymptotically consistent and that they enjoy finite-sample performance guarantees. We exemplify our general methodology by synthesizing explicit estimators induced by the Kullback-Leibler, Fisher-Rao, and Wasserstein divergences. Numerical experiments based on synthetic and real data show that our robust estimators are competitive with state-of-the-art estimators.
Read more5/31/2024

0
Analysis of a multi-target linear shrinkage covariance estimator
Benoit Oriol
Multi-target linear shrinkage is an extension of the standard single-target linear shrinkage for covariance estimation. We combine several constant matrices - the targets - with the sample covariance matrix. We derive the oracle and a textit{bona fide} multi-target linear shrinkage estimator with exact and empirical mean. In both settings, we proved its convergence towards the oracle under Kolmogorov asymptotics. Finally, we show empirically that it outperforms other standard estimators in various situations.
Read more5/31/2024
🔍
0
Robust Distribution Learning with Local and Global Adversarial Corruptions
Sloan Nietert, Ziv Goldfeld, Soroosh Shafiee
We consider learning in an adversarial environment, where an $varepsilon$-fraction of samples from a distribution $P$ are arbitrarily modified (*global* corruptions) and the remaining perturbations have average magnitude bounded by $rho$ (*local* corruptions). Given access to $n$ such corrupted samples, we seek a computationally efficient estimator $hat{P}_n$ that minimizes the Wasserstein distance $mathsf{W}_1(hat{P}_n,P)$. In fact, we attack the fine-grained task of minimizing $mathsf{W}_1(Pi_# hat{P}_n, Pi_# P)$ for all orthogonal projections $Pi in mathbb{R}^{d times d}$, with performance scaling with $mathrm{rank}(Pi) = k$. This allows us to account simultaneously for mean estimation ($k=1$), distribution estimation ($k=d$), as well as the settings interpolating between these two extremes. We characterize the optimal population-limit risk for this task and then develop an efficient finite-sample algorithm with error bounded by $sqrt{varepsilon k} + rho + d^{O(1)}tilde{O}(n^{-1/k})$ when $P$ has bounded moments of order $2+delta$, for constant $delta > 0$. For data distributions with bounded covariance, our finite-sample bounds match the minimax population-level optimum for large sample sizes. Our efficient procedure relies on a novel trace norm approximation of an ideal yet intractable 2-Wasserstein projection estimator. We apply this algorithm to robust stochastic optimization, and, in the process, uncover a new method for overcoming the curse of dimensionality in Wasserstein distributionally robust optimization.
Read more6/11/2024
0
Quantifying Distribution Shifts and Uncertainties for Enhanced Model Robustness in Machine Learning Applications
Vegard Flovik
Distribution shifts, where statistical properties differ between training and test datasets, present a significant challenge in real-world machine learning applications where they directly impact model generalization and robustness. In this study, we explore model adaptation and generalization by utilizing synthetic data to systematically address distributional disparities. Our investigation aims to identify the prerequisites for successful model adaptation across diverse data distributions, while quantifying the associated uncertainties. Specifically, we generate synthetic data using the Van der Waals equation for gases and employ quantitative measures such as Kullback-Leibler divergence, Jensen-Shannon distance, and Mahalanobis distance to assess data similarity. These metrics en able us to evaluate both model accuracy and quantify the associated uncertainty in predictions arising from data distribution shifts. Our findings suggest that utilizing statistical measures, such as the Mahalanobis distance, to determine whether model predictions fall within the low-error interpolation regime or the high-error extrapolation regime provides a complementary method for assessing distribution shift and model uncertainty. These insights hold significant value for enhancing model robustness and generalization, essential for the successful deployment of machine learning applications in real-world scenarios.
Read more5/6/2024