Geometry of Critical Sets and Existence of Saddle Branches for Two-layer Neural Networks

0
Sign in to get full access
Overview
- This paper examines the geometry of critical sets and the existence of saddle branches in two-layer neural networks.
- The researchers investigate the structural properties of the loss landscape of these networks, which is important for understanding their optimization and generalization behavior.
- The paper provides theoretical and empirical insights into the characteristics of critical points and saddle branches in the loss function.
Plain English Explanation
Neural networks are powerful machine learning models that can learn to perform a wide variety of tasks, from image recognition to language processing. However, training these networks can be challenging because the optimization process involves navigating a complex, high-dimensional landscape of potential solutions.
This paper takes a closer look at the geometry of this landscape for two-layer neural networks, which are relatively simple but still important models. The researchers analyze the critical points (where the gradient of the loss function is zero) and saddle branches (pathways that connect different critical points) that exist in this landscape.
By understanding the structure of the loss function, the researchers hope to gain insights that can help improve the optimization and generalization of neural networks. For example, the existence of saddle branches may create challenges for optimization algorithms, as they can get stuck in local minima. Conversely, the presence of certain types of critical points may indicate that the network has the capacity to learn complex patterns in the data.
Technical Explanation
The paper presents a theoretical and empirical analysis of the geometry of critical sets and the existence of saddle branches in two-layer neural networks. The researchers consider a two-layer network with a single hidden layer and a linear output layer, using a ReLU activation function.
Theoretically, the paper establishes several properties of the critical points and saddle branches in this network architecture. For example, the researchers show that the critical points are always "star-shaped" (as described in this paper), and that saddle branches can exist between certain types of critical points.
Empirically, the paper investigates these properties using numerical experiments on synthetic and real-world datasets. The researchers demonstrate the presence of saddle branches in the loss landscape and explore how they are affected by factors such as the network size, input dimension, and data distribution.
The insights from this work contribute to a broader understanding of the dynamics of neural network training and the underlying structure of the loss function. This knowledge can inform the design of more effective optimization algorithms and help explain the emergent criticality observed in neural network training.
Critical Analysis
The paper provides a rigorous theoretical and empirical analysis of the loss landscape of two-layer neural networks, which is an important step in understanding the fundamental properties of these models. The researchers' findings on the star-shaped geometry of critical points and the existence of saddle branches offer valuable insights that can inform future work on optimization and generalization in neural networks.
However, it's important to note that the analysis is limited to a relatively simple network architecture with a single hidden layer. While this serves as a useful starting point, the findings may not necessarily extend to deeper or more complex neural network architectures, which are often used in practical applications. Additionally, the paper focuses on the loss landscape in the parameter space, but the relationship between this landscape and the network's performance on real-world tasks is not directly addressed.
Further research could explore the applicability of these insights to more realistic network designs and investigate the connections between the loss landscape and practical measures of model performance, such as generalization error. Incorporating techniques from differential geometry and dynamical systems theory may also provide additional avenues for advancing the understanding of neural network loss landscapes.
Conclusion
This paper presents a detailed analysis of the geometry of critical sets and the existence of saddle branches in two-layer neural networks. The researchers establish theoretical properties of the loss landscape and validate them through numerical experiments, offering valuable insights into the fundamental structure of these models.
The findings contribute to a growing body of work that seeks to better understand the optimization and generalization behavior of neural networks. By shedding light on the complex loss landscape, this research can inform the development of more effective training algorithms and provide a foundation for further investigations into the underlying principles governing neural network learning.
As the field of deep learning continues to evolve, studies like this one will play an important role in unveiling the intricate mathematical and geometrical properties of these powerful machine learning models, ultimately leading to more robust and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Geometry of Critical Sets and Existence of Saddle Branches for Two-layer Neural Networks
Leyang Zhang, Yaoyu Zhang, Tao Luo
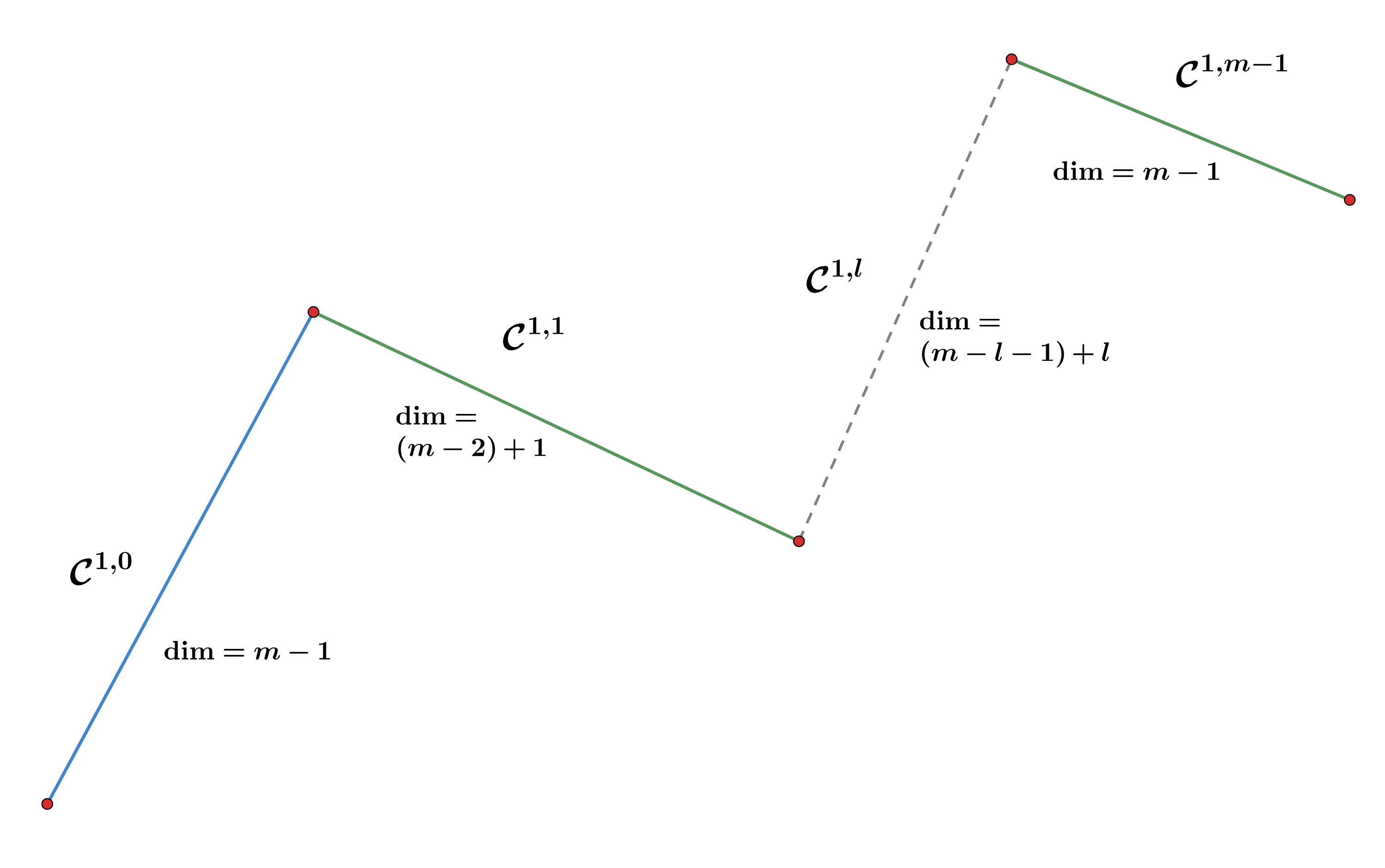
This paper presents a comprehensive analysis of critical point sets in two-layer neural networks. To study such complex entities, we introduce the critical embedding operator and critical reduction operator as our tools. Given a critical point, we use these operators to uncover the whole underlying critical set representing the same output function, which exhibits a hierarchical structure. Furthermore, we prove existence of saddle branches for any critical set whose output function can be represented by a narrower network. Our results provide a solid foundation to the further study of optimization and training behavior of neural networks.
Read more5/29/2024
🤿
0
The loss landscape of deep linear neural networks: a second-order analysis
El Mehdi Achour (IMT), Franc{c}ois Malgouyres (IMT), S'ebastien Gerchinovitz (IMT)
We study the optimization landscape of deep linear neural networks with the square loss. It is known that, under weak assumptions, there are no spurious local minima and no local maxima. However, the existence and diversity of non-strict saddle points, which can play a role in first-order algorithms' dynamics, have only been lightly studied. We go a step further with a full analysis of the optimization landscape at order 2. We characterize, among all critical points, which are global minimizers, strict saddle points, and non-strict saddle points. We enumerate all the associated critical values. The characterization is simple, involves conditions on the ranks of partial matrix products, and sheds some light on global convergence or implicit regularization that have been proved or observed when optimizing linear neural networks. In passing, we provide an explicit parameterization of the set of all global minimizers and exhibit large sets of strict and non-strict saddle points.
Read more9/26/2024
🧠
0
Loss Landscape of Shallow ReLU-like Neural Networks: Stationary Points, Saddle Escaping, and Network Embedding
Zhengqing Wu, Berfin Simsek, Francois Ged
In this paper, we investigate the loss landscape of one-hidden-layer neural networks with ReLU-like activation functions trained with the empirical squared loss. As the activation function is non-differentiable, it is so far unclear how to completely characterize the stationary points. We propose the conditions for stationarity that apply to both non-differentiable and differentiable cases. Additionally, we show that, if a stationary point does not contain escape neurons, which are defined with first-order conditions, then it must be a local minimum. Moreover, for the scalar-output case, the presence of an escape neuron guarantees that the stationary point is not a local minimum. Our results refine the description of the saddle-to-saddle training process starting from infinitesimally small (vanishing) initialization for shallow ReLU-like networks, linking saddle escaping directly with the parameter changes of escape neurons. Moreover, we are also able to fully discuss how network embedding, which is to instantiate a narrower network within a wider network, reshapes the stationary points.
Read more6/13/2024

0
Symmetry & Critical Points
Yossi Arjevani
Critical points of an invariant function may or may not be symmetric. We prove, however, that if a symmetric critical point exists, those adjacent to it are generically symmetry breaking. This mathematical mechanism is shown to carry important implications for our ability to efficiently minimize invariant nonconvex functions, in particular those associated with neural networks.
Read more8/27/2024