GeoReasoner: Geo-localization with Reasoning in Street Views using a Large Vision-Language Model
2406.18572
0
0
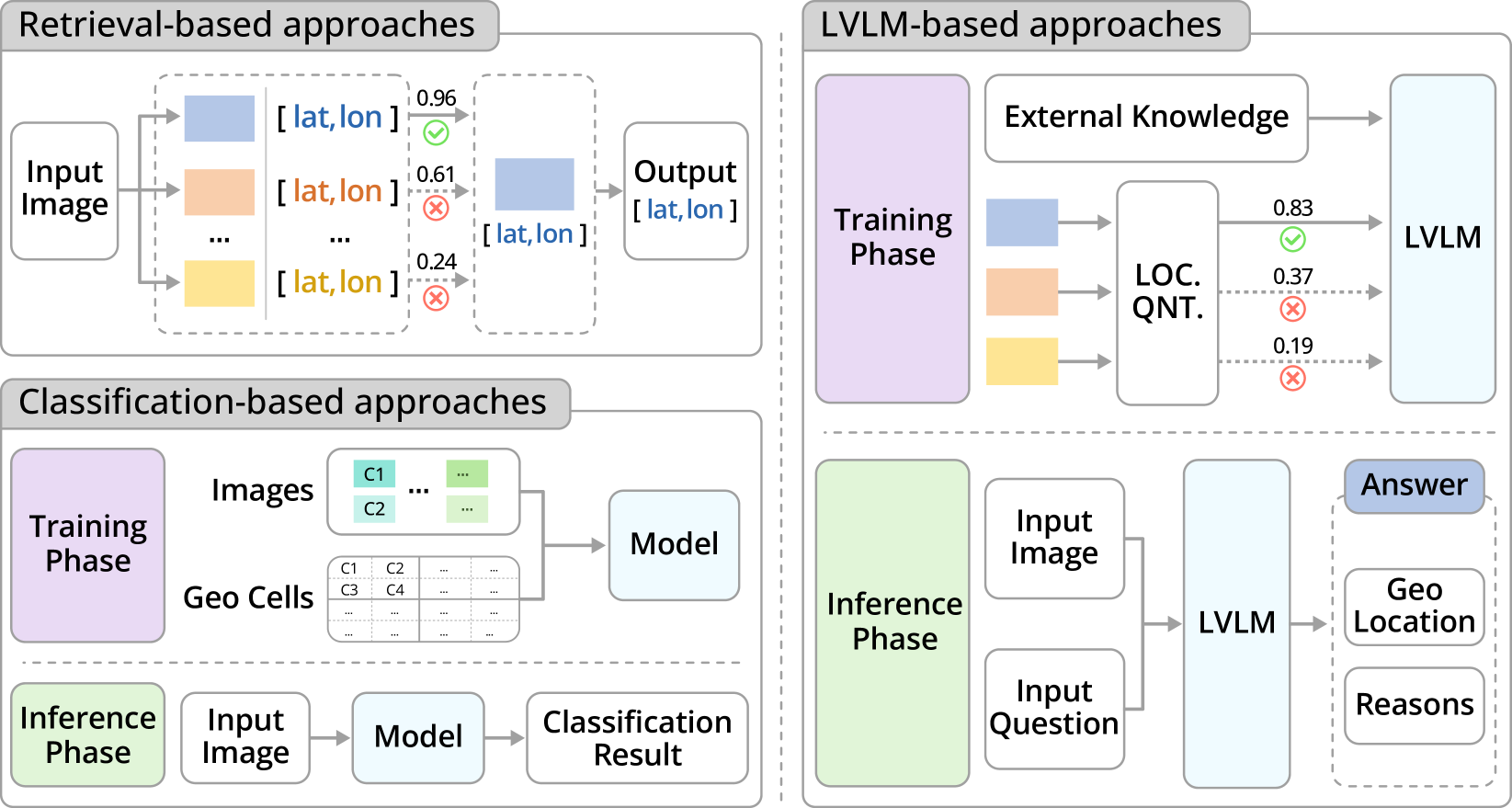
Abstract
This work tackles the problem of geo-localization with a new paradigm using a large vision-language model (LVLM) augmented with human inference knowledge. A primary challenge here is the scarcity of data for training the LVLM - existing street-view datasets often contain numerous low-quality images lacking visual clues, and lack any reasoning inference. To address the data-quality issue, we devise a CLIP-based network to quantify the degree of street-view images being locatable, leading to the creation of a new dataset comprising highly locatable street views. To enhance reasoning inference, we integrate external knowledge obtained from real geo-localization games, tapping into valuable human inference capabilities. The data are utilized to train GeoReasoner, which undergoes fine-tuning through dedicated reasoning and location-tuning stages. Qualitative and quantitative evaluations illustrate that GeoReasoner outperforms counterpart LVLMs by more than 25% at country-level and 38% at city-level geo-localization tasks, and surpasses StreetCLIP performance while requiring fewer training resources. The data and code are available at https://github.com/lingli1996/GeoReasoner.
Create account to get full access
Overview
- This paper introduces GeoReasoner, a system that uses a large vision-language model to perform geo-localization (determining the location of an image) with reasoning on street view images.
- GeoReasoner leverages the capabilities of large language models to understand visual information and reason about the geographic context, allowing it to make more accurate location predictions compared to prior geo-localization approaches.
- The paper presents experiments demonstrating GeoReasoner's strong performance on geo-localization benchmarks, outperforming specialized geo-localization models.
Plain English Explanation
GeoReasoner is a system that can figure out where a street view image was taken using a powerful machine learning model. This model is trained on a huge amount of data, which allows it to understand not just what's in the image, but also the broader geographic context. For example, it can notice things like the type of buildings, the layout of the streets, and other clues that indicate the likely location.
By tapping into this broader understanding, GeoReasoner can make more accurate guesses about where an image was taken, compared to previous systems that just looked at the specific visual details. It's kind of like how a human who has traveled a lot might be able to recognize the general region or city just from seeing a few characteristic features, even if they've never been to that exact spot before.
The paper shows that GeoReasoner outperforms other specialized geo-localization models on standard benchmarks, demonstrating the power of using a large, flexible language model to reason about geographic information from visual data.
Technical Explanation
The core of GeoReasoner is a large vision-language model that has been trained on a massive amount of image and text data. This allows the model to develop a rich understanding of visual concepts and their associations with geographic and contextual information.
To perform geo-localization, GeoReasoner takes a street view image as input and generates a textual description of its geographic location, including details like the country, city, street name, and landmarks. This is accomplished through a multi-stage process:
- The image is passed through the vision-language model to extract high-level visual and semantic features.
- These features are then used to reason about the likely geographic context, leveraging the model's broad knowledge.
- The final location prediction is generated by decoding the textual description from the model's internal representation.
The paper's experiments show that this approach outperforms prior specialized geo-localization models on benchmark datasets. This demonstrates the power of using a flexible, general-purpose language model to tackle the geo-localization task, rather than relying on domain-specific architectures.
Critical Analysis
The GeoReasoner paper presents a compelling approach to geo-localization that leverages the capabilities of large vision-language models. However, the authors acknowledge some limitations and areas for further research:
- The model's performance is still bounded by the quality and coverage of the training data used to pre-train the underlying language model. Expanding the breadth and diversity of this data could further improve the model's geographic reasoning abilities.
- The paper focuses on street view images, but the GeoReasoner approach could potentially be extended to other types of visual data, such as satellite imagery or aerial photography. This could broaden the model's applicability to a wider range of geo-localization scenarios.
- While the authors demonstrate strong results on benchmark datasets, it would be valuable to evaluate the model's performance in real-world applications, where the distribution of images and geographic contexts may differ from the controlled test scenarios.
Additionally, one could raise questions about the potential privacy and security implications of highly accurate geo-localization systems, especially if they are deployed at scale. The research community should continue to consider these societal impacts as this type of technology becomes more advanced.
Conclusion
The GeoReasoner paper presents a novel approach to geo-localization that leverages the power of large vision-language models to reason about the geographic context of street view images. By going beyond just visual pattern matching and tapping into broader semantic and contextual understanding, GeoReasoner demonstrates significant performance improvements over previous specialized geo-localization models.
This work highlights the potential for flexible, general-purpose AI systems to tackle complex spatial reasoning tasks, which could have important applications in fields like urban planning, navigation, and disaster response. As research in this area continues to advance, it will be crucial to consider the societal implications and ensure these technologies are developed and deployed responsibly.
Overall, the GeoReasoner paper makes a valuable contribution to the field of geo-localization and demonstrates the power of large language models to tackle complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
Zhiqiang Wang, Dejia Xu, Rana Muhammad Shahroz Khan, Yanbin Lin, Zhiwen Fan, Xingquan Zhu
0
0
Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
6/3/2024
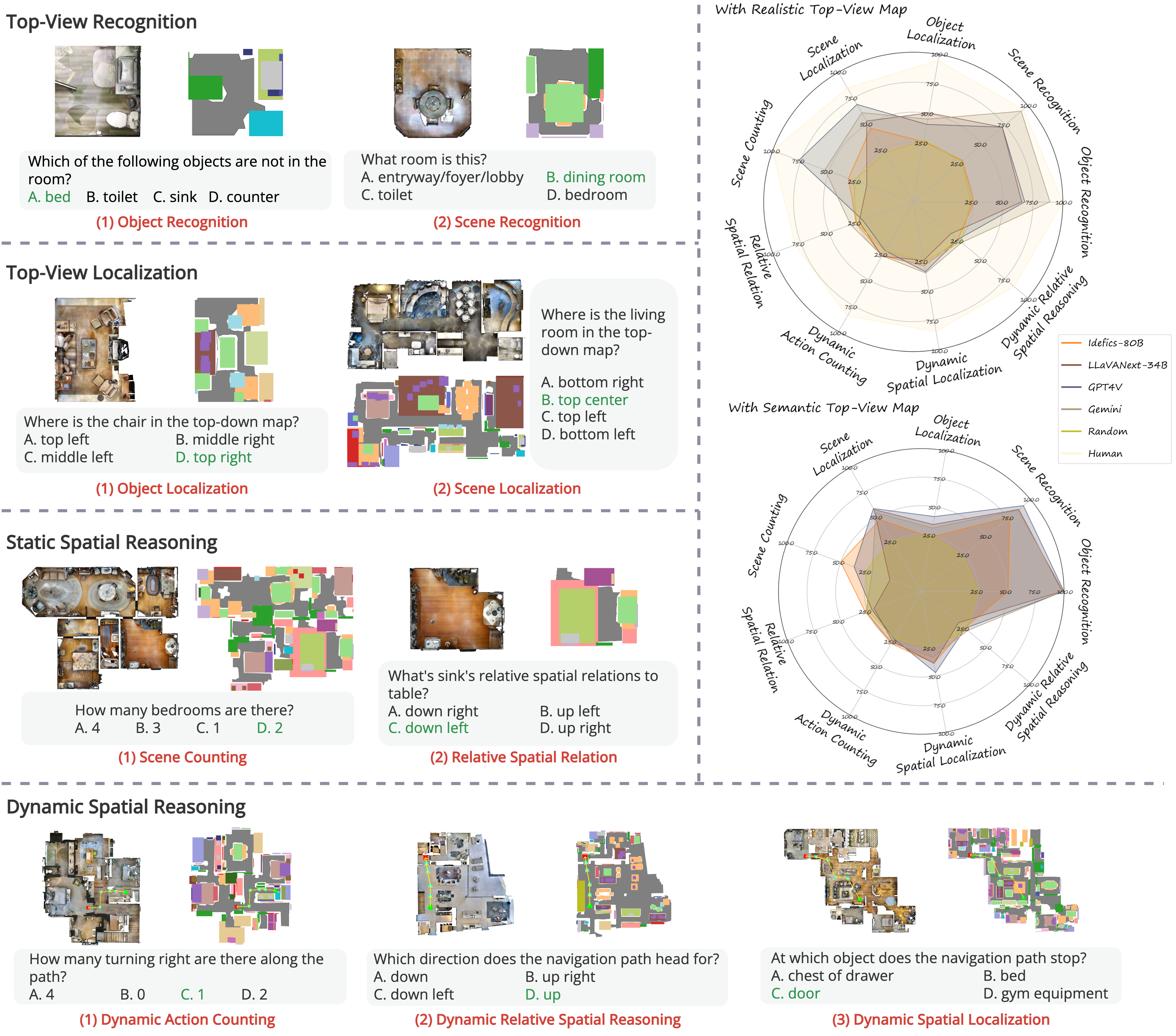
TopViewRS: Vision-Language Models as Top-View Spatial Reasoners
Chengzu Li, Caiqi Zhang, Han Zhou, Nigel Collier, Anna Korhonen, Ivan Vuli'c
0
0
Top-view perspective denotes a typical way in which humans read and reason over different types of maps, and it is vital for localization and navigation of humans as well as of `non-human' agents, such as the ones backed by large Vision-Language Models (VLMs). Nonetheless, spatial reasoning capabilities of modern VLMs remain unattested and underexplored. In this work, we thus study their capability to understand and reason over spatial relations from the top view. The focus on top view also enables controlled evaluations at different granularity of spatial reasoning; we clearly disentangle different abilities (e.g., recognizing particular objects versus understanding their relative positions). We introduce the TopViewRS (Top-View Reasoning in Space) dataset, consisting of 11,384 multiple-choice questions with either realistic or semantic top-view map as visual input. We then use it to study and evaluate VLMs across 4 perception and reasoning tasks with different levels of complexity. Evaluation of 10 representative open- and closed-source VLMs reveals the gap of more than 50% compared to average human performance, and it is even lower than the random baseline in some cases. Although additional experiments show that Chain-of-Thought reasoning can boost model capabilities by 5.82% on average, the overall performance of VLMs remains limited. Our findings underscore the critical need for enhanced model capability in top-view spatial reasoning and set a foundation for further research towards human-level proficiency of VLMs in real-world multimodal tasks.
6/5/2024

ProGEO: Generating Prompts through Image-Text Contrastive Learning for Visual Geo-localization
Chen Mao, Jingqi Hu
0
0
Visual Geo-localization (VG) refers to the process to identify the location described in query images, which is widely applied in robotics field and computer vision tasks, such as autonomous driving, metaverse, augmented reality, and SLAM. In fine-grained images lacking specific text descriptions, directly applying pure visual methods to represent neighborhood features often leads to the model focusing on overly fine-grained features, unable to fully mine the semantic information in the images. Therefore, we propose a two-stage training method to enhance visual performance and use contrastive learning to mine challenging samples. We first leverage the multi-modal description capability of CLIP (Contrastive Language-Image Pretraining) to create a set of learnable text prompts for each geographic image feature to form vague descriptions. Then, by utilizing dynamic text prompts to assist the training of the image encoder, we enable the image encoder to learn better and more generalizable visual features. This strategy of applying text to purely visual tasks addresses the challenge of using multi-modal models for geographic images, which often suffer from a lack of precise descriptions, making them difficult to utilize widely. We validate the effectiveness of the proposed strategy on several large-scale visual geo-localization datasets, and our method achieves competitive results on multiple visual geo-localization datasets. Our code and model are available at https://github.com/Chain-Mao/ProGEO.
6/5/2024

Reason3D: Searching and Reasoning 3D Segmentation via Large Language Model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, Ming-Hsuan Yang
0
0
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
5/28/2024