TopViewRS: Vision-Language Models as Top-View Spatial Reasoners
2406.02537
0
0
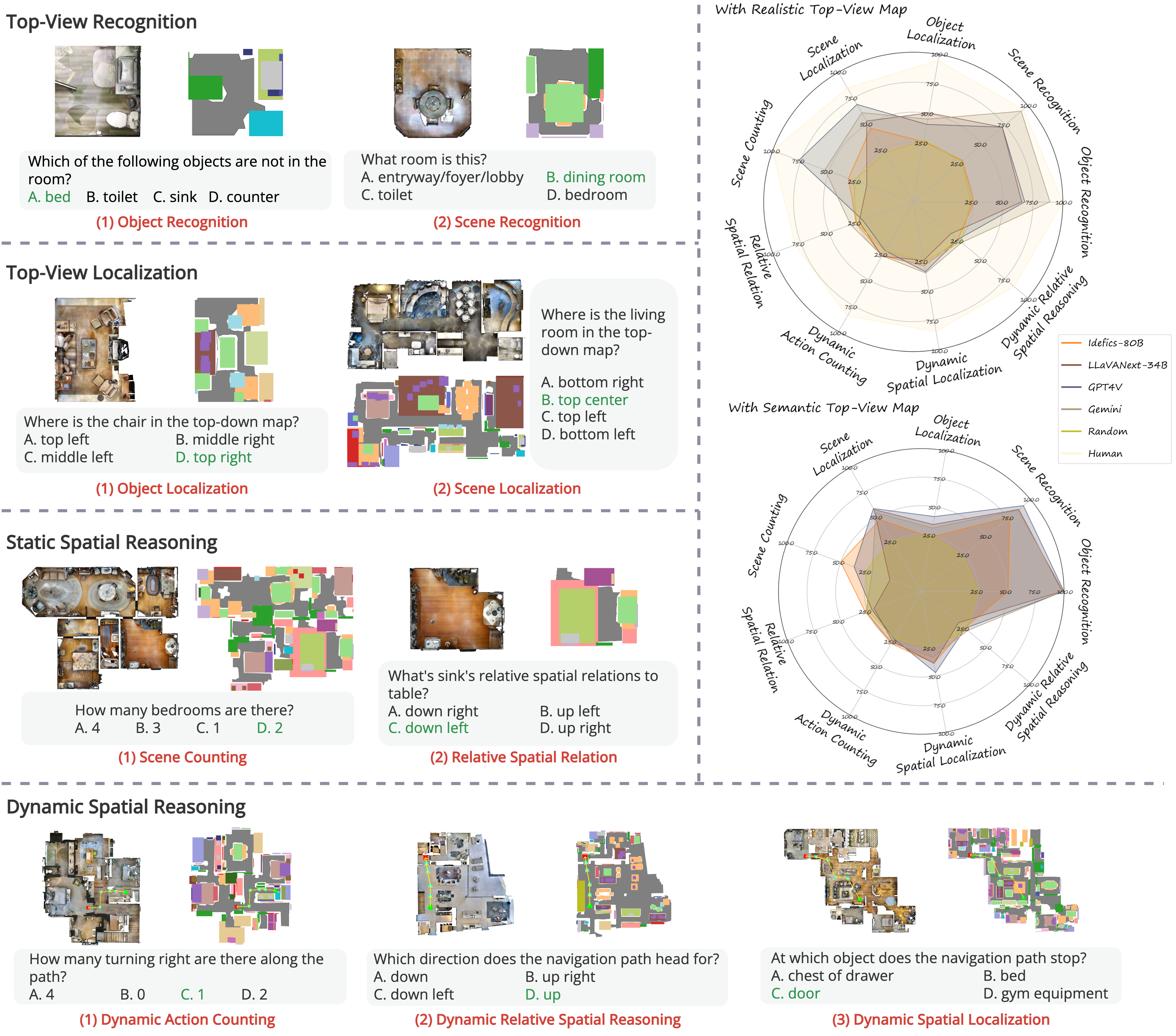
Abstract
Top-view perspective denotes a typical way in which humans read and reason over different types of maps, and it is vital for localization and navigation of humans as well as of `non-human' agents, such as the ones backed by large Vision-Language Models (VLMs). Nonetheless, spatial reasoning capabilities of modern VLMs remain unattested and underexplored. In this work, we thus study their capability to understand and reason over spatial relations from the top view. The focus on top view also enables controlled evaluations at different granularity of spatial reasoning; we clearly disentangle different abilities (e.g., recognizing particular objects versus understanding their relative positions). We introduce the TopViewRS (Top-View Reasoning in Space) dataset, consisting of 11,384 multiple-choice questions with either realistic or semantic top-view map as visual input. We then use it to study and evaluate VLMs across 4 perception and reasoning tasks with different levels of complexity. Evaluation of 10 representative open- and closed-source VLMs reveals the gap of more than 50% compared to average human performance, and it is even lower than the random baseline in some cases. Although additional experiments show that Chain-of-Thought reasoning can boost model capabilities by 5.82% on average, the overall performance of VLMs remains limited. Our findings underscore the critical need for enhanced model capability in top-view spatial reasoning and set a foundation for further research towards human-level proficiency of VLMs in real-world multimodal tasks.
Create account to get full access
Overview
- This paper introduces TopViewRS, a vision-language model that can reason about spatial relationships from a top-down perspective.
- TopViewRS is designed to understand and answer questions about the spatial arrangement of objects in a scene, by converting 2D images into a top-down spatial representation.
- The model is trained on a dataset of images and associated captions, and can then be used to answer questions about the spatial layout and relationships between objects.
Plain English Explanation
The researchers have developed a new artificial intelligence (AI) system called TopViewRS that is able to understand and reason about the spatial arrangement of objects in an image from a top-down perspective.
Traditionally, many AI systems that work with images have a hard time understanding the spatial relationships between objects. For example, they may be able to identify the objects in an image, but struggle to answer questions like "Is the chair to the left of the table?"
TopViewRS aims to address this by converting the 2D image into a more abstract, top-down spatial representation. This allows the model to better understand how the objects in the scene are arranged relative to each other. The model is trained on a large dataset of images and their associated captions, which teaches it to make these kinds of spatial inferences.
Once trained, TopViewRS can then be used to answer questions about the spatial layout of objects in new images. This could be useful in a variety of applications, such as [LINK: https://aimodels.fyi/papers/arxiv/towards-top-down-reasoning-explainable-multi-agent]robotic navigation[/LINK] or [LINK: https://aimodels.fyi/papers/arxiv/learning-to-localize-objects-improves-spatial-reasoning]object localization[/LINK].
Technical Explanation
The key innovation in TopViewRS is the conversion of 2D image inputs into a top-down spatial representation. This is done through a vision-language model that learns to map images to a top-down spatial layout, based on the associated captions in the training data.
Specifically, the model consists of a vision encoder, which processes the input image, and a language decoder, which generates a textual description of the scene from the top-down perspective. The model is trained end-to-end on a dataset of images and captions that describe the spatial arrangement of objects.
During inference, the vision encoder first processes a new image to extract a top-down spatial layout. This layout is then passed to the language decoder, which can generate natural language descriptions answering questions about the spatial relationships between objects.
The authors evaluate TopViewRS on a variety of spatial reasoning tasks, such as answering questions about object locations and relative positions. The results show that TopViewRS outperforms previous vision-language models that do not explicitly reason about spatial layout.
Critical Analysis
The TopViewRS model represents an interesting and potentially impactful approach to spatial reasoning in vision-language systems. By converting 2D images into a top-down spatial representation, the model is able to better understand and reason about the spatial arrangements of objects.
That said, the authors acknowledge some limitations of the current approach. For example, the model may struggle with complex scenes with many occluded or overlapping objects, as the top-down representation may not fully capture these nuances. Additionally, the reliance on image-caption training data could limit the model's ability to generalize to novel spatial configurations or reasoning tasks.
Further research could explore ways to improve the robustness and generalization of the top-down spatial reasoning, perhaps by incorporating additional cues or modalities beyond just 2D images and captions. [LINK: https://aimodels.fyi/papers/arxiv/spatialrgpt-grounded-spatial-reasoning-vision-language-model]Integrating 3D information[/LINK] or [LINK: https://aimodels.fyi/papers/arxiv/minds-eye-llms-visualization-thought-elicits-spatial]leveraging large language models' spatial reasoning abilities[/LINK] could be promising directions.
Overall, the TopViewRS model represents an exciting step forward in the field of vision-language reasoning, with potential applications in areas like [LINK: https://aimodels.fyi/papers/arxiv/mc-gpt-empowering-vision-language-navigation-memory]robotic navigation and scene understanding[/LINK]. As the research in this area continues to evolve, it will be interesting to see how these spatial reasoning capabilities can be further developed and applied.
Conclusion
The TopViewRS model introduced in this paper demonstrates a novel approach to spatial reasoning in vision-language systems. By converting 2D images into a top-down spatial representation, the model is able to better understand and answer questions about the spatial arrangement of objects in a scene.
While the current approach has some limitations, the underlying ideas represent an important step forward in the field of spatial reasoning for AI. As the research in this area continues to progress, we can expect to see increasingly sophisticated vision-language models that can reason about the world in more human-like ways.
Overall, the TopViewRS model is a promising development that could have significant implications for a wide range of applications, from [LINK: https://aimodels.fyi/papers/arxiv/towards-top-down-reasoning-explainable-multi-agent]robotic navigation[/LINK] to [LINK: https://aimodels.fyi/papers/arxiv/learning-to-localize-objects-improves-spatial-reasoning]object localization[/LINK]. As the field of AI continues to advance, we can expect to see more innovative approaches to spatial reasoning and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
0
0
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
6/24/2024
💬
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, Furu Wei
0
0
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as the Mind's Eye, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (VoT) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate mental images to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.
5/27/2024

SpatialRGPT: Grounded Spatial Reasoning in Vision Language Model
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, Sifei Liu
0
0
Vision Language Models (VLMs) have demonstrated remarkable performance in 2D vision and language tasks. However, their ability to reason about spatial arrangements remains limited. In this work, we introduce Spatial Region GPT (SpatialRGPT) to enhance VLMs' spatial perception and reasoning capabilities. SpatialRGPT advances VLMs' spatial understanding through two key innovations: (1) a data curation pipeline that enables effective learning of regional representation from 3D scene graphs, and (2) a flexible plugin module for integrating depth information into the visual encoder of existing VLMs. During inference, when provided with user-specified region proposals, SpatialRGPT can accurately perceive their relative directions and distances. Additionally, we propose SpatialRGBT-Bench, a benchmark with ground-truth 3D annotations encompassing indoor, outdoor, and simulated environments, for evaluating 3D spatial cognition in VLMs. Our results demonstrate that SpatialRGPT significantly enhances performance in spatial reasoning tasks, both with and without local region prompts. The model also exhibits strong generalization capabilities, effectively reasoning about complex spatial relations and functioning as a region-aware dense reward annotator for robotic tasks. Code, dataset, and benchmark will be released at https://www.anjiecheng.me/SpatialRGPT
6/21/2024
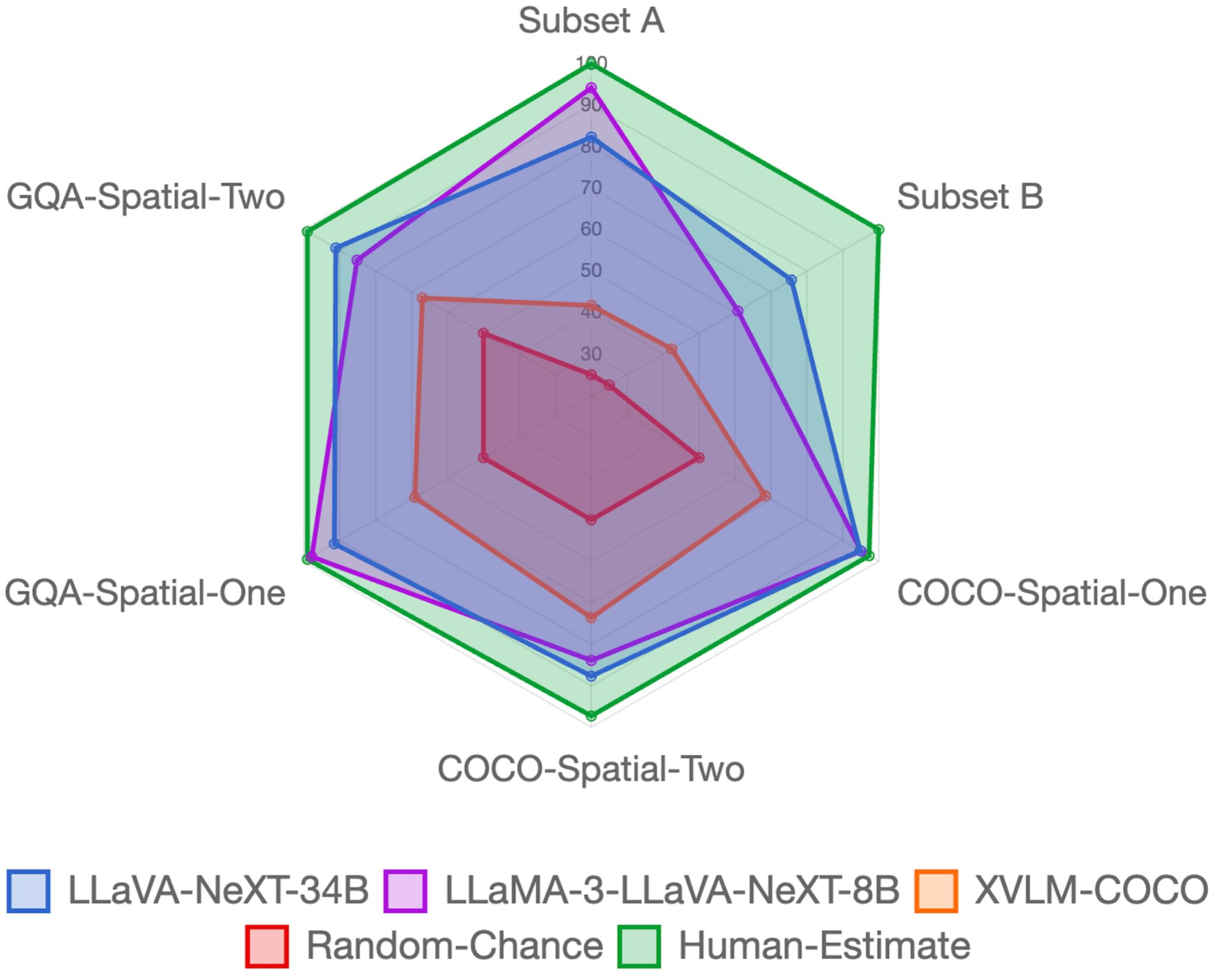
GSR-BENCH: A Benchmark for Grounded Spatial Reasoning Evaluation via Multimodal LLMs
Navid Rajabi, Jana Kosecka
0
0
The ability to understand and reason about spatial relationships between objects in images is an important component of visual reasoning. This skill rests on the ability to recognize and localize objects of interest and determine their spatial relation. Early vision and language models (VLMs) have been shown to struggle to recognize spatial relations. We extend the previously released What'sUp dataset and propose a novel comprehensive evaluation for spatial relationship understanding that highlights the strengths and weaknesses of 27 different models. In addition to the VLMs evaluated in What'sUp, our extensive evaluation encompasses 3 classes of Multimodal LLMs (MLLMs) that vary in their parameter sizes (ranging from 7B to 110B), training/instruction-tuning methods, and visual resolution to benchmark their performances and scrutinize the scaling laws in this task.
6/21/2024