GeoSEE: Regional Socio-Economic Estimation With a Large Language Model
2406.09799
0
0
Abstract
Moving beyond traditional surveys, combining heterogeneous data sources with AI-driven inference models brings new opportunities to measure socio-economic conditions, such as poverty and population, over expansive geographic areas. The current research presents GeoSEE, a method that can estimate various socio-economic indicators using a unified pipeline powered by a large language model (LLM). Presented with a diverse set of information modules, including those pre-constructed from satellite imagery, GeoSEE selects which modules to use in estimation, for each indicator and country. This selection is guided by the LLM's prior socio-geographic knowledge, which functions similarly to the insights of a domain expert. The system then computes target indicators via in-context learning after aggregating results from selected modules in the format of natural language-based texts. Comprehensive evaluation across countries at various stages of development reveals that our method outperforms other predictive models in both unsupervised and low-shot contexts. This reliable performance under data-scarce setting in under-developed or developing countries, combined with its cost-effectiveness, underscores its potential to continuously support and monitor the progress of Sustainable Development Goals, such as poverty alleviation and equitable growth, on a global scale.
Create account to get full access
Overview
- This paper presents GeoSEE, a model that uses a large language model to estimate socioeconomic indicators for different regions based on textual data.
- The researchers show that GeoSEE can provide accurate socioeconomic estimates at the regional level, which could be useful for tasks like targeting aid or understanding regional biases.
- The paper also discusses potential biases in large language models and the importance of considering geographic and socioeconomic factors when using these models.
Plain English Explanation
The researchers developed a model called GeoSEE that can estimate socioeconomic indicators, like income or education levels, for different geographic regions using text data. By feeding a large language model information about a region, GeoSEE can make predictions about the likely economic and social conditions in that area.
This could be valuable for a number of applications, such as helping organizations direct resources and aid to where they're needed most, or understanding how large language models may reflect or amplify existing biases based on geography and socioeconomic status. The paper emphasizes the need to be aware of these biases when using powerful AI models like the ones that power language tools we use every day.
Technical Explanation
The GeoSEE model uses a large language model that has been fine-tuned on a dataset of text associated with various geographic regions. This allows the model to learn patterns between the language used to describe a place and the socioeconomic characteristics of that region.
When GeoSEE is given text about a new location, it can then predict the likely socioeconomic indicators for that area, such as income, education levels, or access to resources. The researchers tested GeoSEE on data from the United States and found it was able to make accurate regional-level estimates.
The paper also discusses the potential for large language models to reflect and amplify societal biases related to geography and socioeconomic status. The authors encourage further research into understanding and mitigating these biases, as the widespread use of these models could have significant social implications.
Critical Analysis
The GeoSEE research presents an interesting approach to leveraging large language models for socioeconomic estimation at a regional level. The results suggest this method could be a valuable tool for various applications.
However, the authors acknowledge important limitations and caveats. Fundamentally, the accuracy of GeoSEE's estimates depends on the biases and shortcomings inherent in the language data used to train the underlying language model. There are open questions about how to effectively debias these models and ensure they do not perpetuate or exacerbate existing inequalities.
Additionally, the paper only evaluates GeoSEE on data from the United States. Further research would be needed to understand how well the approach generalizes to other regions and contexts. There may also be ethical concerns around the use of this technology, such as potential misuse for surveillance or the exclusion of marginalized groups.
Overall, the GeoSEE research represents an important step in exploring the capabilities and limitations of large language models for socioeconomic analysis. Continued work in this area, with a strong focus on fairness and responsible development, could yield valuable insights and applications.
Conclusion
The GeoSEE paper demonstrates the potential for large language models to provide estimates of regional socioeconomic conditions based on textual data. This could enable new applications, such as targeted resource allocation or understanding geographic biases in AI systems.
However, the research also highlights the need to carefully consider the biases and limitations of these powerful language models, as their widespread use could have significant societal implications. Ongoing work to mitigate biases and ensure the responsible development of these technologies will be crucial as they become more ubiquitous.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Understanding Intrinsic Socioeconomic Biases in Large Language Models
Mina Arzaghi, Florian Carichon, Golnoosh Farnadi
0
0
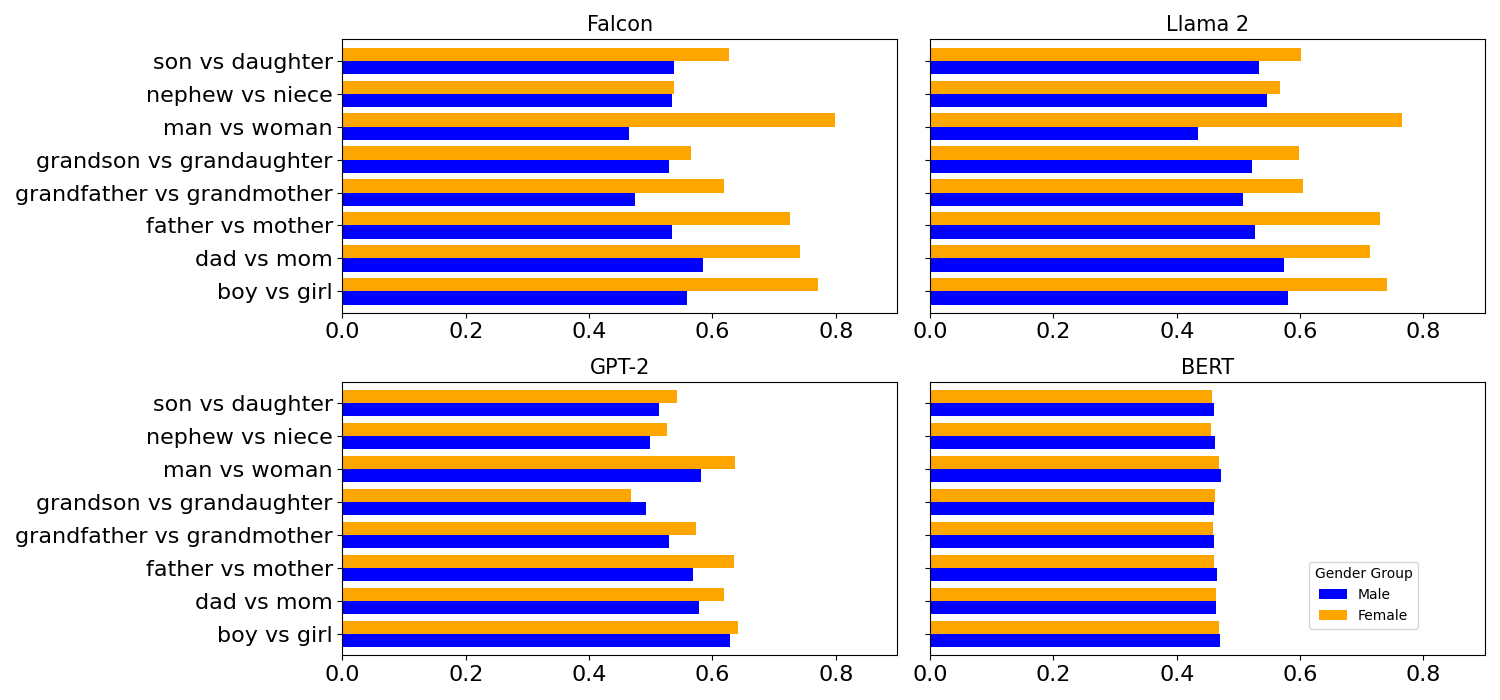
Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.
5/30/2024
Planetary Causal Inference: Implications for the Geography of Poverty
Kazuki Sakamoto, Connor T. Jerzak, Adel Daoud
0
0
Earth observation data such as satellite imagery can, when combined with machine learning, have profound impacts on our understanding of the geography of poverty through the prediction of living conditions, especially where government-derived economic indicators are either unavailable or potentially untrustworthy. Recent work has progressed in using EO data not only to predict spatial economic outcomes, but also to explore cause and effect, an understanding which is critical for downstream policy analysis. In this review, we first document the growth of interest in EO-ML analyses in the causal space. We then trace the relationship between spatial statistics and EO-ML methods before discussing the four ways in which EO data has been used in causal ML pipelines -- (1.) poverty outcome imputation for downstream causal analysis, (2.) EO image deconfounding, (3.) EO-based treatment effect heterogeneity, and (4.) EO-based transportability analysis. We conclude by providing a workflow for how researchers can incorporate EO data in causal ML analysis going forward.
6/6/2024
New!GeoReasoner: Geo-localization with Reasoning in Street Views using a Large Vision-Language Model
Ling Li, Yu Ye, Bingchuan Jiang, Wei Zeng
0
0
This work tackles the problem of geo-localization with a new paradigm using a large vision-language model (LVLM) augmented with human inference knowledge. A primary challenge here is the scarcity of data for training the LVLM - existing street-view datasets often contain numerous low-quality images lacking visual clues, and lack any reasoning inference. To address the data-quality issue, we devise a CLIP-based network to quantify the degree of street-view images being locatable, leading to the creation of a new dataset comprising highly locatable street views. To enhance reasoning inference, we integrate external knowledge obtained from real geo-localization games, tapping into valuable human inference capabilities. The data are utilized to train GeoReasoner, which undergoes fine-tuning through dedicated reasoning and location-tuning stages. Qualitative and quantitative evaluations illustrate that GeoReasoner outperforms counterpart LVLMs by more than 25% at country-level and 38% at city-level geo-localization tasks, and surpasses StreetCLIP performance while requiring fewer training resources. The data and code are available at https://github.com/lingli1996/GeoReasoner.
6/28/2024

LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
Zhiqiang Wang, Dejia Xu, Rana Muhammad Shahroz Khan, Yanbin Lin, Zhiwen Fan, Xingquan Zhu
0
0
Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
6/3/2024