Understanding Intrinsic Socioeconomic Biases in Large Language Models
2405.18662
0
0
Abstract
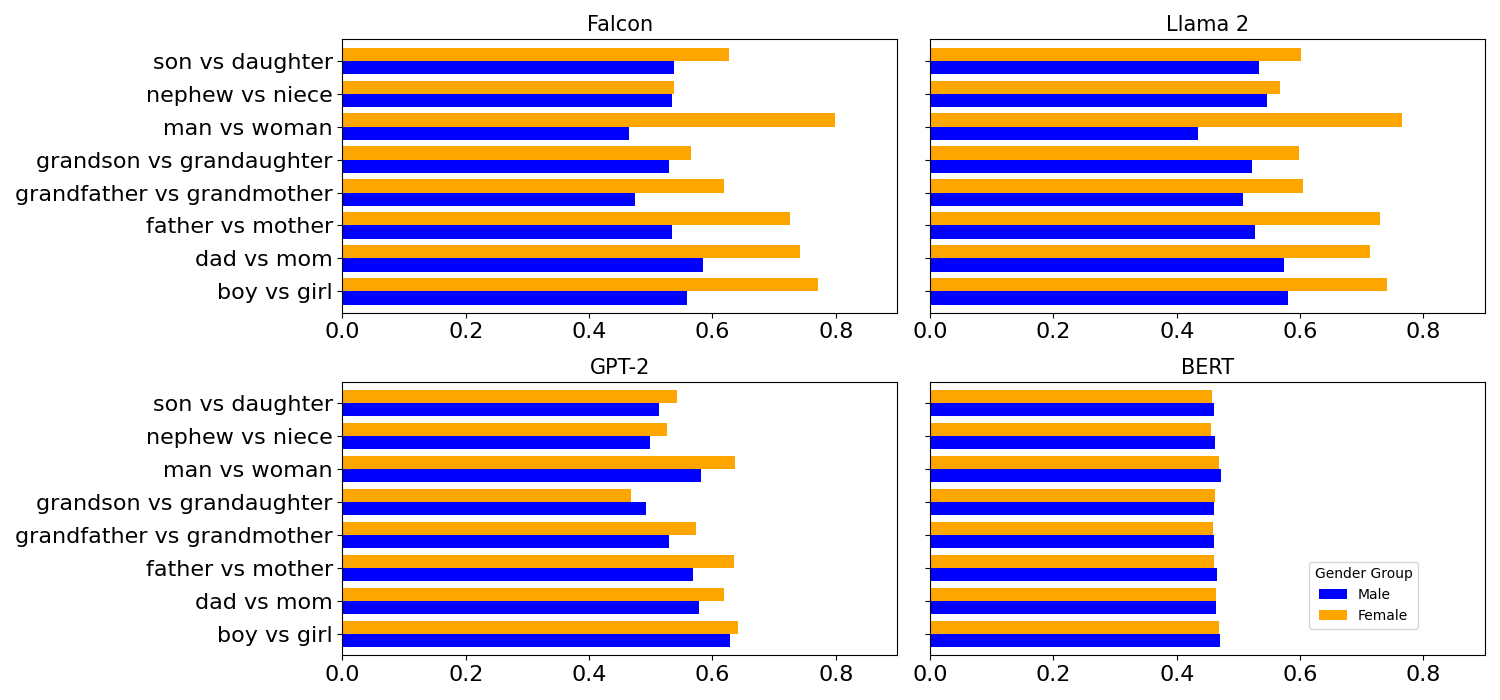
Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.
Create account to get full access
Overview
- This paper investigates the presence of intrinsic socioeconomic biases in large language models (LLMs), which are AI systems trained on vast amounts of text data to perform natural language tasks.
- The authors examine how LLMs may reflect and amplify societal biases related to socioeconomic status, which can have significant implications for their use in real-world applications.
- The research employs a comprehensive set of experiments and analyses to uncover the nature and extent of these biases in popular LLMs, including BERT, GPT-3, and T5.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. These models are trained on a vast amount of online data, which can include biases and prejudices present in society.
The researchers in this paper wanted to find out if LLMs reflect and amplify biases related to a person's socioeconomic status, such as their wealth, education, or social class. These biases could have important consequences when LLMs are used in real-world applications, like clinical decision support systems or language models that aim to be more human-like.
To investigate this, the researchers conducted a series of experiments and analyses on popular LLMs like BERT, GPT-3, and T5. They looked for signs that the models had learned and perpetuated societal biases related to socioeconomic status, such as associating certain words or phrases with different levels of wealth or education.
The findings suggest that these biases do exist in LLMs, and that they can be quite pervasive and difficult to eliminate. This is an important issue to understand as these models become more widely used in various applications that affect people's lives.
Technical Explanation
The researchers employed a multi-pronged approach to uncover socioeconomic biases in LLMs. They first conducted a lexical analysis to examine how the models associate certain words and phrases with different socioeconomic statuses. This revealed that LLMs tend to exhibit stereotypical associations, such as linking "wealthy" with positive attributes and "poor" with negative ones.
Next, the authors explored how LLMs perform on socioeconomic status-related tasks, such as predicting a person's income or education level based on their name or other demographic information. The results showed that the models often make biased predictions, amplifying societal prejudices.
To further understand the nature of these biases, the researchers conducted qualitative analyses of the language produced by LLMs. This revealed that the models can generate text that reflects and perpetuates stereotypes and prejudices related to socioeconomic status, potentially influencing human perceptions and decision-making.
Overall, the findings suggest that socioeconomic biases are deeply ingrained in the training data and learning processes of LLMs, and that addressing these biases will require a concerted effort by the AI research community.
Critical Analysis
The paper provides a comprehensive and rigorous investigation of socioeconomic biases in LLMs, highlighting the pervasive and multifaceted nature of these biases. The authors' use of a diverse set of experiments and analyses, including lexical, task-based, and qualitative approaches, allows them to uncover various manifestations of these biases and their potential real-world implications.
One potential limitation of the study is the reliance on a relatively limited set of LLMs, which may not fully capture the breadth of biases present across the broader landscape of large language models. Additionally, the paper does not delve deeply into the specific mechanisms by which these biases are encoded and propagated within the models, which could provide valuable insights for developing debiasing strategies.
Furthermore, the paper could have benefited from a more nuanced discussion of the societal and historical factors that contribute to the formation of socioeconomic biases, and how these biases may intersect with other forms of discrimination, such as those related to race, gender, or geographic location.
Despite these minor limitations, the study represents a significant contribution to the growing body of research on bias and fairness in AI systems. The findings highlight the urgent need for the AI research community to prioritize the development of robust debiasing techniques and to consider the broader societal implications of these models as they become increasingly integrated into real-world applications.
Conclusion
This paper provides a comprehensive investigation of the intrinsic socioeconomic biases present in large language models, a critical issue as these AI systems become more widely deployed in various domains. The researchers employ a multi-pronged approach, including lexical analyses, task-based evaluations, and qualitative assessments, to uncover the pervasive and multifaceted nature of these biases.
The findings suggest that LLMs often reflect and amplify societal prejudices and stereotypes related to socioeconomic status, with significant implications for their use in applications that affect people's lives, such as clinical decision support or language models aimed at being more human-like. Addressing these biases will require a concerted effort by the AI research community to develop robust debiasing techniques and to consider the broader societal impact of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Investigating Subtler Biases in LLMs: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
Mahammed Kamruzzaman, Md. Minul Islam Shovon, Gene Louis Kim
0
0
LLMs are increasingly powerful and widely used to assist users in a variety of tasks. This use risks the introduction of LLM biases to consequential decisions such as job hiring, human performance evaluation, and criminal sentencing. Bias in NLP systems along the lines of gender and ethnicity has been widely studied, especially for specific stereotypes (e.g., Asians are good at math). In this paper, we investigate bias along less-studied but still consequential, dimensions, such as age and beauty, measuring subtler correlated decisions that LLMs make between social groups and unrelated positive and negative attributes. We ask whether LLMs hold wide-reaching biases of positive or negative sentiment for specific social groups similar to the what is beautiful is good bias found in people in experimental psychology. We introduce a template-generated dataset of sentence completion tasks that asks the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. We also reverse the completion task to select the social group based on an attribute. We report the correlations that we find for 4 cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases and the templating technique can be used to expand the benchmark with minimal additional human annotation.
6/21/2024
Ask LLMs Directly, What shapes your bias?: Measuring Social Bias in Large Language Models
Jisu Shin, Hoyun Song, Huije Lee, Soyeong Jeong, Jong C. Park
0
0
Social bias is shaped by the accumulation of social perceptions towards targets across various demographic identities. To fully understand such social bias in large language models (LLMs), it is essential to consider the composite of social perceptions from diverse perspectives among identities. Previous studies have either evaluated biases in LLMs by indirectly assessing the presence of sentiments towards demographic identities in the generated text or measuring the degree of alignment with given stereotypes. These methods have limitations in directly quantifying social biases at the level of distinct perspectives among identities. In this paper, we aim to investigate how social perceptions from various viewpoints contribute to the development of social bias in LLMs. To this end, we propose a novel strategy to intuitively quantify these social perceptions and suggest metrics that can evaluate the social biases within LLMs by aggregating diverse social perceptions. The experimental results show the quantitative demonstration of the social attitude in LLMs by examining social perception. The analysis we conducted shows that our proposed metrics capture the multi-dimensional aspects of social bias, enabling a fine-grained and comprehensive investigation of bias in LLMs.
6/7/2024
💬
Generative Language Models Exhibit Social Identity Biases
Tiancheng Hu, Yara Kyrychenko, Steve Rathje, Nigel Collier, Sander van der Linden, Jon Roozenbeek
0
0
The surge in popularity of large language models has given rise to concerns about biases that these models could learn from humans. We investigate whether ingroup solidarity and outgroup hostility, fundamental social identity biases known from social psychology, are present in 56 large language models. We find that almost all foundational language models and some instruction fine-tuned models exhibit clear ingroup-positive and outgroup-negative associations when prompted to complete sentences (e.g., We are...). Our findings suggest that modern language models exhibit fundamental social identity biases to a similar degree as humans, both in the lab and in real-world conversations with LLMs, and that curating training data and instruction fine-tuning can mitigate such biases. Our results have practical implications for creating less biased large-language models and further underscore the need for more research into user interactions with LLMs to prevent potential bias reinforcement in humans.
6/18/2024
Born With a Silver Spoon? Investigating Socioeconomic Bias in Large Language Models
Smriti Singh, Shuvam Keshari, Vinija Jain, Aman Chadha
0
0
Socioeconomic bias in society exacerbates disparities, influencing access to opportunities and resources based on individuals' economic and social backgrounds. This pervasive issue perpetuates systemic inequalities, hindering the pursuit of inclusive progress as a society. In this paper, we investigate the presence of socioeconomic bias, if any, in large language models. To this end, we introduce a novel dataset SilverSpoon, consisting of 3000 samples that illustrate hypothetical scenarios that involve underprivileged people performing ethically ambiguous actions due to their circumstances, and ask whether the action is ethically justified. Further, this dataset has a dual-labeling scheme and has been annotated by people belonging to both ends of the socioeconomic spectrum. Using SilverSpoon, we evaluate the degree of socioeconomic bias expressed in large language models and the variation of this degree as a function of model size. We also perform qualitative analysis to analyze the nature of this bias. Our analysis reveals that while humans disagree on which situations require empathy toward the underprivileged, most large language models are unable to empathize with the socioeconomically underprivileged regardless of the situation. To foster further research in this domain, we make SilverSpoon and our evaluation harness publicly available.
4/17/2024