Getting More for Less: Using Weak Labels and AV-Mixup for Robust Audio-Visual Speaker Verification
2309.07115
0
0
🌿
Abstract
Distance Metric Learning (DML) has typically dominated the audio-visual speaker verification problem space, owing to strong performance in new and unseen classes. In our work, we explored multitask learning techniques to further enhance DML, and show that an auxiliary task with even weak labels can increase the quality of the learned speaker representation without increasing model complexity during inference. We also extend the Generalized End-to-End Loss (GE2E) to multimodal inputs and demonstrate that it can achieve competitive performance in an audio-visual space. Finally, we introduce AV-Mixup, a multimodal augmentation technique during training time that has shown to reduce speaker overfit. Our network achieves state of the art performance for speaker verification, reporting 0.244%, 0.252%, 0.441% Equal Error Rate (EER) on the VoxCeleb1-O/E/H test sets, which is to our knowledge, the best published results on VoxCeleb1-E and VoxCeleb1-H.
Create account to get full access
Overview
- This paper explores using multitask learning techniques to enhance Distance Metric Learning (DML) for audio-visual speaker verification.
- The authors extend the Generalized End-to-End Loss (GE2E) to work with multimodal inputs and achieve state-of-the-art performance on the VoxCeleb1 dataset.
- They also introduce a multimodal data augmentation technique called AV-Mixup that reduces speaker overfitting.
Plain English Explanation
The paper focuses on improving speaker verification, which is the task of determining if a voice belongs to a particular person. Traditional approaches have used Distance Metric Learning (DML) techniques, which work well even for new or unseen speakers.
The researchers in this work explored using multitask learning, where the model is trained not only on the main speaker verification task, but also on an auxiliary task, even if the auxiliary labels are weak. They found that this can improve the quality of the learned speaker representation without increasing the model's complexity during deployment.
Additionally, the authors extended a loss function called Generalized End-to-End Loss (GE2E) to work with both audio and visual inputs. This allowed the model to leverage information from both modalities to improve speaker verification performance.
Finally, the paper introduces a new data augmentation technique called AV-Mixup, which mixes audio and visual inputs during training. This helps reduce the model's tendency to overfit to specific speakers, improving its generalization to new speakers.
Technical Explanation
The paper starts by noting that DML has been the dominant approach for audio-visual speaker verification due to its strong performance on new and unseen speakers. The authors explore using multitask learning to further enhance DML, where the model is trained on an auxiliary task in addition to the main speaker verification task.
They demonstrate that even an auxiliary task with weak labels can improve the quality of the learned speaker representation without increasing model complexity during inference. This is an interesting finding, as it suggests that additional supervised signal, even if not directly related to the main task, can be beneficial.
The authors also extend the Generalized End-to-End Loss (GE2E) to work with multimodal (audio-visual) inputs. GE2E is a loss function designed for speaker verification that encourages embeddings of the same speaker to be close together and embeddings of different speakers to be far apart. By adapting this loss to the audio-visual domain, the model can leverage information from both modalities to improve performance.
Finally, the paper introduces a new data augmentation technique called AV-Mixup, which mixes audio and visual inputs during training. This helps reduce the model's tendency to overfit to specific speakers, improving its generalization to new speakers.
The proposed network achieves state-of-the-art performance on the VoxCeleb1 dataset, reporting the best published results on the VoxCeleb1-E and VoxCeleb1-H test sets.
Critical Analysis
The paper presents some interesting and effective techniques for improving audio-visual speaker verification, such as multitask learning, extended GE2E loss, and AV-Mixup data augmentation. However, there are a few potential limitations and areas for further research:
-
Auxiliary Task Selection: The paper does not provide much detail on how the auxiliary task was selected or designed. The choice of auxiliary task can have a significant impact on the representation learning, and further exploration in this area could be valuable.
-
Generalization to Other Domains: While the techniques demonstrated strong performance on the VoxCeleb1 dataset, it would be important to evaluate their effectiveness on other audio-visual speaker verification datasets or tasks to assess their broader applicability.
-
Computational Efficiency: The paper does not discuss the computational costs or inference times of the proposed approach compared to other methods. This information would be helpful for understanding the practical feasibility of deploying such a system in real-world applications.
-
Fairness and Bias: Audio-visual speaker verification systems can potentially exhibit demographic biases, and the paper does not address this issue. Exploring the fairness and robustness of the proposed approach across different speaker demographics would be an important future direction.
Overall, the paper presents promising techniques for enhancing audio-visual speaker verification, but further research is needed to fully understand the capabilities and limitations of the proposed methods.
Conclusion
This paper explores several innovative approaches to improve audio-visual speaker verification, including multitask learning, extended GE2E loss, and a new data augmentation technique called AV-Mixup. The authors demonstrate state-of-the-art performance on the VoxCeleb1 dataset, suggesting that these techniques can effectively leverage multimodal information to enhance speaker representation learning.
While the paper presents exciting advancements in this domain, there are still some areas for further exploration, such as the impact of auxiliary task selection, generalization to other datasets, computational efficiency, and fairness considerations. Nonetheless, the techniques introduced in this work have the potential to significantly advance the field of audio-visual speaker verification and enable more robust and accurate speaker identification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
0
0
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
6/10/2024
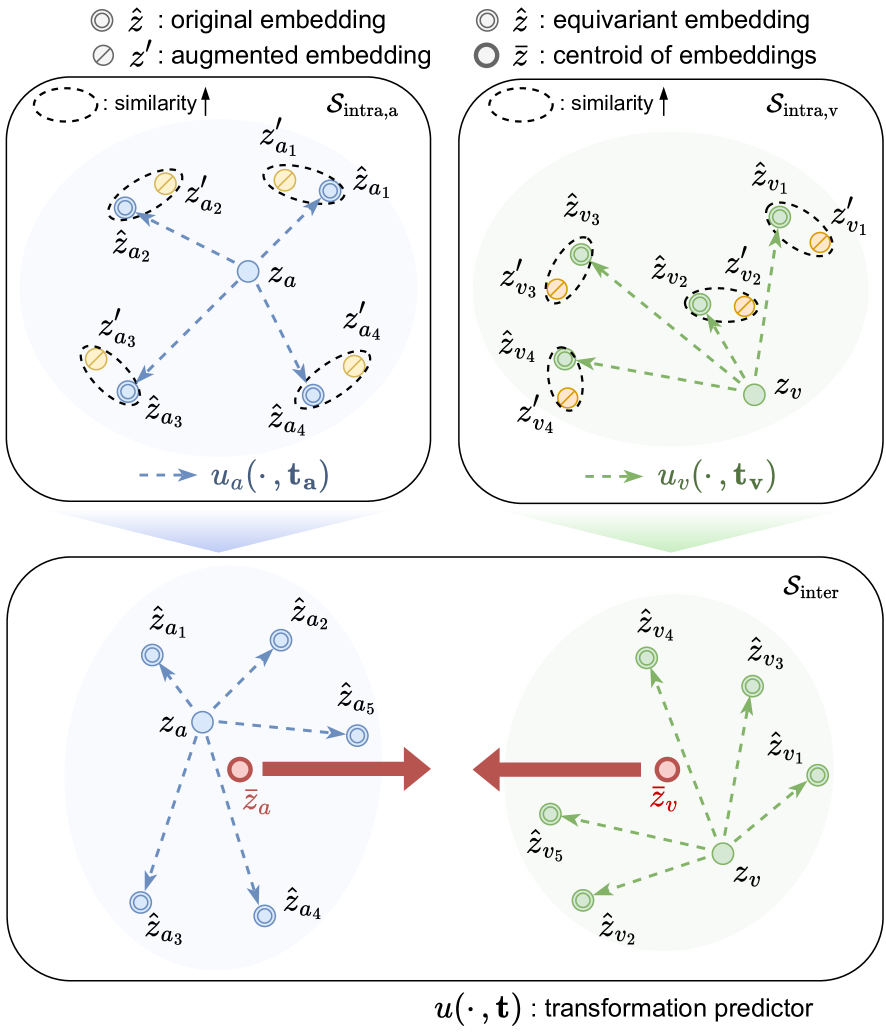
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Jongsuk Kim, Hyeongkeun Lee, Kyeongha Rho, Junmo Kim, Joon Son Chung
0
0
Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks. The code is available on https://github.com/JongSuk1/EquiAV.
6/21/2024
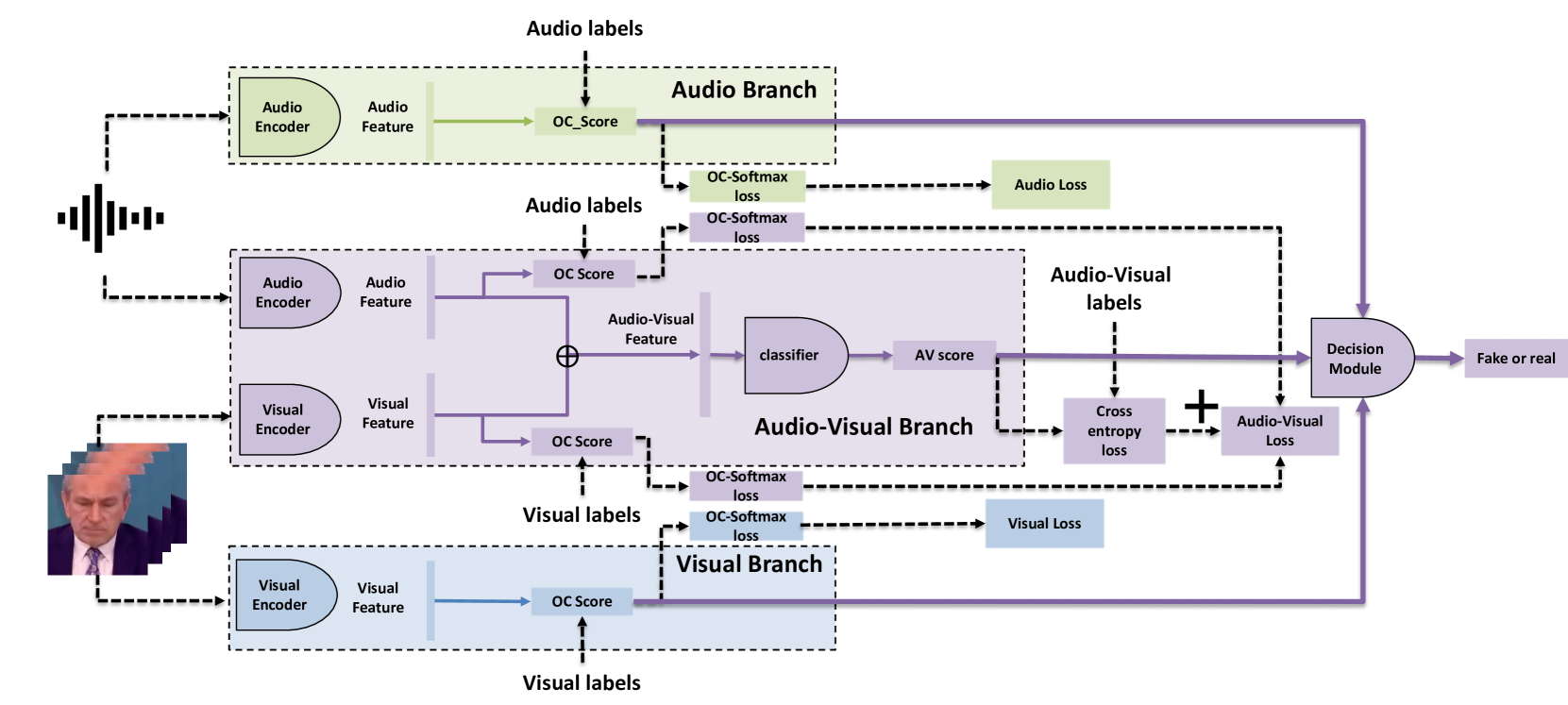
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
0
0
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
6/21/2024

AudioSetMix: Enhancing Audio-Language Datasets with LLM-Assisted Augmentations
David Xu
0
0
Multi-modal learning in the audio-language domain has seen significant advancements in recent years. However, audio-language learning faces challenges due to limited and lower-quality data compared to image-language tasks. Existing audio-language datasets are notably smaller, and manual labeling is hindered by the need to listen to entire audio clips for accurate labeling. Our method systematically generates audio-caption pairs by augmenting audio clips with natural language labels and corresponding audio signal processing operations. Leveraging a Large Language Model, we generate descriptions of augmented audio clips with a prompt template. This scalable method produces AudioSetMix, a high-quality training dataset for text-and-audio related models. Integration of our dataset improves models performance on benchmarks by providing diversified and better-aligned examples. Notably, our dataset addresses the absence of modifiers (adjectives and adverbs) in existing datasets. By enabling models to learn these concepts, and generating hard negative examples during training, we achieve state-of-the-art performance on multiple benchmarks.
6/10/2024