EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
2403.09502
0
0
Abstract
Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks. The code is available on https://github.com/JongSuk1/EquiAV.
Create account to get full access
Overview
- This paper proposes EquiAV, a novel audio-visual contrastive learning framework that leverages equivariance to learn robust and transferable representations.
- Equivariance means that transformations in one modality (e.g., audio) correspond to predictable transformations in another modality (e.g., video), which EquiAV exploits to improve cross-modal learning.
- The authors demonstrate the effectiveness of EquiAV on several audio-visual tasks, including audio-visual retrieval, audio-visual action recognition, and audio-visual speech recognition.
Plain English Explanation
The paper discusses a new way of training machine learning models to understand and connect information from audio and visual data, such as sounds and videos. The key idea is to leverage equivariance, which means that changes in one type of data (e.g., audio) correspond to predictable changes in another type of data (e.g., video).
For example, if you see a person's lips moving in a video, you can usually predict the kind of sound that will be produced. By capturing these relationships between audio and visual data, the model can learn more robust and transferable representations that perform better on a variety of tasks, like retrieving relevant videos based on audio queries, recognizing actions in videos based on audio and visual cues, and improving speech recognition by using both audio and visual information.
The authors show that their approach, called EquiAV, outperforms other state-of-the-art methods on these tasks, demonstrating the benefits of leveraging equivariance for learning better representations that can be applied to various audio-visual problems.
Technical Explanation
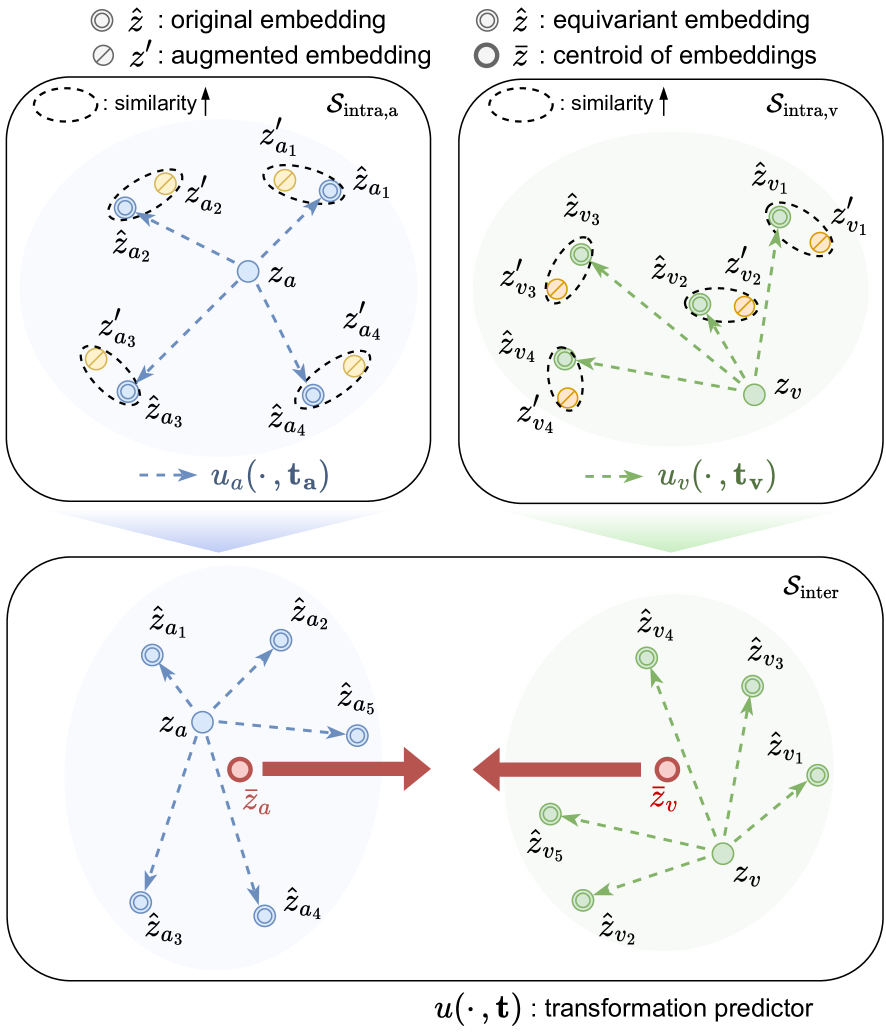
The paper introduces EquiAV, a novel audio-visual contrastive learning framework that leverages equivariance to learn robust and transferable representations. Equivariance refers to the property where transformations in one modality (e.g., audio) correspond to predictable transformations in another modality (e.g., video).
EquiAV consists of two main components: (1) an equivariant audio encoder and (2) an equivariant video encoder. The audio encoder learns representations that are equivariant to transformations like pitch shifts, time stretching, and volume changes, while the video encoder learns representations that are equivariant to transformations like spatial translations, scaling, and rotations.
The authors then use a contrastive loss to align the audio and video representations, encouraging the model to learn cross-modal correspondences. This enables EquiAV to capture the rich relationships between audio and visual data, leading to improved performance on various audio-visual tasks, such as audio-visual retrieval, audio-visual action recognition, and audio-visual speech recognition.
The authors also propose several techniques to further enhance the equivariance of the audio and video encoders, including modality alignment and counterfactual cross-modal learning.
Critical Analysis
The paper presents a compelling approach to leveraging equivariance for audio-visual contrastive learning, which leads to significant improvements on various tasks. However, the authors acknowledge several limitations and areas for future work:
-
The authors note that the equivariance properties captured by EquiAV may not fully capture all the complex relationships between audio and visual data, and there may be additional transformations or relationships that could be exploited.
-
The paper focuses on general-purpose audio-visual representations, but the authors suggest that task-specific adaptations or architectural modifications may be necessary to achieve optimal performance on certain specialized tasks.
-
The authors highlight the need for further research to understand the theoretical properties of the learned representations and how they relate to the observed performance improvements.
-
While the authors demonstrate the effectiveness of EquiAV on several datasets, more extensive evaluations on a broader range of audio-visual tasks and datasets would be valuable to further validate the generalizability of the proposed approach.
Overall, the EquiAV framework represents an important step forward in leveraging equivariance for improving audio-visual representation learning, and the authors have provided a solid foundation for continued research in this area.
Conclusion
The EquiAV paper presents a novel audio-visual contrastive learning framework that exploits equivariance to learn robust and transferable representations. By capturing the rich relationships between audio and visual data, EquiAV achieves state-of-the-art performance on various audio-visual tasks, including audio-visual retrieval, action recognition, and speech recognition.
The key contribution of EquiAV is its ability to leverage equivariance, which allows the model to learn representations that are invariant to certain transformations in one modality while being sensitive to corresponding transformations in the other modality. This equivariance property enables EquiAV to capture more meaningful cross-modal correspondences, leading to improved performance and enhanced transferability.
The authors' critical analysis highlights several areas for further research, such as exploring additional equivariance properties, adapting the framework for specialized tasks, and gaining a deeper theoretical understanding of the learned representations. Addressing these challenges could lead to even more advanced audio-visual representation learning systems with broader real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Contrastive Learning Via Equivariant Representation
Sifan Song, Jinfeng Wang, Qiaochu Zhao, Xiang Li, Dufan Wu, Angelos Stefanidis, Jionglong Su, S. Kevin Zhou, Quanzheng Li
0
0
Invariant-based Contrastive Learning (ICL) methods have achieved impressive performance across various domains. However, the absence of latent space representation for distortion (augmentation)-related information in the latent space makes ICL sub-optimal regarding training efficiency and robustness in downstream tasks. Recent studies suggest that introducing equivariance into Contrastive Learning (CL) can improve overall performance. In this paper, we rethink the roles of augmentation strategies and equivariance in improving CL efficacy. We propose a novel Equivariant-based Contrastive Learning (ECL) framework, CLeVER (Contrastive Learning Via Equivariant Representation), compatible with augmentation strategies of arbitrary complexity for various mainstream CL methods and model frameworks. Experimental results demonstrate that CLeVER effectively extracts and incorporates equivariant information from data, thereby improving the training efficiency and robustness of baseline models in downstream tasks.
6/4/2024
🌿
Getting More for Less: Using Weak Labels and AV-Mixup for Robust Audio-Visual Speaker Verification
Anith Selvakumar, Homa Fashandi
0
0
Distance Metric Learning (DML) has typically dominated the audio-visual speaker verification problem space, owing to strong performance in new and unseen classes. In our work, we explored multitask learning techniques to further enhance DML, and show that an auxiliary task with even weak labels can increase the quality of the learned speaker representation without increasing model complexity during inference. We also extend the Generalized End-to-End Loss (GE2E) to multimodal inputs and demonstrate that it can achieve competitive performance in an audio-visual space. Finally, we introduce AV-Mixup, a multimodal augmentation technique during training time that has shown to reduce speaker overfit. Our network achieves state of the art performance for speaker verification, reporting 0.244%, 0.252%, 0.441% Equal Error Rate (EER) on the VoxCeleb1-O/E/H test sets, which is to our knowledge, the best published results on VoxCeleb1-E and VoxCeleb1-H.
6/14/2024

MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
0
0
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
6/10/2024

UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Tiantian Geng, Teng Wang, Yanfu Zhang, Jinming Duan, Weili Guan, Feng Zheng
0
0
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
4/5/2024