The Ghanaian NLP Landscape: A First Look

0
➖
Sign in to get full access
Overview
- This paper provides a first look at the natural language processing (NLP) landscape in Ghana, a country in West Africa with a diverse linguistic landscape.
- The researchers examine the challenges and opportunities in developing NLP technologies for Ghanaian languages, which have historically received less attention compared to more widely spoken languages.
- The paper explores the current state of NLP research and resources for Ghanaian languages, highlighting the need for more investment and collaboration to unlock the potential of these underserved languages.
Plain English Explanation
Ghana is a country in West Africa with many different languages spoken by its people. This paper explores the current state of natural language processing (NLP) technology for these Ghanaian languages.
NLP is the field of computer science that deals with understanding and generating human language using machines. It's what powers things like translation apps, voice assistants, and text analysis tools.
However, the researchers found that Ghanaian languages have historically received less attention and investment in NLP compared to more widely spoken languages around the world. This is a common challenge faced by many Indigenous and minority languages globally.
The paper examines the current landscape of NLP resources and research for Ghanaian languages, identifying both the challenges and opportunities in this space. For example, the lack of digital text data and standardized orthographies can make it difficult to develop reliable NLP models. But the linguistic diversity of Ghana also presents a chance to advance NLP techniques that work well for different types of languages.
Overall, the researchers argue that more investment and collaboration is needed to unlock the potential of Ghanaian languages in the digital age. By supporting the development of NLP technologies tailored to these underserved languages, they hope to empower local communities and drive broader social and economic progress.
Technical Explanation
The paper first provides an overview of the linguistic landscape in Ghana, which is characterized by a diversity of over 80 languages spoken across the country. Many of these languages, such as Twi, Ga, and Dagbani, have unique grammatical structures, vocabulary, and writing systems that differ from more widely studied languages.
The researchers then discuss the current state of NLP research and resources for Ghanaian languages. They find that while there have been some isolated efforts to develop NLP tools and datasets, there is a significant lack of coordinated investment and research compared to more dominant languages. Challenges include the scarcity of digitized text data, the need for standardized orthographies, and the complexity of processing agglutinative and tonal languages.
To address these gaps, the paper proposes a research agenda focused on three key areas: 1) curating and releasing high-quality language datasets, 2) developing robust NLP models that can handle the unique properties of Ghanaian languages, and 3) fostering interdisciplinary collaborations between linguists, computer scientists, and local community stakeholders.
The authors highlight the potential benefits of advancing NLP capabilities for Ghanaian languages, such as enabling more inclusive digital services, preserving endangered languages, and unlocking new avenues for social and economic development. They also note the importance of ensuring these technologies are developed in an ethical and culturally-sensitive manner, to avoid perpetuating historical biases and power imbalances.
Critical Analysis
The paper provides a valuable first look at the Ghanaian NLP landscape, but acknowledges the limited scope of its analysis due to the scarcity of available research and resources. The researchers identify several key challenges, such as data scarcity and the complexity of Ghanaian language structures, but do not delve deeply into potential solutions or mitigation strategies.
One area that could be further explored is the role of community engagement and participatory design approaches in developing NLP technologies for Ghanaian languages. The paper briefly mentions the importance of involving local stakeholders, but more details on successful models of collaboration would be insightful.
Additionally, the paper could benefit from a more nuanced discussion of the potential risks and unintended consequences of advancing NLP in this context. For example, how can researchers ensure these technologies empower marginalized communities rather than reinforce existing power structures and inequalities?
Overall, the paper serves as an important starting point for understanding the unique challenges and opportunities in the Ghanaian NLP landscape. Further research and investment in this area could yield important insights for the broader field of Indigenous and minoritized language technologies.
Conclusion
This paper provides a first look at the natural language processing (NLP) landscape in Ghana, a country with a rich linguistic diversity that has historically received less attention in the field of NLP.
The researchers examine the current state of NLP research and resources for Ghanaian languages, highlighting the significant challenges posed by factors such as data scarcity, complex language structures, and lack of standardized orthographies. However, they also emphasize the potential benefits of advancing NLP capabilities for these underserved languages, including enabling more inclusive digital services, preserving endangered languages, and driving social and economic progress.
To unlock this potential, the paper calls for a coordinated research agenda focused on curating language datasets, developing robust NLP models, and fostering interdisciplinary collaborations. By investing in the development of NLP technologies tailored to Ghanaian languages, the researchers hope to empower local communities and contribute to the broader field of Indigenous and minoritized language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
The Ghanaian NLP Landscape: A First Look
Sheriff Issaka, Zhaoyi Zhang, Mihir Heda, Keyi Wang, Yinka Ajibola, Ryan DeMar, Xuefeng Du
Despite comprising one-third of global languages, African languages are critically underrepresented in Artificial Intelligence (AI), threatening linguistic diversity and cultural heritage. Ghanaian languages, in particular, face an alarming decline, with documented extinction and several at risk. This study pioneers a comprehensive survey of Natural Language Processing (NLP) research focused on Ghanaian languages, identifying methodologies, datasets, and techniques employed. Additionally, we create a detailed roadmap outlining challenges, best practices, and future directions, aiming to improve accessibility for researchers. This work serves as a foundational resource for Ghanaian NLP research and underscores the critical need for integrating global linguistic diversity into AI development.
Read more5/14/2024
0
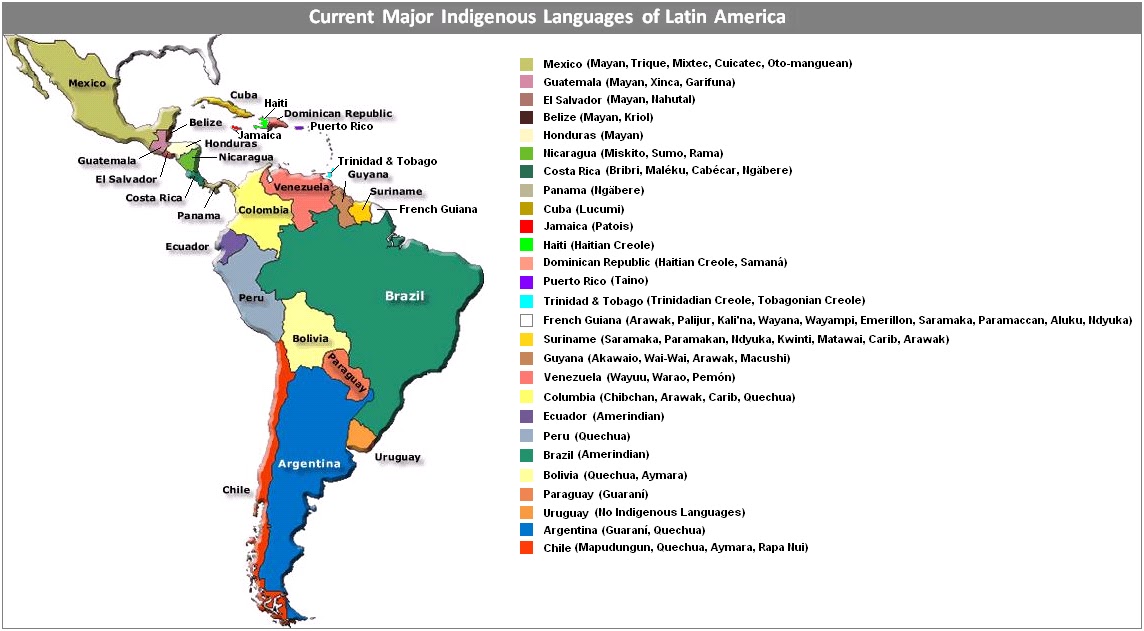
NLP Progress in Indigenous Latin American Languages
Atnafu Lambebo Tonja, Fazlourrahman Balouchzahi, Sabur Butt, Olga Kolesnikova, Hector Ceballos, Alexander Gelbukh, Thamar Solorio
The paper focuses on the marginalization of indigenous language communities in the face of rapid technological advancements. We highlight the cultural richness of these languages and the risk they face of being overlooked in the realm of Natural Language Processing (NLP). We aim to bridge the gap between these communities and researchers, emphasizing the need for inclusive technological advancements that respect indigenous community perspectives. We show the NLP progress of indigenous Latin American languages and the survey that covers the status of indigenous languages in Latin America, their representation in NLP, and the challenges and innovations required for their preservation and development. The paper contributes to the current literature in understanding the need and progress of NLP for indigenous communities of Latin America, specifically low-resource and indigenous communities in general.
Read more5/14/2024

0
Harnessing the Power of Artificial Intelligence to Vitalize Endangered Indigenous Languages: Technologies and Experiences
Claudio Pinhanez, Paulo Cavalin, Luciana Storto, Thomas Finbow, Alexander Cobbinah, Julio Nogima, Marisa Vasconcelos, Pedro Domingues, Priscila de Souza Mizukami, Nicole Grell, Majo'i Gongora, Isabel Gonc{c}alves
Since 2022 we have been exploring application areas and technologies in which Artificial Intelligence (AI) and modern Natural Language Processing (NLP), such as Large Language Models (LLMs), can be employed to foster the usage and facilitate the documentation of Indigenous languages which are in danger of disappearing. We start by discussing the decreasing diversity of languages in the world and how working with Indigenous languages poses unique ethical challenges for AI and NLP. To address those challenges, we propose an alternative development AI cycle based on community engagement and usage. Then, we report encouraging results in the development of high-quality machine learning translators for Indigenous languages by fine-tuning state-of-the-art (SOTA) translators with tiny amounts of data and discuss how to avoid some common pitfalls in the process. We also present prototypes we have built in projects done in 2023 and 2024 with Indigenous communities in Brazil, aimed at facilitating writing, and discuss the development of Indigenous Language Models (ILMs) as a replicable and scalable way to create spell-checkers, next-word predictors, and similar tools. Finally, we discuss how we envision a future for language documentation where dying languages are preserved as interactive language models.
Read more7/30/2024

0
NLP for The Greek Language: A Longer Survey
Katerina Papantoniou, Yannis Tzitzikas
English language is in the spotlight of the Natural Language Processing (NLP) community with other languages, like Greek, lagging behind in terms of offered methods, tools and resources. Due to the increasing interest in NLP, in this paper we try to condense research efforts for the automatic processing of Greek language covering the last three decades. In particular, we list and briefly discuss related works, resources and tools, categorized according to various processing layers and contexts. We are not restricted to the modern form of Greek language but also cover Ancient Greek and various Greek dialects. This survey can be useful for researchers and students interested in NLP tasks, Information Retrieval and Knowledge Management for the Greek language.
Read more8/21/2024