GHQ: Grouped Hybrid Q Learning for Heterogeneous Cooperative Multi-agent Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Previous deep multi-agent reinforcement learning (MARL) algorithms have achieved impressive results, typically in homogeneous scenarios.
- Heterogeneous scenarios are also very common and usually harder to solve.
- This paper discusses cooperative heterogeneous MARL problems in the Starcraft Multi-Agent Challenges (SMAC) environment.
- The paper defines and describes the heterogeneous problems in SMAC, creates new maps to reveal and study the problem, and proposes two novel algorithms to address the issues.
Plain English Explanation
Reinforcement learning is a type of machine learning where software agents take actions in an environment to maximize some reward. When multiple agents work together, this is called multi-agent reinforcement learning (MARL). Previous MARL algorithms have done well in scenarios where all the agents are similar. However, real-world problems often involve a mix of different types of agents, which is more challenging to solve.
This paper focuses on these heterogeneous MARL problems, using the Starcraft Multi-Agent Challenges (SMAC) environment as a testbed. The researchers first define and describe the heterogeneous problems in SMAC, and create new maps to better understand the challenges.
They find that existing baseline algorithms struggle with these heterogeneous maps. To address this, they propose two new approaches:
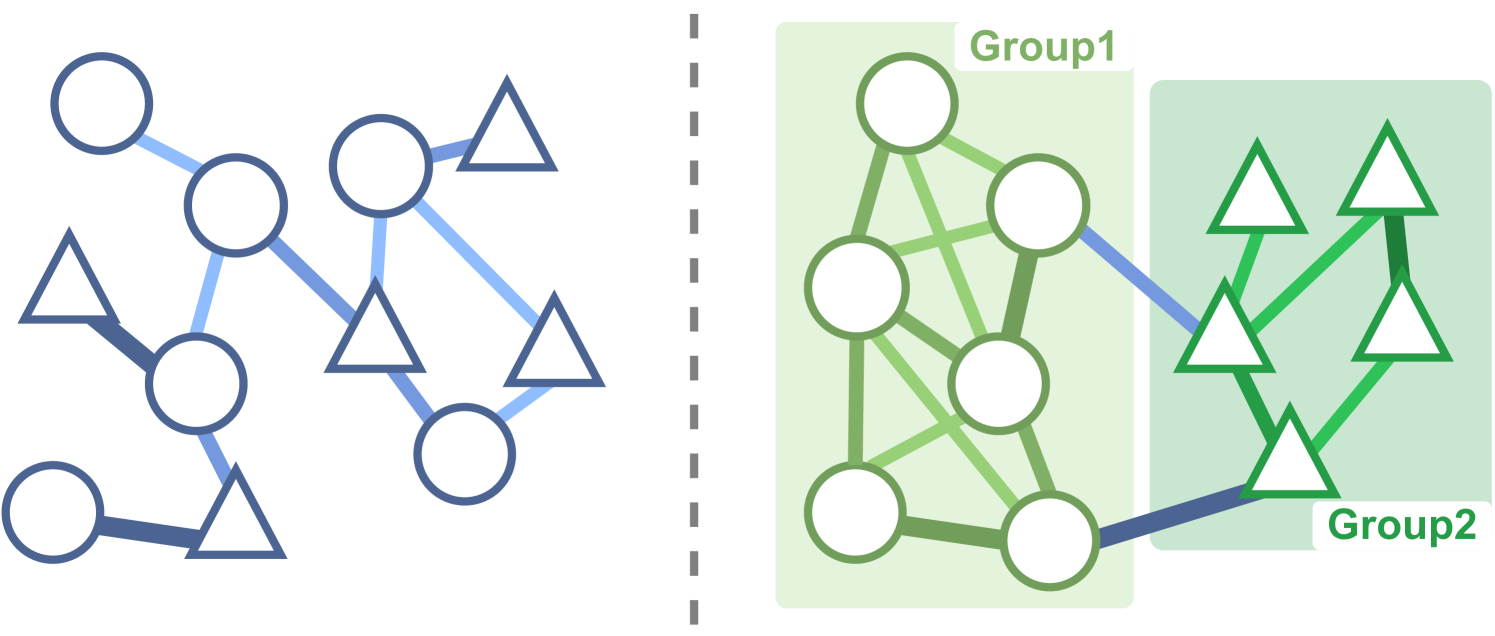
- Grouped Individual-Global-Max Consistency (GIGM): Separates agents into groups and keeps individual parameters for each group, along with a novel hybrid structure for factorization.
- Grouped Hybrid Q Learning (GHQ): Enhances coordination between groups by maximizing the Inter-group Mutual Information (IGMI) between groups' trajectories.
Experiments show that these new algorithms outperform other state-of-the-art approaches on the original and new heterogeneous SMAC maps.
Technical Explanation
The paper focuses on cooperative heterogeneous MARL problems in the SMAC environment. The researchers first define and describe the heterogeneous problems in SMAC, where agents have different capabilities and roles. To better study these challenges, they create new heterogeneous maps and find that baseline algorithms struggle to perform well on them.
To address this issue, the paper proposes two novel MARL algorithms:
- Grouped Individual-Global-Max Consistency (GIGM): This approach separates agents into groups and keeps individual parameters for each group. It also uses a novel hybrid structure for factorization, which allows for more efficient learning.
- Grouped Hybrid Q Learning (GHQ): GHQ further enhances coordination between groups by maximizing the Inter-group Mutual Information (IGMI) between groups' trajectories. This helps the groups learn to work together more effectively.
The paper evaluates these algorithms on the original and new heterogeneous SMAC maps, showing that they outperform other state-of-the-art MARL approaches.
Critical Analysis
The paper presents a thorough investigation of heterogeneous MARL problems and proposes two novel algorithms to address the challenges. The creation of new heterogeneous maps in the SMAC environment is a valuable contribution, as it helps reveal the limitations of existing methods and provides a more comprehensive testbed for evaluating solutions.
While the proposed GIGM and GHQ algorithms demonstrate impressive performance, the paper does not discuss potential limitations or areas for further research. For example, it would be interesting to understand how the grouping of agents is determined, and whether the algorithms can adapt to changes in the agent composition or capabilities during training or deployment.
Additionally, the paper could have provided more details on the specific mechanisms and intuitions behind the IGMI-based coordination in the GHQ algorithm. A deeper discussion of the tradeoffs and design choices involved in these approaches would help readers better understand the strengths and weaknesses of the proposed solutions.
Overall, the paper makes a valuable contribution by addressing an important problem in the field of MARL and introducing two novel algorithms that show promising results. Further research exploring the scalability, robustness, and broader applicability of these methods could build on this work and help advance the state of the art in cooperative heterogeneous MARL.
Conclusion
This paper tackles the challenging problem of cooperative heterogeneous MARL in the SMAC environment. The researchers define and describe the heterogeneous problems, create new maps to study them, and propose two novel algorithms (GIGM and GHQ) to address the limitations of existing approaches.
The key innovations of the paper are the use of agent grouping, individual-global-max consistency, and inter-group mutual information maximization to enhance coordination and performance in heterogeneous scenarios. Experiments show that these algorithms outperform state-of-the-art methods on both the original and new heterogeneous SMAC maps, demonstrating their effectiveness in solving these complex cooperative problems.
This work represents an important step forward in the field of MARL, as it tackles real-world challenges that are often overlooked in more homogeneous settings. The insights and techniques presented in this paper could have far-reaching implications for the development of robust and adaptable multi-agent systems in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
GHQ: Grouped Hybrid Q Learning for Heterogeneous Cooperative Multi-agent Reinforcement Learning
Xiaoyang Yu, Youfang Lin, Xiangsen Wang, Sheng Han, Kai Lv
Previous deep multi-agent reinforcement learning (MARL) algorithms have achieved impressive results, typically in homogeneous scenarios. However, heterogeneous scenarios are also very common and usually harder to solve. In this paper, we mainly discuss cooperative heterogeneous MARL problems in Starcraft Multi-Agent Challenges (SMAC) environment. We firstly define and describe the heterogeneous problems in SMAC. In order to comprehensively reveal and study the problem, we make new maps added to the original SMAC maps. We find that baseline algorithms fail to perform well in those heterogeneous maps. To address this issue, we propose the Grouped Individual-Global-Max Consistency (GIGM) and a novel MARL algorithm, Grouped Hybrid Q Learning (GHQ). GHQ separates agents into several groups and keeps individual parameters for each group, along with a novel hybrid structure for factorization. To enhance coordination between groups, we maximize the Inter-group Mutual Information (IGMI) between groups' trajectories. Experiments on original and new heterogeneous maps show the fabulous performance of GHQ compared to other state-of-the-art algorithms.
Read more8/15/2024
0
Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
Wei Duan, Jie Lu, Junyu Xuan
Cooperative Multi-Agent Reinforcement Learning (MARL) necessitates seamless collaboration among agents, often represented by an underlying relation graph. Existing methods for learning this graph primarily focus on agent-pair relations, neglecting higher-order relationships. While several approaches attempt to extend cooperation modelling to encompass behaviour similarities within groups, they commonly fall short in concurrently learning the latent graph, thereby constraining the information exchange among partially observed agents. To overcome these limitations, we present a novel approach to infer the Group-Aware Coordination Graph (GACG), which is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is further used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, we introduce a group distance loss, which promotes group cohesion and encourages specialization between groups. Our evaluations, conducted on StarCraft II micromanagement tasks, demonstrate GACG's superior performance. An ablation study further provides experimental evidence of the effectiveness of each component of our method.
Read more5/14/2024

0
Decentralized Cooperation in Heterogeneous Multi-Agent Reinforcement Learning via Graph Neural Network-Based Intrinsic Motivation
Jahir Sadik Monon, Deeparghya Dutta Barua, Md. Mosaddek Khan
Multi-agent Reinforcement Learning (MARL) is emerging as a key framework for various sequential decision-making and control tasks. Unlike their single-agent counterparts, multi-agent systems necessitate successful cooperation among the agents. The deployment of these systems in real-world scenarios often requires decentralized training, a diverse set of agents, and learning from infrequent environmental reward signals. These challenges become more pronounced under partial observability and the lack of prior knowledge about agent heterogeneity. While notable studies use intrinsic motivation (IM) to address reward sparsity or cooperation in decentralized settings, those dealing with heterogeneity typically assume centralized training, parameter sharing, and agent indexing. To overcome these limitations, we propose the CoHet algorithm, which utilizes a novel Graph Neural Network (GNN) based intrinsic motivation to facilitate the learning of heterogeneous agent policies in decentralized settings, under the challenges of partial observability and reward sparsity. Evaluation of CoHet in the Multi-agent Particle Environment (MPE) and Vectorized Multi-Agent Simulator (VMAS) benchmarks demonstrates superior performance compared to the state-of-the-art in a range of cooperative multi-agent scenarios. Our research is supplemented by an analysis of the impact of the agent dynamics model on the intrinsic motivation module, insights into the performance of different CoHet variants, and its robustness to an increasing number of heterogeneous agents.
Read more8/14/2024

0
Subgoal-based Hierarchical Reinforcement Learning for Multi-Agent Collaboration
Cheng Xu, Changtian Zhang, Yuchen Shi, Ran Wang, Shihong Duan, Yadong Wan, Xiaotong Zhang
Recent advancements in reinforcement learning have made significant impacts across various domains, yet they often struggle in complex multi-agent environments due to issues like algorithm instability, low sampling efficiency, and the challenges of exploration and dimensionality explosion. Hierarchical reinforcement learning (HRL) offers a structured approach to decompose complex tasks into simpler sub-tasks, which is promising for multi-agent settings. This paper advances the field by introducing a hierarchical architecture that autonomously generates effective subgoals without explicit constraints, enhancing both flexibility and stability in training. We propose a dynamic goal generation strategy that adapts based on environmental changes. This method significantly improves the adaptability and sample efficiency of the learning process. Furthermore, we address the critical issue of credit assignment in multi-agent systems by synergizing our hierarchical architecture with a modified QMIX network, thus improving overall strategy coordination and efficiency. Comparative experiments with mainstream reinforcement learning algorithms demonstrate the superior convergence speed and performance of our approach in both single-agent and multi-agent environments, confirming its effectiveness and flexibility in complex scenarios. Our code is open-sourced at: url{https://github.com/SICC-Group/GMAH}.
Read more8/22/2024