Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
2404.10976
0
0
Abstract
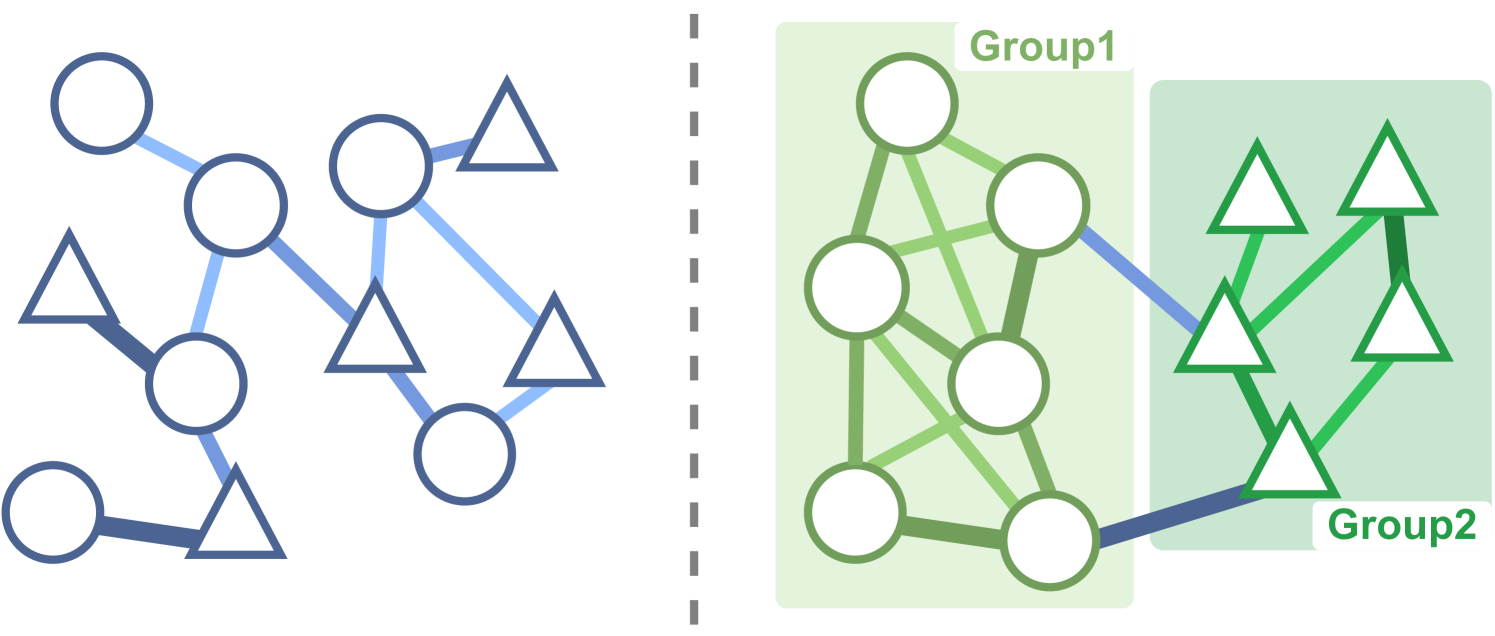
Cooperative Multi-Agent Reinforcement Learning (MARL) necessitates seamless collaboration among agents, often represented by an underlying relation graph. Existing methods for learning this graph primarily focus on agent-pair relations, neglecting higher-order relationships. While several approaches attempt to extend cooperation modelling to encompass behaviour similarities within groups, they commonly fall short in concurrently learning the latent graph, thereby constraining the information exchange among partially observed agents. To overcome these limitations, we present a novel approach to infer the Group-Aware Coordination Graph (GACG), which is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is further used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, we introduce a group distance loss, which promotes group cohesion and encourages specialization between groups. Our evaluations, conducted on StarCraft II micromanagement tasks, demonstrate GACG's superior performance. An ablation study further provides experimental evidence of the effectiveness of each component of our method.
Create account to get full access
Overview
- This paper proposes a new approach called Group-Aware Coordination Graph (GACG) for multi-agent reinforcement learning (MARL) problems.
- The key idea is to group agents based on their similarities and then use a coordination graph to capture the structured interactions between these agent groups.
- The authors demonstrate the effectiveness of GACG on several MARL benchmarks, showing that it outperforms existing MARL methods in terms of sample efficiency and final performance.
Plain English Explanation
In many real-world scenarios, such as autonomous driving or robot swarm coordination, we need to train multiple agents to work together to achieve a common goal. This is known as multi-agent reinforcement learning (MARL). However, as the number of agents increases, the complexity of the problem grows exponentially, making it challenging to train effective policies.
The authors of this paper propose a new approach called Group-Aware Coordination Graph (GACG) to address this challenge. The key idea is to group similar agents together and then use a coordination graph to capture the interactions between these agent groups. This allows the model to learn more efficient policies by focusing on the most relevant interactions, rather than trying to learn everything about all the agents at once.
Imagine you're trying to coordinate a group of friends to plan a surprise party. Rather than trying to keep track of everyone's individual preferences and schedules, it might be more efficient to group your friends into smaller clusters (e.g., college friends, work friends, family) and then figure out how the different groups need to coordinate with each other to make the party a success. The GACG approach applies a similar idea to multi-agent reinforcement learning problems.
The authors demonstrate the effectiveness of GACG on several MARL benchmarks, showing that it outperforms existing MARL methods in terms of sample efficiency and final performance. This suggests that the GACG approach could be a valuable tool for tackling complex MARL problems in the real world.
Technical Explanation
The key components of the Group-Aware Coordination Graph (GACG) approach are:
- Agent Grouping: The authors use a pre-trained embedding model to group agents based on their similarities, capturing the underlying structure of the multi-agent system.
- Coordination Graph: The authors then construct a coordination graph that represents the interactions between the agent groups, rather than individual agents. This reduces the complexity of the problem and allows the model to focus on the most relevant interactions.
- Decentralized Execution: During execution, each agent uses the coordination graph to reason about the actions of other agents in its group, as well as the actions of other groups. This enables efficient, decentralized decision-making.
The authors evaluate GACG on several MARL benchmarks, including cooperative navigation, predator-prey, and traffic junction tasks. They demonstrate that GACG outperforms existing MARL methods in terms of sample efficiency and final performance, highlighting the benefits of the group-aware approach.
Critical Analysis
The authors provide a thorough evaluation of GACG and discuss several potential limitations and directions for future research:
- Sensitivity to Grouping Quality: The performance of GACG is highly dependent on the quality of the initial agent grouping. If the grouping does not accurately capture the underlying structure of the multi-agent system, the coordination graph may not be effective.
- Scalability: While GACG scales better than traditional MARL methods, the complexity of the coordination graph still grows as the number of agent groups increases. Exploring more scalable graph structures or hierarchical approaches could be a promising direction.
- Generalization: The authors only evaluate GACG on a limited set of MARL benchmarks. Further research is needed to understand how well the approach generalizes to a wider range of real-world problems.
- Interpretability: The authors do not provide much insight into the learned coordination strategies. Improving the interpretability of the GACG model could make it more accessible to domain experts and enable better understanding of the underlying multi-agent dynamics.
Despite these potential limitations, the GACG approach represents an important step forward in addressing the challenges of MARL. By leveraging the structured interactions between agent groups, the method offers a promising path towards more efficient and scalable multi-agent learning algorithms.
Conclusion
The Group-Aware Coordination Graph (GACG) proposed in this paper offers a novel approach to multi-agent reinforcement learning (MARL) problems. By grouping similar agents and capturing their structured interactions using a coordination graph, the method is able to learn more efficient policies while maintaining decentralized execution.
The authors demonstrate the effectiveness of GACG on several MARL benchmarks, showing that it outperforms existing methods in terms of sample efficiency and final performance. This suggests that the GACG approach could be a valuable tool for tackling complex MARL problems in real-world applications, such as autonomous driving, robot coordination, and beyond.
While the paper identifies some potential limitations and areas for future research, the GACG framework represents an important contribution to the field of MARL and opens up new avenues for developing more scalable and efficient multi-agent learning algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Distributed Multi-Agent Reinforcement Learning Based on Graph-Induced Local Value Functions
Gangshan Jing, He Bai, Jemin George, Aranya Chakrabortty, Piyush K. Sharma
0
0
Achieving distributed reinforcement learning (RL) for large-scale cooperative multi-agent systems (MASs) is challenging because: (i) each agent has access to only limited information; (ii) issues on convergence or computational complexity emerge due to the curse of dimensionality. In this paper, we propose a general computationally efficient distributed framework for cooperative multi-agent reinforcement learning (MARL) by utilizing the structures of graphs involved in this problem. We introduce three coupling graphs describing three types of inter-agent couplings in MARL, namely, the state graph, the observation graph and the reward graph. By further considering a communication graph, we propose two distributed RL approaches based on local value-functions derived from the coupling graphs. The first approach is able to reduce sample complexity significantly under specific conditions on the aforementioned four graphs. The second approach provides an approximate solution and can be efficient even for problems with dense coupling graphs. Here there is a trade-off between minimizing the approximation error and reducing the computational complexity. Simulations show that our RL algorithms have a significantly improved scalability to large-scale MASs compared with centralized and consensus-based distributed RL algorithms.
4/15/2024
📈
Learning Multi-Agent Communication from Graph Modeling Perspective
Shengchao Hu, Li Shen, Ya Zhang, Dacheng Tao
0
0
In numerous artificial intelligence applications, the collaborative efforts of multiple intelligent agents are imperative for the successful attainment of target objectives. To enhance coordination among these agents, a distributed communication framework is often employed. However, information sharing among all agents proves to be resource-intensive, while the adoption of a manually pre-defined communication architecture imposes limitations on inter-agent communication, thereby constraining the potential for collaborative efforts. In this study, we introduce a novel approach wherein we conceptualize the communication architecture among agents as a learnable graph. We formulate this problem as the task of determining the communication graph while enabling the architecture parameters to update normally, thus necessitating a bi-level optimization process. Utilizing continuous relaxation of the graph representation and incorporating attention units, our proposed approach, CommFormer, efficiently optimizes the communication graph and concurrently refines architectural parameters through gradient descent in an end-to-end manner. Extensive experiments on a variety of cooperative tasks substantiate the robustness of our model across diverse cooperative scenarios, where agents are able to develop more coordinated and sophisticated strategies regardless of changes in the number of agents.
5/15/2024
LAGMA: LAtent Goal-guided Multi-Agent Reinforcement Learning
Hyungho Na, Il-chul Moon
0
0
In cooperative multi-agent reinforcement learning (MARL), agents collaborate to achieve common goals, such as defeating enemies and scoring a goal. However, learning goal-reaching paths toward such a semantic goal takes a considerable amount of time in complex tasks and the trained model often fails to find such paths. To address this, we present LAtent Goal-guided Multi-Agent reinforcement learning (LAGMA), which generates a goal-reaching trajectory in latent space and provides a latent goal-guided incentive to transitions toward this reference trajectory. LAGMA consists of three major components: (a) quantized latent space constructed via a modified VQ-VAE for efficient sample utilization, (b) goal-reaching trajectory generation via extended VQ codebook, and (c) latent goal-guided intrinsic reward generation to encourage transitions towards the sampled goal-reaching path. The proposed method is evaluated by StarCraft II with both dense and sparse reward settings and Google Research Football. Empirical results show further performance improvement over state-of-the-art baselines.
5/31/2024

Guided Cooperation in Hierarchical Reinforcement Learning via Model-based Rollout
Haoran Wang, Zeshen Tang, Leya Yang, Yaoru Sun, Fang Wang, Siyu Zhang, Yeming Chen
0
0
Goal-conditioned hierarchical reinforcement learning (HRL) presents a promising approach for enabling effective exploration in complex, long-horizon reinforcement learning (RL) tasks through temporal abstraction. Empirically, heightened inter-level communication and coordination can induce more stable and robust policy improvement in hierarchical systems. Yet, most existing goal-conditioned HRL algorithms have primarily focused on the subgoal discovery, neglecting inter-level cooperation. Here, we propose a goal-conditioned HRL framework named Guided Cooperation via Model-based Rollout (GCMR), aiming to bridge inter-layer information synchronization and cooperation by exploiting forward dynamics. Firstly, the GCMR mitigates the state-transition error within off-policy correction via model-based rollout, thereby enhancing sample efficiency. Secondly, to prevent disruption by the unseen subgoals and states, lower-level Q-function gradients are constrained using a gradient penalty with a model-inferred upper bound, leading to a more stable behavioral policy conducive to effective exploration. Thirdly, we propose a one-step rollout-based planning, using higher-level critics to guide the lower-level policy. Specifically, we estimate the value of future states of the lower-level policy using the higher-level critic function, thereby transmitting global task information downwards to avoid local pitfalls. These three critical components in GCMR are expected to facilitate inter-level cooperation significantly. Experimental results demonstrate that incorporating the proposed GCMR framework with a disentangled variant of HIGL, namely ACLG, yields more stable and robust policy improvement compared to various baselines and significantly outperforms previous state-of-the-art algorithms.
4/9/2024