GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
2406.11546
0
0

Abstract
The evolution of speech technology has been spurred by the rapid increase in dataset sizes. Traditional speech models generally depend on a large amount of labeled training data, which is scarce for low-resource languages. This paper presents GigaSpeech 2, a large-scale, multi-domain, multilingual speech recognition corpus. It is designed for low-resource languages and does not rely on paired speech and text data. GigaSpeech 2 comprises about 30,000 hours of automatically transcribed speech, including Thai, Indonesian, and Vietnamese, gathered from unlabeled YouTube videos. We also introduce an automated pipeline for data crawling, transcription, and label refinement. Specifically, this pipeline uses Whisper for initial transcription and TorchAudio for forced alignment, combined with multi-dimensional filtering for data quality assurance. A modified Noisy Student Training is developed to further refine flawed pseudo labels iteratively, thus enhancing model performance. Experimental results on our manually transcribed evaluation set and two public test sets from Common Voice and FLEURS confirm our corpus's high quality and broad applicability. Notably, ASR models trained on GigaSpeech 2 can reduce the word error rate for Thai, Indonesian, and Vietnamese on our challenging and realistic YouTube test set by 25% to 40% compared to the Whisper large-v3 model, with merely 10% model parameters. Furthermore, our ASR models trained on Gigaspeech 2 yield superior performance compared to commercial services. We believe that our newly introduced corpus and pipeline will open a new avenue for low-resource speech recognition and significantly facilitate research in this area.
Create account to get full access
Overview
- This paper presents GigaSpeech 2, a large-scale and multi-domain Automatic Speech Recognition (ASR) corpus for low-resource languages.
- The corpus is built using an automated pipeline for crawling, transcribing, and refining data from various online sources.
- The goal is to enable better ASR models for languages that lack high-quality, publicly available speech datasets.
Plain English Explanation
GigaSpeech 2 is a new dataset that aims to help create better speech recognition models for languages that don't have a lot of existing speech data. The researchers built this dataset by automatically collecting audio and text from various online sources, and then using machine learning to transcribe the audio. This allows them to build a large, diverse dataset covering many different topics and speaking styles.
The key idea is that by having more high-quality speech data available, researchers and companies can develop more accurate and robust speech recognition models for low-resource languages. This could enable better voice-based interfaces and applications for underserved communities around the world.
Technical Explanation
The GigaSpeech 2 dataset is built using an automated pipeline that crawls, transcribes, and refines speech data from various online sources. This includes audio from podcasts, audiobooks, videos, and other web content, paired with the corresponding text transcripts.
The researchers use a combination of automated transcription and human review to ensure high-quality transcripts. They also leverage techniques like efficient model compression to enable scalable transcription of large volumes of speech data.
The resulting GigaSpeech 2 dataset contains over 1,000 hours of speech data across multiple languages, domains, and speaking styles. This diversity is intended to support the development of robust, multilingual ASR models that can handle the challenges of low-resource languages.
Critical Analysis
The authors acknowledge that while GigaSpeech 2 is a significant step forward, there are still limitations and areas for improvement. For example, the automated crawling and transcription process may introduce biases or errors, which could negatively impact model performance.
Additionally, the dataset currently focuses on a relatively limited set of languages and domains. Expanding the coverage to more languages and use cases will be an important area for future work.
Nonetheless, the GigaSpeech 2 dataset represents an important contribution to the field of low-resource speech recognition. By making large-scale, high-quality speech data more accessible, the researchers are paving the way for more inclusive and capable voice-based technologies.
Conclusion
The GigaSpeech 2 dataset provides a valuable resource for developing better speech recognition models for low-resource languages. By leveraging automated techniques for data collection and transcription, the researchers have been able to create a large, diverse corpus that can support the advancement of this important field of research. While there is still work to be done, the GigaSpeech 2 dataset represents a significant step forward in enabling more inclusive and accessible voice-based technologies for underserved communities around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
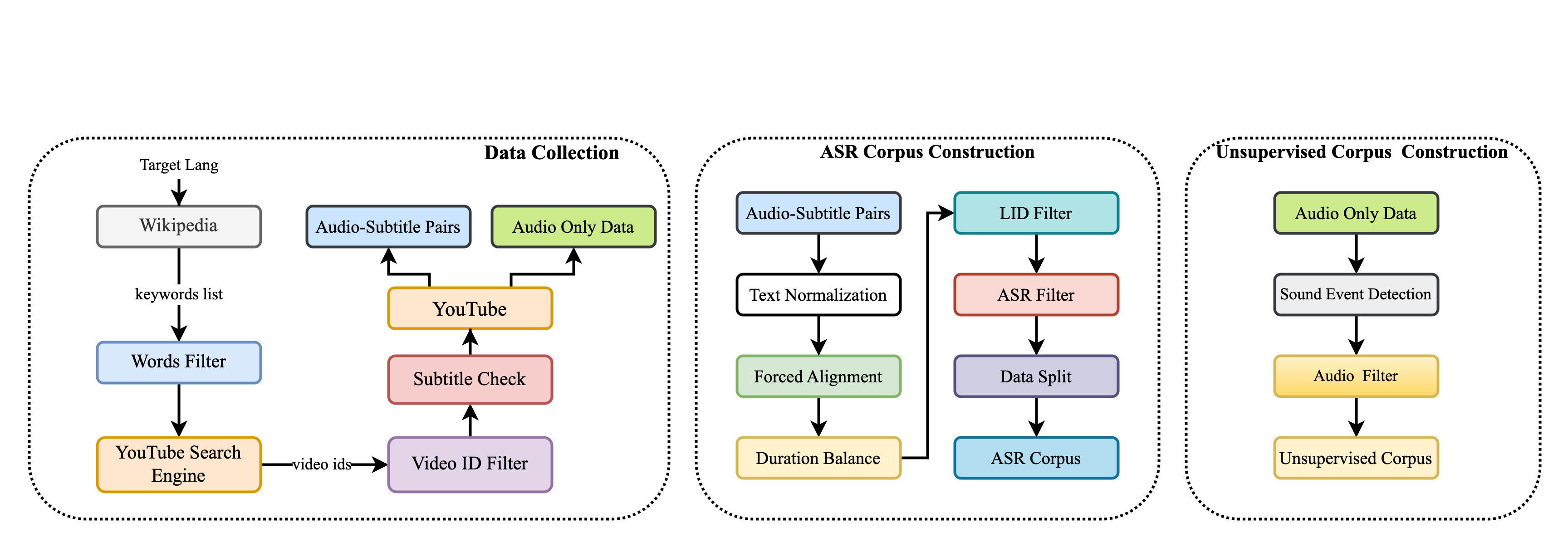
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Song Li, Yongbin You, Xuezhi Wang, Zhengkun Tian, Ke Ding, Guanglu Wan
0
0
Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
6/27/2024
🛸
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Ara Yeroyan (Data Science Department, American University of Armenia), Nikolay Karpov (Nvidia, NeMo Conversational AI team)
0
0
In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is portable to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
6/4/2024
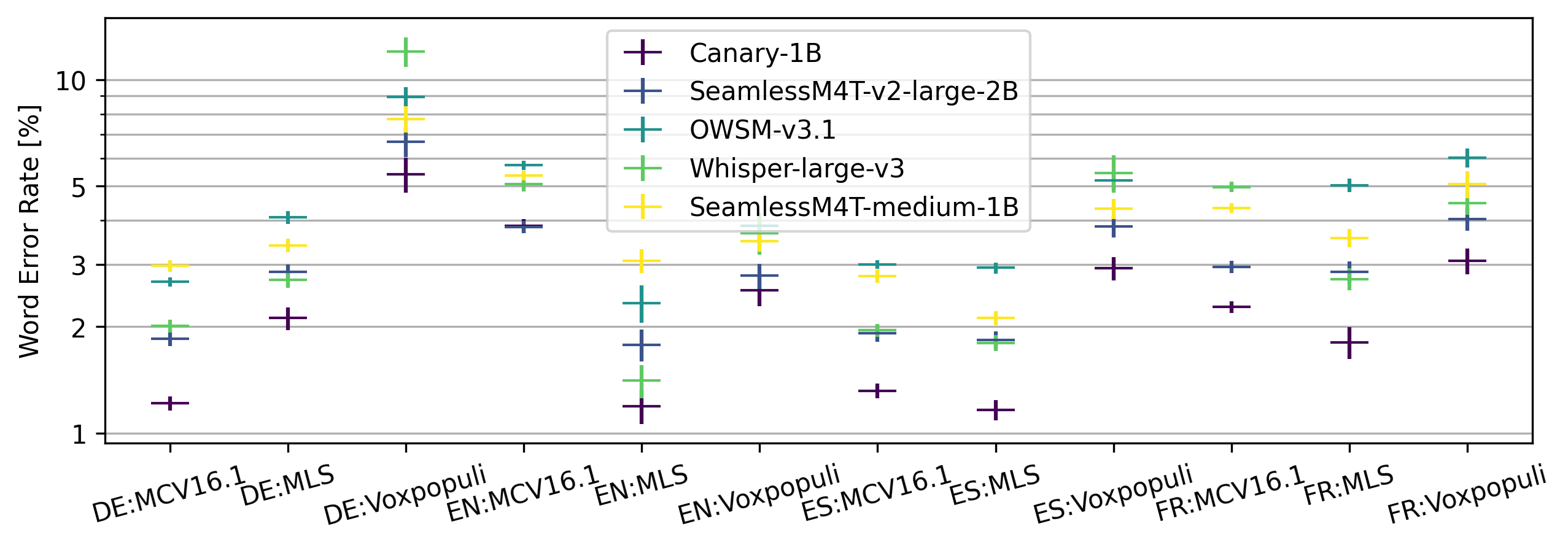
New!Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Krishna C. Puvvada, Piotr .Zelasko, He Huang, Oleksii Hrinchuk, Nithin Rao Koluguri, Kunal Dhawan, Somshubra Majumdar, Elena Rastorgueva, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
0
0
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
7/1/2024
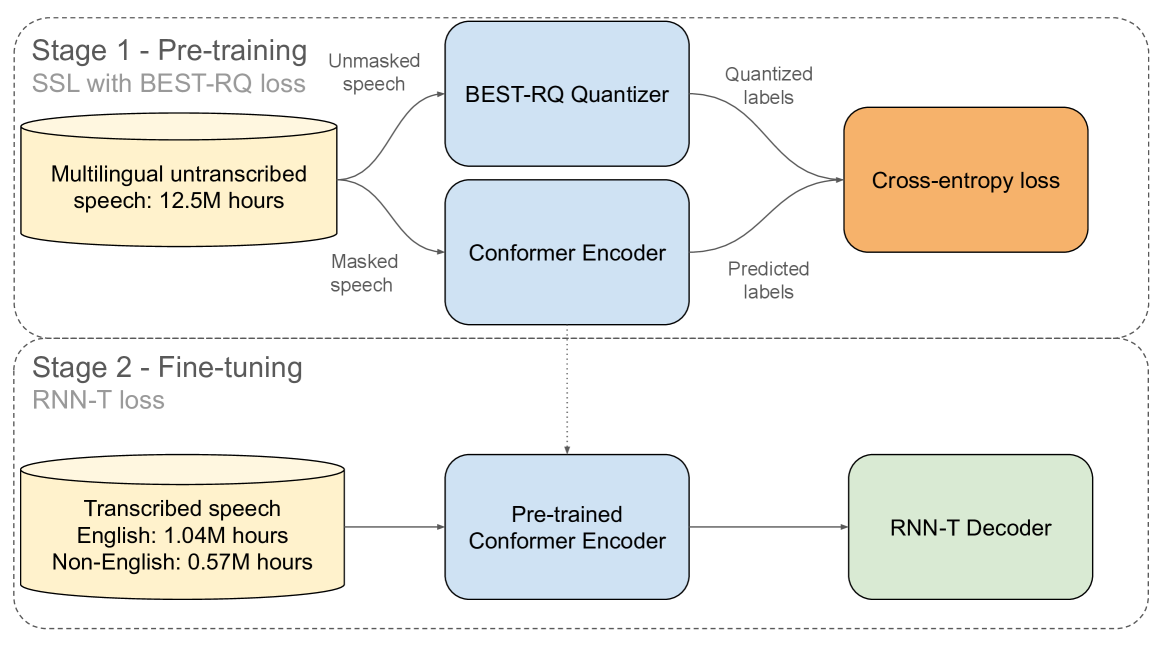
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
0
0
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
4/17/2024