GLaMM: Pixel Grounding Large Multimodal Model

0
📈
Sign in to get full access
Overview
- This paper introduces Grounding LMM (GLaMM), a novel large multimodal model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks.
- GLaMM is the first model that can densely ground objects appearing in conversations, going beyond previous region-level models that could only refer to a single object category at a time.
- To support this novel task of Grounded Conversation Generation (GCG), the authors introduce a comprehensive evaluation protocol and a large-scale densely annotated dataset called Grounding-anything Dataset (GranD).
- In addition to GCG, GLaMM also demonstrates strong performance on downstream tasks like referring expression segmentation, image and region-level captioning, and vision-language conversations.
Plain English Explanation
Connecting Language and Vision Large Multimodal Models (LMMs) are a new class of AI models that combine language understanding with visual perception. Earlier LMMs could only generate textual responses based on entire images, without grounding their language in specific visual elements. More recently, region-level LMMs were developed that could refer to individual objects, but they had limitations - they could only discuss one object at a time, required users to specify the regions of interest, or couldn't provide detailed pixel-level information about the objects.
Grounding Language in Complex Scenes In this work, the researchers present a new model called Grounding LMM (GLaMM) that can generate natural language responses that are tightly integrated with detailed object segmentation masks. This allows the model to precisely ground its language in the visual elements of a scene, discussing multiple objects and their spatial relationships. GLaMM is flexible, accepting both text and optional visual prompts as input, enabling users to interact with the model at different levels of detail.
Comprehensive Benchmarking To evaluate this new capability of "Grounded Conversation Generation" (GCG), the authors introduce a rigorous testing protocol and a large-scale dataset called Grounding-anything Dataset (GranD). GranD contains 7.5 million unique concepts grounded in 810 million different image regions, providing a comprehensive testbed for models like GLaMM. Beyond GCG, the paper also shows that GLaMM performs well on other language-vision tasks like image captioning and referring expression segmentation.
Technical Explanation
GLaMM is a large multimodal model that can generate natural language responses tightly coupled with corresponding object segmentation masks. This extends previous region-level LMMs that could only refer to a single object category at a time, required specifying regions of interest, or lacked dense pixel-level grounding.
The key innovation in GLaMM is its ability to densely ground language in complex visual scenes, discussing multiple objects and their spatial relationships. GLaMM accepts both text prompts and optional visual prompts (regions of interest) as input, allowing users to interact with the model at different levels of granularity.
To support the novel task of Grounded Conversation Generation (GCG), the authors introduce a comprehensive evaluation protocol and a large-scale dataset called Grounding-anything Dataset (GranD). GranD contains 7.5 million unique concepts grounded in a total of 810 million image regions, providing a robust testbed for GCG and other language-vision tasks.
In addition to GCG, the paper demonstrates that GLaMM also performs well on a range of downstream tasks, including referring expression segmentation, image and region-level captioning, and vision-language conversations. This showcases the versatility and strong capabilities of this new large multimodal model.
Critical Analysis
The authors have made a significant contribution by introducing GLaMM, the first model that can generate natural language responses seamlessly integrated with dense object segmentation masks. This represents an important advance in connecting language understanding with visual perception, going beyond previous region-level models with more limited grounding capabilities.
However, the paper does not address certain limitations of the approach. For example, it's unclear how GLaMM would perform on more open-ended, free-form conversation generation tasks, as the evaluation is focused on a curated set of grounded conversations. Additionally, the computational and memory requirements of the model are not discussed, which could be a concern for real-world deployment.
Further research is needed to understand the model's robustness to noisy or ambiguous inputs, as well as its ability to generalize to new visual domains and tasks beyond the ones evaluated in this paper. Exploring the model's interpretability and understanding its internal decision-making processes could also be valuable for building trust and transparency.
Conclusion
This paper presents a groundbreaking new model, GLaMM, that can generate natural language responses tightly coupled with detailed object segmentation masks. By densely grounding language in complex visual scenes, GLaMM represents a significant advancement in connecting language understanding with visual perception, going beyond the limitations of previous region-level models.
The introduction of the Grounded Conversation Generation (GCG) task and the large-scale Grounding-anything Dataset (GranD) provide a comprehensive evaluation framework for this new capability, which GLaMM demonstrates effectively. Additionally, the model's strong performance on a range of downstream language-vision tasks suggests its broad applicability and versatility.
While the paper highlights the impressive capabilities of GLaMM, further research is needed to fully understand its limitations, robustness, and potential for real-world deployment. Nonetheless, this work represents an important step forward in the quest to develop artificial intelligence systems that can seamlessly integrate language and visual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
GLaMM: Pixel Grounding Large Multimodal Model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji Mullappilly, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Erix Xing, Ming-Hsuan Yang, Fahad S. Khan
Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial LMMs used holistic images and text prompts to generate ungrounded textual responses. Recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring to a single object category at a time, require users to specify the regions, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of visually Grounded Conversation Generation (GCG), we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed GCG task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks, e.g., referring expression segmentation, image and region-level captioning and vision-language conversations.
Read more6/4/2024
0
Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model
Li Zhou, Xu Yuan, Zenghui Sun, Zikun Zhou, Jingsong Lan
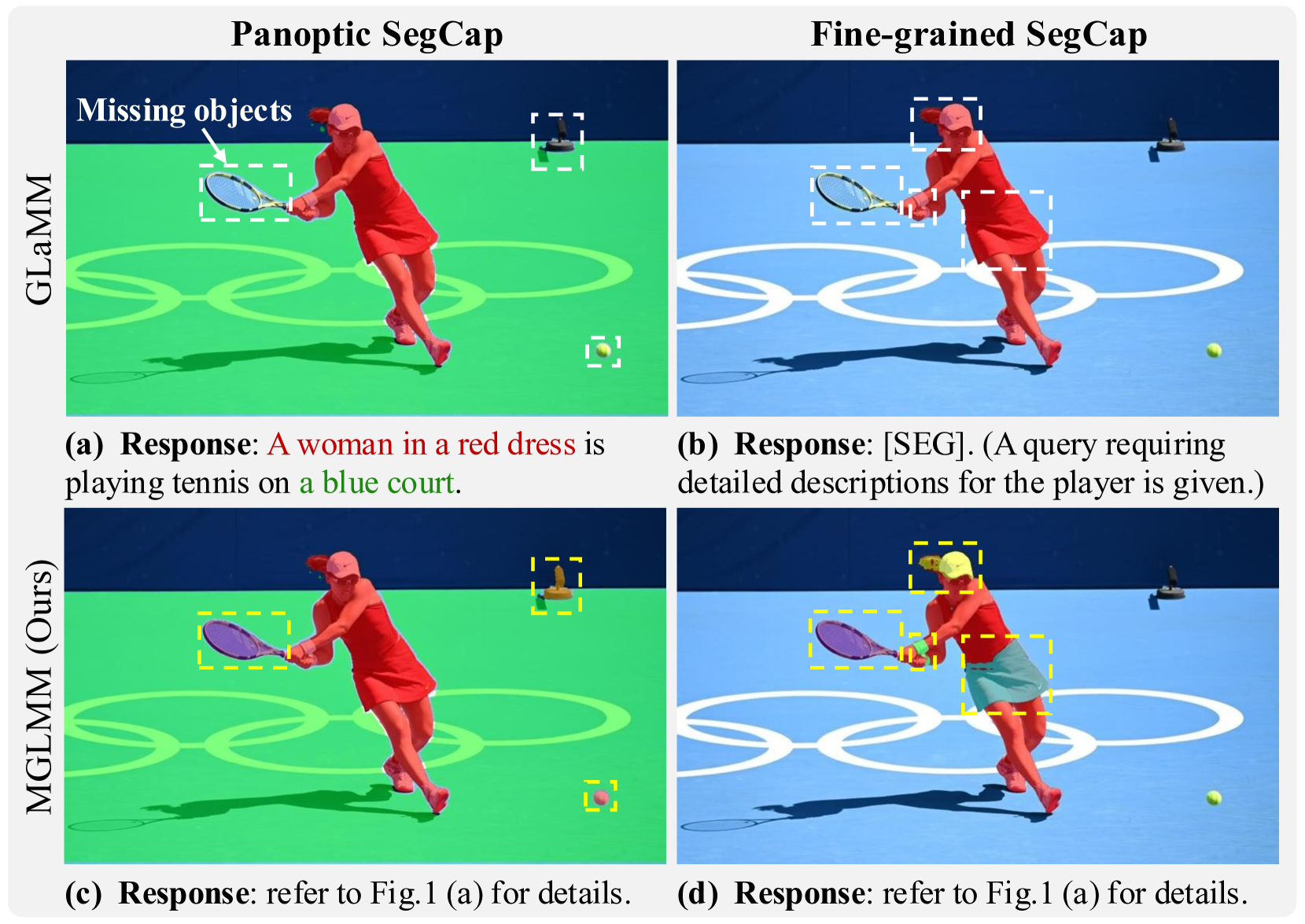
Large Multimodal Models (LMMs) have achieved significant progress by extending large language models. Building on this progress, the latest developments in LMMs demonstrate the ability to generate dense pixel-wise segmentation through the integration of segmentation models.Despite the innovations, the textual responses and segmentation masks of existing works remain at the instance level, showing limited ability to perform fine-grained understanding and segmentation even provided with detailed textual cues.To overcome this limitation, we introduce a Multi-Granularity Large Multimodal Model (MGLMM), which is capable of seamlessly adjusting the granularity of Segmentation and Captioning (SegCap) following user instructions, from panoptic SegCap to fine-grained SegCap. We name such a new task Multi-Granularity Segmentation and Captioning (MGSC). Observing the lack of a benchmark for model training and evaluation over the MGSC task, we establish a benchmark with aligned masks and captions in multi-granularity using our customized automated annotation pipeline. This benchmark comprises 10K images and more than 30K image-question pairs. We will release our dataset along with the implementation of our automated dataset annotation pipeline for further research.Besides, we propose a novel unified SegCap data format to unify heterogeneous segmentation datasets; it effectively facilitates learning to associate object concepts with visual features during multi-task training. Extensive experiments demonstrate that our MGLMM excels at tackling more than eight downstream tasks and achieves state-of-the-art performance in MGSC, GCG, image captioning, referring segmentation, multiple and empty segmentation, and reasoning segmentation tasks. The great performance and versatility of MGLMM underscore its potential impact on advancing multimodal research.
Read more9/23/2024

0
F-LMM: Grounding Frozen Large Multimodal Models
Size Wu, Sheng Jin, Wenwei Zhang, Lumin Xu, Wentao Liu, Wei Li, Chen Change Loy
Endowing Large Multimodal Models (LMMs) with visual grounding capability can significantly enhance AIs' understanding of the visual world and their interaction with humans. However, existing methods typically fine-tune the parameters of LMMs to learn additional segmentation tokens and overfit grounding and segmentation datasets. Such a design would inevitably cause a catastrophic diminution in the indispensable conversational capability of general AI assistants. In this paper, we comprehensively evaluate state-of-the-art grounding LMMs across a suite of multimodal question-answering benchmarks, observing pronounced performance drops that indicate vanishing general knowledge comprehension and weakened instruction following ability. To address this issue, we present F-LMM -- grounding frozen off-the-shelf LMMs in human-AI conversations -- a straightforward yet effective design based on the fact that word-pixel correspondences conducive to visual grounding inherently exist in the attention weights of well-trained LMMs. Using only a few trainable CNN layers, we can translate word-pixel attention weights to mask logits, which a SAM-based mask refiner can further optimise. Our F-LMM neither learns special segmentation tokens nor utilises high-quality grounded instruction-tuning data, but achieves competitive performance on referring expression segmentation and panoptic narrative grounding benchmarks while completely preserving LMMs' original conversational ability. Additionally, with instruction-following ability preserved and grounding ability obtained, our F-LMM can perform visual chain-of-thought reasoning and better resist object hallucinations.
Read more6/11/2024

0
LLM-Optic: Unveiling the Capabilities of Large Language Models for Universal Visual Grounding
Haoyu Zhao, Wenhang Ge, Ying-cong Chen
Visual grounding is an essential tool that links user-provided text queries with query-specific regions within an image. Despite advancements in visual grounding models, their ability to comprehend complex queries remains limited. To overcome this limitation, we introduce LLM-Optic, an innovative method that utilizes Large Language Models (LLMs) as an optical lens to enhance existing visual grounding models in comprehending complex text queries involving intricate text structures, multiple objects, or object spatial relationships, situations that current models struggle with. LLM-Optic first employs an LLM as a Text Grounder to interpret complex text queries and accurately identify objects the user intends to locate. Then a pre-trained visual grounding model is used to generate candidate bounding boxes given the refined query by the Text Grounder. After that, LLM-Optic annotates the candidate bounding boxes with numerical marks to establish a connection between text and specific image regions, thereby linking two distinct modalities. Finally, it employs a Large Multimodal Model (LMM) as a Visual Grounder to select the marked candidate objects that best correspond to the original text query. Through LLM-Optic, we have achieved universal visual grounding, which allows for the detection of arbitrary objects specified by arbitrary human language input. Importantly, our method achieves this enhancement without requiring additional training or fine-tuning. Extensive experiments across various challenging benchmarks demonstrate that LLM-Optic achieves state-of-the-art zero-shot visual grounding capabilities. Project Page: https://haoyu-zhao.github.io/LLM-Optic.github.io/.
Read more5/29/2024