Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
2401.10711
0
1

Abstract
Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently, by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we first fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments and pseudo-labels, with the visual-language alignment capability of the CLIP models. With these pseudo-labeled keyframes as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
Create account to get full access
Overview
- This paper explores a weakly supervised Gaussian contrastive grounding approach using large multimodal models (LMMs) for video question answering.
- The goal is to enable LMMs to ground textual knowledge to relevant video regions without requiring strong supervision.
- The authors propose a Gaussian contrastive loss that encourages the model to align text embeddings with the most relevant visual regions in a video.
- Experiments on several video question answering benchmarks show the effectiveness of this weakly supervised approach compared to prior methods.
Plain English Explanation
The paper is about using large multimodal models (LMMs) - models that can process both text and visual information - for answering questions about videos. Typically, these models require a lot of labeled data that shows exactly which parts of the video are relevant to answering each question.
The researchers in this paper found a way to train the LMMs without needing all that labeled data. Instead, they used a "weakly supervised" approach, which means the model learns to connect the text and video on its own, without being explicitly told the right connections.
The key idea is to use a "Gaussian contrastive loss" - this encourages the model to align the text embeddings (numerical representations of the text) with the most relevant visual regions in the video. So the model learns to associate the question text with the important parts of the video, even without being told which parts are important.
The experiments show this weakly supervised approach performs better than previous methods that required more labeled data. This is significant because collecting all that labeled data is time-consuming and expensive. This new approach makes it easier to use powerful LMMs for video question answering.
Technical Explanation
The paper introduces a weakly supervised Gaussian contrastive grounding (WSGCG) approach for training large multimodal models (LMMs) on video question answering tasks. LMMs like those explored in other papers have shown strong performance, but typically require extensive manual annotations linking textual queries to relevant video regions.
To address this, the authors propose a Gaussian contrastive loss that encourages the LMM to align text embeddings with the most relevant visual regions, without needing explicit ground truth annotations. The intuition is that by minimizing the distance between text and the most similar visual features, while maximizing the distance to less relevant regions, the model can learn effective text-video grounding in a weakly supervised manner.
Experiments are conducted on several video question answering benchmarks, including MOREVQA, How2QA, and TGIF-QA. The authors show their WSGCG approach outperforms prior weakly supervised methods, and can even rival the performance of fully supervised techniques on certain tasks.
Critical Analysis
A key strength of this work is the ability to train powerful LMMs for video question answering without requiring expensive, labor-intensive annotation of ground truth video-text alignments. This makes the models more scalable and accessible, potentially enabling their use in a wider range of applications.
However, the paper does not address the potential limitations of this weakly supervised approach. For example, it's unclear how well the model would perform on more complex reasoning tasks that may require more precise grounding of language to visual elements. Additionally, the evaluation is limited to existing benchmarks, and further research would be needed to assess real-world performance and robustness.
It would also be valuable to better understand the failure modes of the WSGCG approach, and whether there are certain types of questions or videos where it struggles compared to fully supervised methods. Further research exploring diverse methods for video question answering could help provide a more comprehensive understanding of the strengths and weaknesses of this technique.
Conclusion
This paper presents a novel weakly supervised Gaussian contrastive grounding approach for training large multimodal models on video question answering tasks. By eliminating the need for extensive manual annotations, the authors demonstrate that these powerful models can be applied more broadly and efficiently.
The results show the effectiveness of this technique compared to prior weakly supervised methods, and even suggest it can rival the performance of fully supervised approaches in certain scenarios. This is an important step towards making advanced video understanding models more accessible and scalable.
While there are still open questions and potential limitations to explore, this work represents a valuable contribution to the field of multimodal learning and its application to real-world tasks like video question answering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
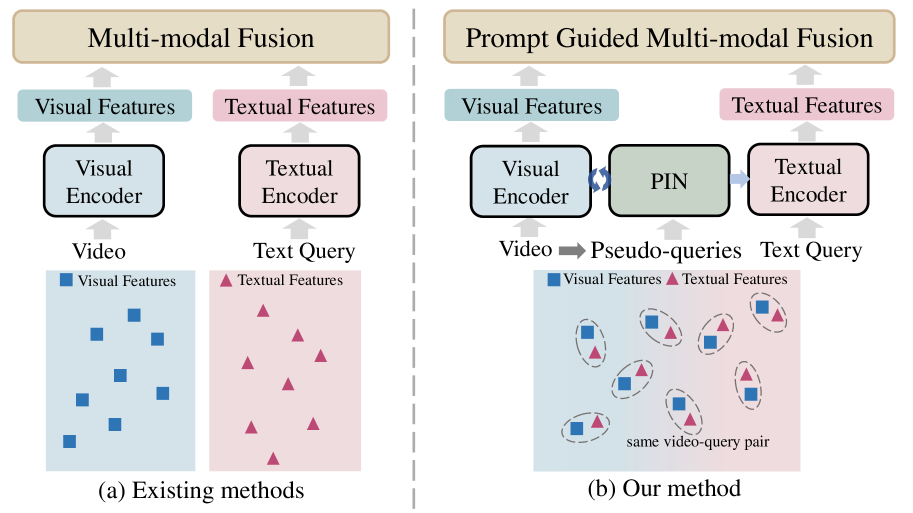
Video sentence grounding with temporally global textual knowledge
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
0
0
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
6/4/2024
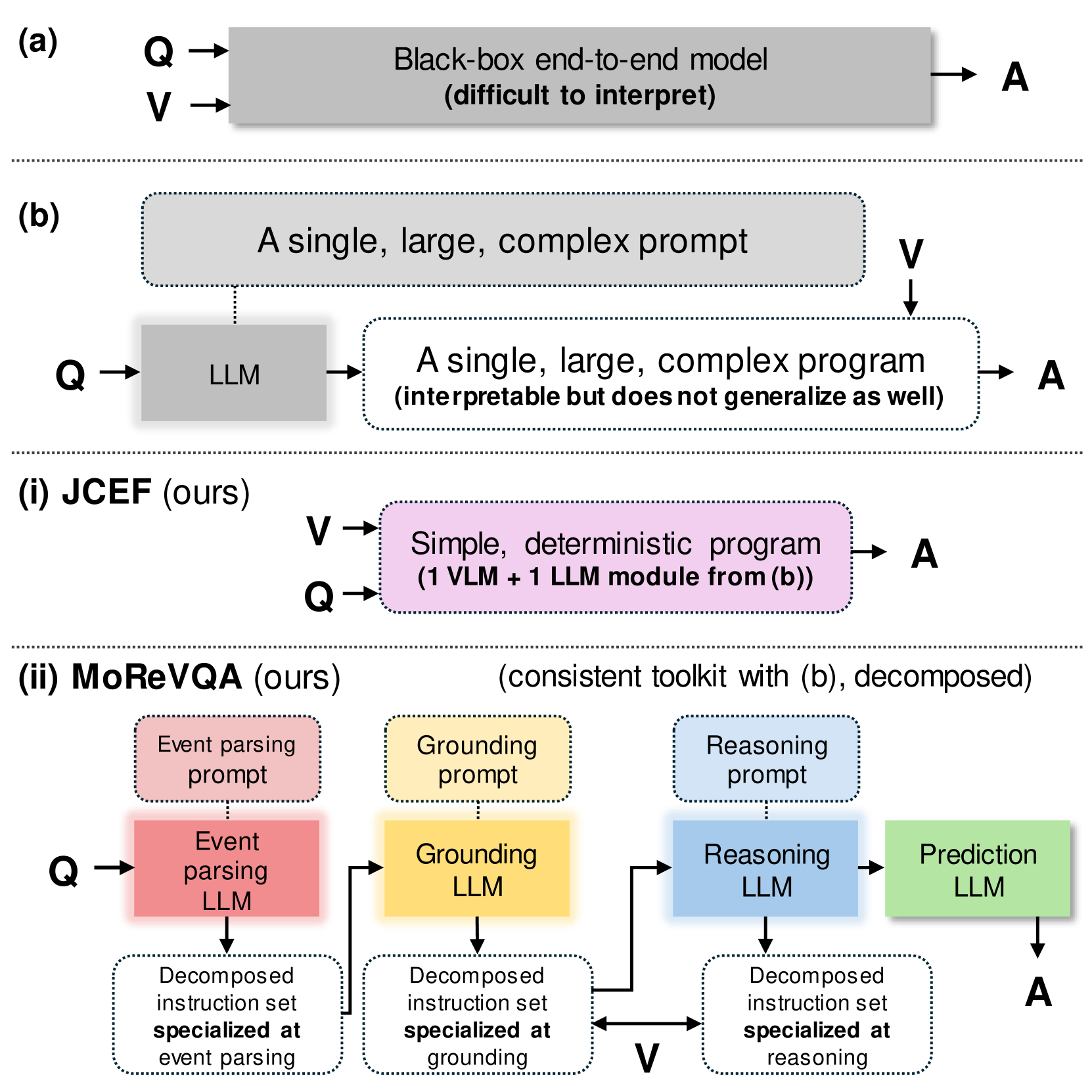
MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, Cordelia Schmid
0
0
This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
4/10/2024

Beyond Raw Videos: Understanding Edited Videos with Large Multimodal Model
Lu Xu, Sijie Zhu, Chunyuan Li, Chia-Wen Kuo, Fan Chen, Xinyao Wang, Guang Chen, Dawei Du, Ye Yuan, Longyin Wen
0
0
The emerging video LMMs (Large Multimodal Models) have achieved significant improvements on generic video understanding in the form of VQA (Visual Question Answering), where the raw videos are captured by cameras. However, a large portion of videos in real-world applications are edited videos, textit{e.g.}, users usually cut and add effects/modifications to the raw video before publishing it on social media platforms. The edited videos usually have high view counts but they are not covered in existing benchmarks of video LMMs, textit{i.e.}, ActivityNet-QA, or VideoChatGPT benchmark. In this paper, we leverage the edited videos on a popular short video platform, textit{i.e.}, TikTok, and build a video VQA benchmark (named EditVid-QA) covering four typical editing categories, i.e., effect, funny, meme, and game. Funny and meme videos benchmark nuanced understanding and high-level reasoning, while effect and game evaluate the understanding capability of artificial design. Most of the open-source video LMMs perform poorly on the EditVid-QA benchmark, indicating a huge domain gap between edited short videos on social media and regular raw videos. To improve the generalization ability of LMMs, we collect a training set for the proposed benchmark based on both Panda-70M/WebVid raw videos and small-scale TikTok/CapCut edited videos, which boosts the performance on the proposed EditVid-QA benchmark, indicating the effectiveness of high-quality training data. We also identified a serious issue in the existing evaluation protocol using the GPT-3.5 judge, namely a sorry attack, where a sorry-style naive answer can achieve an extremely high rating from the GPT judge, e.g., over 4.3 for correctness score on VideoChatGPT evaluation protocol. To avoid the sorry attacks, we evaluate results with GPT-4 judge and keyword filtering. The datasets will be released for academic purposes only.
6/18/2024
🛸
Towards Retrieval Augmented Generation over Large Video Libraries
Yannis Tevissen, Khalil Guetari, Fr'ed'eric Petitpont
0
0
Video content creators need efficient tools to repurpose content, a task that often requires complex manual or automated searches. Crafting a new video from large video libraries remains a challenge. In this paper we introduce the task of Video Library Question Answering (VLQA) through an interoperable architecture that applies Retrieval Augmented Generation (RAG) to video libraries. We propose a system that uses large language models (LLMs) to generate search queries, retrieving relevant video moments indexed by speech and visual metadata. An answer generation module then integrates user queries with this metadata to produce responses with specific video timestamps. This approach shows promise in multimedia content retrieval, and AI-assisted video content creation.
6/24/2024