Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model

0
Sign in to get full access
Overview
- This paper presents a novel approach for instruction-guided multi-granularity segmentation and captioning using a large multimodal model.
- The proposed method enables fine-grained control over the level of detail in image segmentation and captioning tasks through textual instructions.
- The authors leverage a large multimodal model pre-trained on a diverse dataset to achieve strong performance on both segmentation and captioning tasks.
Plain English Explanation
The research paper describes a new way to analyze and describe images using both computer vision and natural language processing techniques. The key idea is to allow users to provide instructions or prompts in text form that guide the computer to segment the image into different regions and generate captions for those regions at different levels of detail.
For example, a user might provide an instruction like "Segment the image and describe the main objects in detail." The computer would then break the image into meaningful parts (like a person, a chair, a table) and generate detailed captions for each of those parts. Alternatively, the user could ask the system to "Provide a high-level summary of the image," and it would generate a more concise, overall description of the scene.
This instruction-guided, multi-granularity approach gives users more control over the analysis process and allows them to customize the level of detail to their specific needs. The researchers leverage a large multimodal model - a powerful AI system trained on a diverse dataset to handle both visual and language tasks - to achieve strong performance on these segmentation and captioning challenges.
Technical Explanation
The method proposed in this paper builds upon a large multimodal model, such as GLAMM or MG-LLaVA, that has been pre-trained on a broad range of visual and language data. The key innovation is the introduction of an instruction-guided component that allows users to provide textual prompts to control the level of detail in the segmentation and captioning outputs.
The authors design a multi-task learning framework that jointly optimizes the model for both fine-grained segmentation and multi-level captioning, leveraging the shared visual representations. They also introduce cross-modal attention mechanisms to better integrate the textual instructions with the visual processing.
The experimental results demonstrate that the proposed approach outperforms previous state-of-the-art methods on benchmark datasets for both segmentation and captioning tasks. The model is able to generate segmentation masks and captions that closely match the level of detail specified in the user instructions.
Critical Analysis
The paper presents a compelling approach that advances the state-of-the-art in multimodal vision-language tasks. The instruction-guided aspect is a particularly novel and valuable contribution, as it gives users more control and customization over the analysis process.
However, the authors acknowledge some limitations of their current work. For example, the model may struggle with complex scenes or instructions that require higher-level reasoning or commonsense understanding. Additionally, the training and evaluation are conducted on curated datasets, and the performance on more diverse, real-world data remains to be tested.
Further research could explore ways to enhance the robustness and generalization of the model, perhaps by incorporating additional training signals or architectural innovations. Investigating the model's interpretability and transparency could also be valuable, as users may want to understand the reasoning behind the generated outputs.
Conclusion
This paper presents a novel approach for instruction-guided, multi-granularity segmentation and captioning using a large multimodal model. The proposed method allows users to control the level of detail in the image analysis, enabling more customized and contextual understanding of visual content.
The strong experimental results demonstrate the effectiveness of this approach and its potential to enhance a wide range of real-world applications, from assistive technology to content creation and retrieval. As the field of multimodal AI continues to advance, this work represents an important step towards more intuitive and user-centric visual understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model
Li Zhou, Xu Yuan, Zenghui Sun, Zikun Zhou, Jingsong Lan
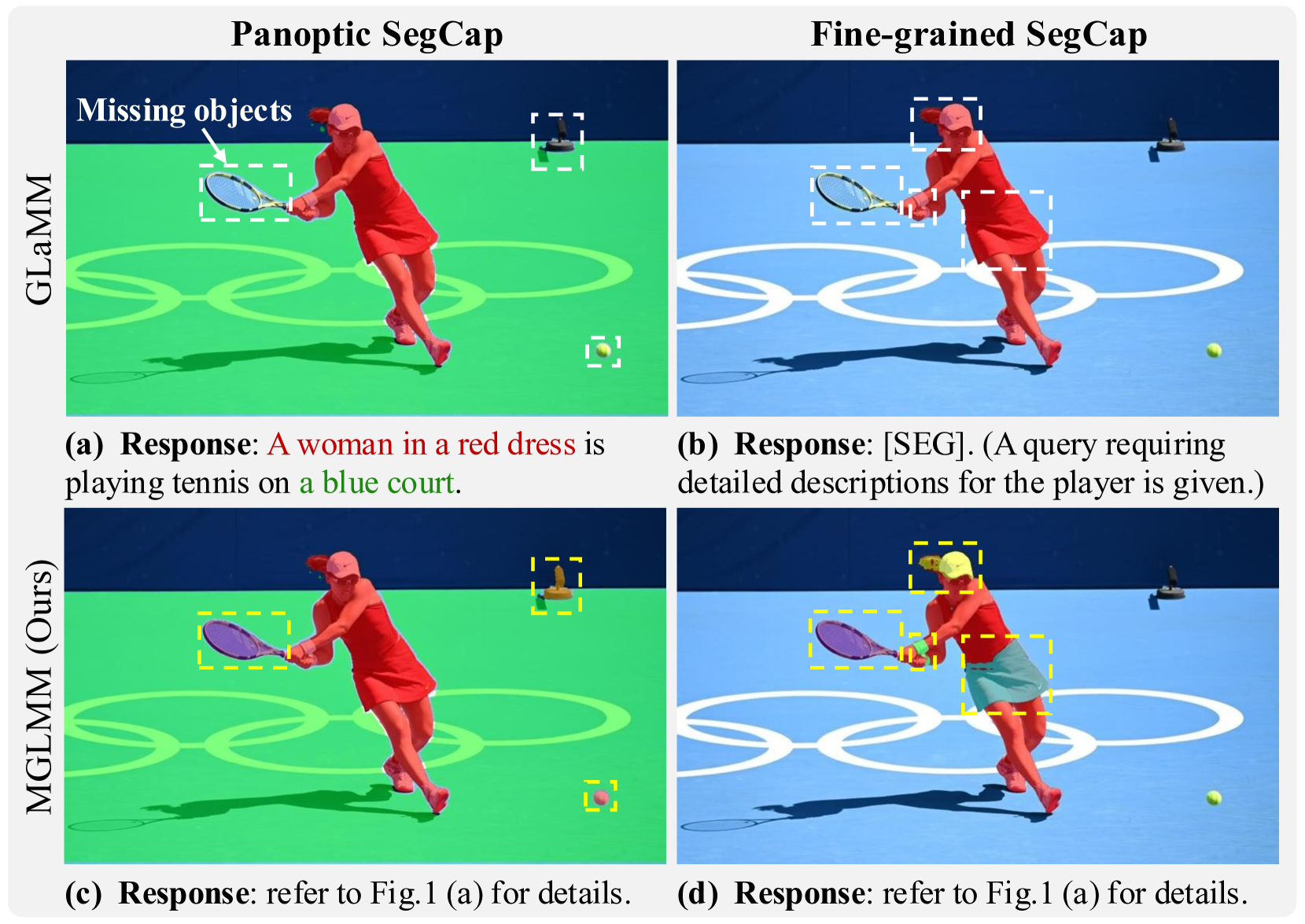
Large Multimodal Models (LMMs) have achieved significant progress by extending large language models. Building on this progress, the latest developments in LMMs demonstrate the ability to generate dense pixel-wise segmentation through the integration of segmentation models.Despite the innovations, the textual responses and segmentation masks of existing works remain at the instance level, showing limited ability to perform fine-grained understanding and segmentation even provided with detailed textual cues.To overcome this limitation, we introduce a Multi-Granularity Large Multimodal Model (MGLMM), which is capable of seamlessly adjusting the granularity of Segmentation and Captioning (SegCap) following user instructions, from panoptic SegCap to fine-grained SegCap. We name such a new task Multi-Granularity Segmentation and Captioning (MGSC). Observing the lack of a benchmark for model training and evaluation over the MGSC task, we establish a benchmark with aligned masks and captions in multi-granularity using our customized automated annotation pipeline. This benchmark comprises 10K images and more than 30K image-question pairs. We will release our dataset along with the implementation of our automated dataset annotation pipeline for further research.Besides, we propose a novel unified SegCap data format to unify heterogeneous segmentation datasets; it effectively facilitates learning to associate object concepts with visual features during multi-task training. Extensive experiments demonstrate that our MGLMM excels at tackling more than eight downstream tasks and achieves state-of-the-art performance in MGSC, GCG, image captioning, referring segmentation, multiple and empty segmentation, and reasoning segmentation tasks. The great performance and versatility of MGLMM underscore its potential impact on advancing multimodal research.
Read more9/23/2024
📈
0
GLaMM: Pixel Grounding Large Multimodal Model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji Mullappilly, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Erix Xing, Ming-Hsuan Yang, Fahad S. Khan
Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial LMMs used holistic images and text prompts to generate ungrounded textual responses. Recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring to a single object category at a time, require users to specify the regions, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of visually Grounded Conversation Generation (GCG), we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed GCG task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks, e.g., referring expression segmentation, image and region-level captioning and vision-language conversations.
Read more6/4/2024
🖼️
0
TG-LMM: Enhancing Medical Image Segmentation Accuracy through Text-Guided Large Multi-Modal Model
Yihao Zhao, Enhao Zhong, Cuiyun Yuan, Yang Li, Man Zhao, Chunxia Li, Jun Hu, Chenbin Liu
We propose TG-LMM (Text-Guided Large Multi-Modal Model), a novel approach that leverages textual descriptions of organs to enhance segmentation accuracy in medical images. Existing medical image segmentation methods face several challenges: current medical automatic segmentation models do not effectively utilize prior knowledge, such as descriptions of organ locations; previous text-visual models focus on identifying the target rather than improving the segmentation accuracy; prior models attempt to use prior knowledge to enhance accuracy but do not incorporate pre-trained models. To address these issues, TG-LMM integrates prior knowledge, specifically expert descriptions of the spatial locations of organs, into the segmentation process. Our model utilizes pre-trained image and text encoders to reduce the number of training parameters and accelerate the training process. Additionally, we designed a comprehensive image-text information fusion structure to ensure thorough integration of the two modalities of data. We evaluated TG-LMM on three authoritative medical image datasets, encompassing the segmentation of various parts of the human body. Our method demonstrated superior performance compared to existing approaches, such as MedSAM, SAM and nnUnet.
Read more9/6/2024

0
A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
Read more4/3/2024