GLCONet: Learning Multi-source Perception Representation for Camouflaged Object Detection

0

Sign in to get full access
Overview
- Camouflaged object detection is a challenging computer vision task
- This paper proposes a novel deep learning model called GLCONet to address this challenge
- GLCONet learns a multi-source perception representation by capturing global-local context and long-range dependencies
- The model is designed to perform collaborative optimization, leveraging complementary information from different perception sources
Plain English Explanation
The paper focuses on the problem of camouflaged object detection, which is when objects are hidden or blended into their surroundings, making them difficult for computers to identify. To tackle this challenge, the researchers developed a new deep learning model called GLCONet.
GLCONet works by learning a multi-source perception representation, which means it combines information from different visual cues to get a better understanding of the scene. Specifically, it captures global-local context - both the overall picture and the details - as well as long-range dependencies between different parts of the image.
The model is also designed to perform collaborative optimization, where it intelligently combines the complementary strengths of these different perception sources to make more accurate predictions. This allows GLCONet to excel at detecting camouflaged objects that would be hard for a single perception method to identify on its own.
Technical Explanation
The core of GLCONet is its ability to learn a multi-source perception representation that captures both global-local context and long-range dependencies. This is achieved through a novel architecture that includes:
-
Global-Local Collaborative Blocks: These blocks fuse global and local features to model the relationships between coarse-grained and fine-grained representations.
-
Non-local Attention Modules: These modules capture long-range dependencies by computing attention weights between distant spatial locations in the feature maps.
-
Collaborative Optimization: The model jointly optimizes the global-local and non-local modules in a collaborative manner, allowing the different perception sources to complement each other.
The researchers thoroughly evaluate GLCONet on several camouflaged object detection benchmarks, demonstrating state-of-the-art performance. Their ablation studies also confirm the importance of the global-local and long-range components for this task.
Critical Analysis
The paper presents a well-designed and effective solution for the challenging problem of camouflaged object detection. The key strengths of the approach are the multi-source perception representation and the collaborative optimization strategy, which allows the model to leverage complementary information from different visual cues.
However, the paper does not discuss potential limitations or future research directions in depth. For example, it would be interesting to know how GLCONet performs on edge cases or in real-world scenarios with more complex backgrounds and occlusions. Additionally, the computational complexity and inference time of the model could be examined, as these factors can be important for practical applications.
Overall, this research makes a valuable contribution to the field of computer vision, and the proposed GLCONet framework could inspire future work on enhancing perception capabilities for difficult detection tasks.
Conclusion
This paper introduces GLCONet, a novel deep learning model for camouflaged object detection. The key innovation is the use of a multi-source perception representation that captures global-local context and long-range dependencies, allowing the model to excel at identifying well-hidden objects. GLCONet achieves state-of-the-art performance on benchmark datasets, demonstrating the effectiveness of its collaborative optimization approach.
While the paper does not deeply explore potential limitations, the presented research represents a significant step forward in addressing the challenging problem of camouflaged object detection. The insights and techniques developed in this work could have broader implications for enhancing perception capabilities in computer vision and related fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GLCONet: Learning Multi-source Perception Representation for Camouflaged Object Detection
Yanguang Sun, Hanyu Xuan, Jian Yang, Lei Luo
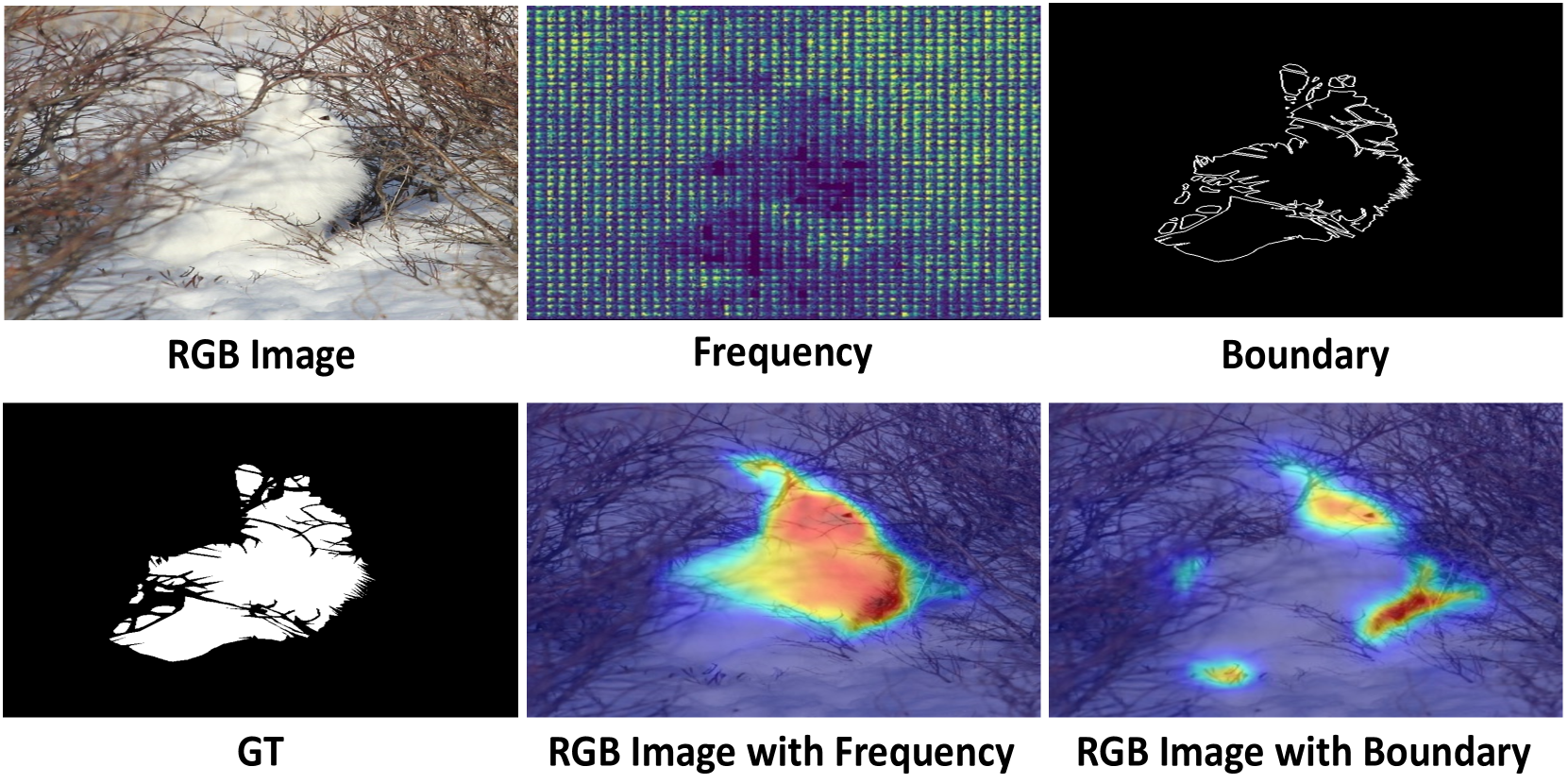
Recently, biological perception has been a powerful tool for handling the camouflaged object detection (COD) task. However, most existing methods are heavily dependent on the local spatial information of diverse scales from convolutional operations to optimize initial features. A commonly neglected point in these methods is the long-range dependencies between feature pixels from different scale spaces that can help the model build a global structure of the object, inducing a more precise image representation. In this paper, we propose a novel Global-Local Collaborative Optimization Network, called GLCONet. Technically, we first design a collaborative optimization strategy from the perspective of multi-source perception to simultaneously model the local details and global long-range relationships, which can provide features with abundant discriminative information to boost the accuracy in detecting camouflaged objects. Furthermore, we introduce an adjacent reverse decoder that contains cross-layer aggregation and reverse optimization to integrate complementary information from different levels for generating high-quality representations. Extensive experiments demonstrate that the proposed GLCONet method with different backbones can effectively activate potentially significant pixels in an image, outperforming twenty state-of-the-art methods on three public COD datasets. The source code is available at: https://github.com/CSYSI/GLCONet.
Read more9/17/2024
🔎
0
Towards Accurate Camouflaged Object Detection with Mixture Convolution and Interactive Fusion
Geng Chen, Xinrui Chen, Bo Dong, Mingchen Zhuge, Yongxiong Wang, Hongbo Bi, Jian Chen, Peng Wang, Yanning Zhang
Camouflaged object detection (COD), which aims to identify the objects that conceal themselves into the surroundings, has recently drawn increasing research efforts in the field of computer vision. In practice, the success of deep learning based COD is mainly determined by two key factors, including (i) A significantly large receptive field, which provides rich context information, and (ii) An effective fusion strategy, which aggregates the rich multi-level features for accurate COD. Motivated by these observations, in this paper, we propose a novel deep learning based COD approach, which integrates the large receptive field and effective feature fusion into a unified framework. Specifically, we first extract multi-level features from a backbone network. The resulting features are then fed to the proposed dual-branch mixture convolution modules, each of which utilizes multiple asymmetric convolutional layers and two dilated convolutional layers to extract rich context features from a large receptive field. Finally, we fuse the features using specially-designed multilevel interactive fusion modules, each of which employs an attention mechanism along with feature interaction for effective feature fusion. Our method detects camouflaged objects with an effective fusion strategy, which aggregates the rich context information from a large receptive field. All of these designs meet the requirements of COD well, allowing the accurate detection of camouflaged objects. Extensive experiments on widely-used benchmark datasets demonstrate that our method is capable of accurately detecting camouflaged objects and outperforms the state-of-the-art methods.
Read more7/22/2024
0
Adaptive Guidance Learning for Camouflaged Object Detection
Zhennan Chen, Xuying Zhang, Tian-Zhu Xiang, Ying Tai
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
Read more5/8/2024
🌐
0
ZoomNeXt: A Unified Collaborative Pyramid Network for Camouflaged Object Detection
Youwei Pang, Xiaoqi Zhao, Tian-Zhu Xiang, Lihe Zhang, Huchuan Lu
Recent camouflaged object detection (COD) attempts to segment objects visually blended into their surroundings, which is extremely complex and difficult in real-world scenarios. Apart from the high intrinsic similarity between camouflaged objects and their background, objects are usually diverse in scale, fuzzy in appearance, and even severely occluded. To this end, we propose an effective unified collaborative pyramid network that mimics human behavior when observing vague images and videos, ie zooming in and out. Specifically, our approach employs the zooming strategy to learn discriminative mixed-scale semantics by the multi-head scale integration and rich granularity perception units, which are designed to fully explore imperceptible clues between candidate objects and background surroundings. The former's intrinsic multi-head aggregation provides more diverse visual patterns. The latter's routing mechanism can effectively propagate inter-frame differences in spatiotemporal scenarios and be adaptively deactivated and output all-zero results for static representations. They provide a solid foundation for realizing a unified architecture for static and dynamic COD. Moreover, considering the uncertainty and ambiguity derived from indistinguishable textures, we construct a simple yet effective regularization, uncertainty awareness loss, to encourage predictions with higher confidence in candidate regions. Our highly task-friendly framework consistently outperforms existing state-of-the-art methods in image and video COD benchmarks. Our code can be found at {https://github.com/lartpang/ZoomNeXt}.
Read more7/16/2024