Knowledge graphs for empirical concept retrieval
2404.07008
0
0

Abstract
Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz. as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
Create account to get full access
Overview
- The paper presents a novel approach for retrieving empirical concepts using knowledge graphs.
- The method aims to improve the interpretability and explainability of AI models by grounding their predictions in human-understandable concepts.
- The research builds upon previous work on concept-based explainability methods and knowledge graph-based AI models.
Plain English Explanation
The paper focuses on a challenge in AI known as "explainability" - the ability to understand and interpret the decisions made by AI models. Many powerful AI models, like large language models, can be quite complex and opaque, making it difficult to understand why they make certain predictions.
The researchers propose using "knowledge graphs" to help improve the explainability of AI models. Knowledge graphs are structured databases that represent concepts and the relationships between them. By grounding the AI model's reasoning in these human-understandable concepts, the researchers aim to make the model's decisions more transparent and interpretable.
The key idea is to use the knowledge graph to retrieve relevant concepts that relate to the AI model's input and output. This allows the model to "explain" its predictions by pointing to the specific concepts it relied on, rather than just giving a black-box output. The researchers demonstrate this approach on a few test cases, showing how it can provide more meaningful explanations compared to existing techniques.
Overall, this research is an important step towards building more interpretable and trustworthy AI systems that can better align with human understanding. By bridging the gap between the AI's internal representations and human cognition, this approach has the potential to make AI more accessible and comprehensible to a wide range of users.
Technical Explanation
The paper presents a novel approach for concept-based explainability using knowledge graphs. The key components of the method are:
-
Knowledge Graph Construction: The researchers build a comprehensive knowledge graph by extracting concepts and their relationships from various sources, such as Wikipedia and subject-specific ontologies.
-
Concept Retrieval: Given an input to the AI model, the method retrieves the most relevant concepts from the knowledge graph based on the model's internal representations and the input features.
-
Concept-Based Explanation: The retrieved concepts are then used to provide interpretable explanations for the AI model's outputs. This involves mapping the model's predictions back to the relevant concepts in the knowledge graph.
The paper evaluates this approach on several tasks, including image classification and text summarization. The results show that the concept-based explanations are more meaningful and aligned with human intuition compared to existing post-hoc explainability techniques.
Critical Analysis
The paper presents a promising approach for improving the interpretability of AI models, but it also acknowledges several limitations and avenues for future research:
- The knowledge graph construction process relies heavily on the quality and coverage of the underlying data sources, which can be a challenging task in practice.
- The concept retrieval algorithm may not always capture the most relevant concepts, especially for complex inputs or outputs.
- The paper does not extensively explore the robustness of the concept-based explanations, such as their sensitivity to distribution shifts or adversarial perturbations.
Additionally, one could argue that the proposed method may still fall short of providing a complete understanding of the AI model's decision-making process. The concept-based explanations, while more interpretable, may not fully capture the nuances and contextual factors that influence the model's predictions.
Further research is needed to advance the state-of-the-art in ante-hoc explainable AI, where the model's interpretability is built into its architecture from the ground up, rather than relying on post-hoc explanations.
Conclusion
The paper presents a promising approach for improving the interpretability and explainability of AI models by leveraging knowledge graphs. By grounding the model's predictions in human-understandable concepts, the method aims to bridge the gap between the AI's internal representations and the user's cognitive understanding.
This research is an important step towards building more comprehensible and trustworthy AI systems that can be more readily adopted and understood by a wide range of users. While the proposed method has its limitations, the paper lays the foundation for further advancements in the field of explainable AI, paving the way for more transparent and accountable AI-powered solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
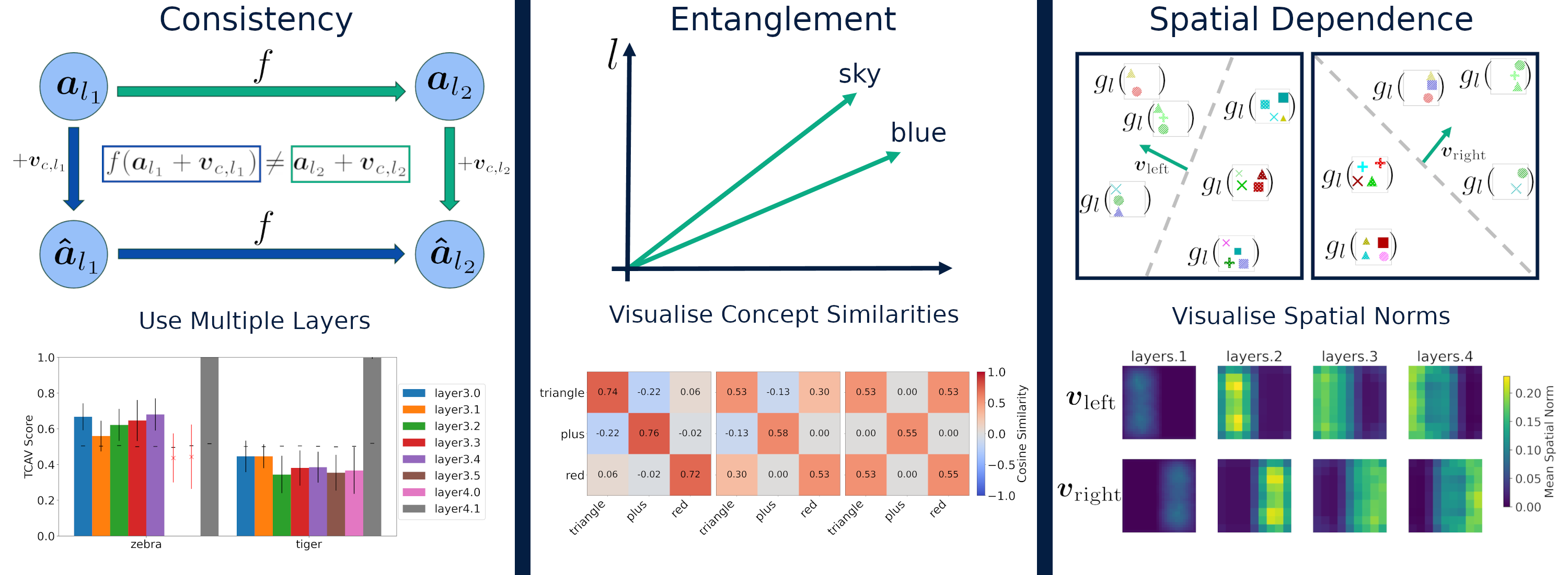
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
0
0
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
4/8/2024
🚀
Global Concept Explanations for Graphs by Contrastive Learning
Jonas Teufel, Pascal Friederich
0
0
Beyond improving trust and validating model fairness, xAI practices also have the potential to recover valuable scientific insights in application domains where little to no prior human intuition exists. To that end, we propose a method to extract global concept explanations from the predictions of graph neural networks to develop a deeper understanding of the tasks underlying structure-property relationships. We identify concept explanations as dense clusters in the self-explaining Megan models subgraph latent space. For each concept, we optimize a representative prototype graph and optionally use GPT-4 to provide hypotheses about why each structure has a certain effect on the prediction. We conduct computational experiments on synthetic and real-world graph property prediction tasks. For the synthetic tasks we find that our method correctly reproduces the structural rules by which they were created. For real-world molecular property regression and classification tasks, we find that our method rediscovers established rules of thumb. More specifically, our results for molecular mutagenicity prediction indicate more fine-grained resolution of structural details than existing explainability methods, consistent with previous results from chemistry literature. Overall, our results show promising capability to extract the underlying structure-property relationships for complex graph property prediction tasks.
4/26/2024
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Jae Hee Lee, Sergio Lanza, Stefan Wermter
0
0
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
5/6/2024

Concept Induction using LLMs: a user experiment for assessment
Adrita Barua, Cara Widmer, Pascal Hitzler
0
0
Explainable Artificial Intelligence (XAI) poses a significant challenge in providing transparent and understandable insights into complex AI models. Traditional post-hoc algorithms, while useful, often struggle to deliver interpretable explanations. Concept-based models offer a promising avenue by incorporating explicit representations of concepts to enhance interpretability. However, existing research on automatic concept discovery methods is often limited by lower-level concepts, costly human annotation requirements, and a restricted domain of background knowledge. In this study, we explore the potential of a Large Language Model (LLM), specifically GPT-4, by leveraging its domain knowledge and common-sense capability to generate high-level concepts that are meaningful as explanations for humans, for a specific setting of image classification. We use minimal textual object information available in the data via prompting to facilitate this process. To evaluate the output, we compare the concepts generated by the LLM with two other methods: concepts generated by humans and the ECII heuristic concept induction system. Since there is no established metric to determine the human understandability of concepts, we conducted a human study to assess the effectiveness of the LLM-generated concepts. Our findings indicate that while human-generated explanations remain superior, concepts derived from GPT-4 are more comprehensible to humans compared to those generated by ECII.
4/19/2024