Global Convergence of Decentralized Retraction-Free Optimization on the Stiefel Manifold

0

Sign in to get full access
Overview
- This paper presents a novel decentralized optimization algorithm for optimizing functions on the Stiefel manifold, which is a set of orthogonal matrices.
- The algorithm, called Decentralized Retraction-Free Optimization (DRFO), is designed to converge globally without the need for retractions, which are complex operations required by many existing optimization methods on manifolds.
- The authors prove the global convergence of DRFO and demonstrate its effectiveness on various benchmark problems, including low-rank matrix completion and quantum process tomography.
Plain English Explanation
The paper's key contribution is a new algorithm called Decentralized Retraction-Free Optimization (DRFO) that can optimize functions on the Stiefel manifold. The Stiefel manifold is a set of orthogonal matrices, which are useful in many machine learning and optimization problems, such as low-rank matrix completion and quantum process tomography.
Many existing optimization algorithms for manifolds require complex operations called "retractions" to stay on the manifold during the optimization process. DRFO, on the other hand, doesn't need these retractions, making it simpler and more efficient. The authors prove that DRFO can converge globally to a solution, meaning it will find the best possible answer regardless of the starting point.
The researchers tested DRFO on several benchmark problems and found that it outperformed existing methods, especially in decentralized optimization settings where multiple devices work together to solve a problem. This makes DRFO a promising tool for decentralized machine learning and other applications that involve optimizing functions on the Stiefel manifold.
Technical Explanation
The paper presents a new decentralized optimization algorithm called Decentralized Retraction-Free Optimization (DRFO) for optimizing functions on the Stiefel manifold. The Stiefel manifold is the set of all orthogonal matrices, and it arises in many machine learning and optimization problems, such as low-rank matrix completion and quantum process tomography.
Many existing optimization algorithms for manifolds, such as the Riemannian gradient method, require complex operations called "retractions" to stay on the manifold during the optimization process. DRFO, on the other hand, is designed to optimize functions on the Stiefel manifold without the need for retractions, making it simpler and more efficient.
The authors prove the global convergence of DRFO, meaning that the algorithm is guaranteed to converge to a stationary point regardless of the starting point. This is in contrast to many existing decentralized optimization methods, which can only guarantee convergence to a local optimum.
The researchers evaluate DRFO on several benchmark problems, including low-rank matrix completion and quantum process tomography. They show that DRFO outperforms existing methods, especially in decentralized optimization settings where multiple devices work together to solve a problem. This makes DRFO a promising tool for decentralized machine learning and other applications that involve optimizing functions on the Stiefel manifold.
Critical Analysis
The paper presents a well-designed and theoretically sound algorithm for decentralized optimization on the Stiefel manifold. The authors' proof of global convergence is a significant contribution, as it addresses a key limitation of many existing methods that can only guarantee convergence to a local optimum.
One potential limitation of the DRFO algorithm is that it may not be as computationally efficient as some existing methods, as it still requires the computation of Riemannian gradients, which can be costly. The authors acknowledge this and suggest that further research is needed to develop even more efficient algorithms for optimization on the Stiefel manifold.
Additionally, the paper focuses on theoretical analysis and benchmark problems, but does not explore the performance of DRFO on larger-scale, real-world problems. It would be interesting to see how the algorithm scales and performs in more practical applications, such as large-scale decentralized machine learning or high-dimensional quantum process tomography.
Overall, the paper presents a valuable contribution to the field of decentralized optimization on manifolds, and the DRFO algorithm appears to be a promising approach for solving such problems. Further research and testing on real-world applications would be beneficial to fully assess the algorithm's strengths and limitations.
Conclusion
This paper introduces a novel decentralized optimization algorithm called Decentralized Retraction-Free Optimization (DRFO) that can optimize functions on the Stiefel manifold without the need for complex retraction operations. The authors prove the global convergence of DRFO and demonstrate its effectiveness on various benchmark problems, including low-rank matrix completion and quantum process tomography.
DRFO's ability to converge globally, combined with its decentralized nature, makes it a promising tool for a wide range of applications, such as decentralized machine learning and quantum computing. Further research on the algorithm's performance in larger-scale, real-world problems could help to fully evaluate its potential and guide the development of even more efficient optimization methods for the Stiefel manifold.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Global Convergence of Decentralized Retraction-Free Optimization on the Stiefel Manifold
Youbang Sun, Shixiang Chen, Alfredo Garcia, Shahin Shahrampour
Many classical and modern machine learning algorithms require solving optimization tasks under orthogonal constraints. Solving these tasks often require calculating retraction-based gradient descent updates on the corresponding Riemannian manifold, which can be computationally expensive. Recently Ablin et al. proposed an infeasible retraction-free algorithm, which is significantly more efficient. In this paper, we study the decentralized non-convex optimization task over a network of agents on the Stiefel manifold with retraction-free updates. We propose textbf{D}ecentralized textbf{R}etraction-textbf{F}ree textbf{G}radient textbf{T}racking (DRFGT) algorithm, and show that DRFGT exhibits ergodic $mathcal{O}(1/K)$ convergence rate, the same rate of convergence as the centralized, retraction-based methods. We also provide numerical experiments demonstrating that DRFGT performs on par with the state-of-the-art retraction based methods with substantially reduced computational overhead.
Read more5/21/2024
🛠️
0
Learning-Rate-Free Stochastic Optimization over Riemannian Manifolds
Daniel Dodd, Louis Sharrock, Christopher Nemeth
In recent years, interest in gradient-based optimization over Riemannian manifolds has surged. However, a significant challenge lies in the reliance on hyperparameters, especially the learning rate, which requires meticulous tuning by practitioners to ensure convergence at a suitable rate. In this work, we introduce innovative learning-rate-free algorithms for stochastic optimization over Riemannian manifolds, eliminating the need for hand-tuning and providing a more robust and user-friendly approach. We establish high probability convergence guarantees that are optimal, up to logarithmic factors, compared to the best-known optimally tuned rate in the deterministic setting. Our approach is validated through numerical experiments, demonstrating competitive performance against learning-rate-dependent algorithms.
Read more6/5/2024
0
FORML: A Riemannian Hessian-free Method for Meta-learning on Stiefel Manifolds
Hadi Tabealhojeh, Soumava Kumar Roy, Peyman Adibi, Hossein Karshenas
Meta-learning problem is usually formulated as a bi-level optimization in which the task-specific and the meta-parameters are updated in the inner and outer loops of optimization, respectively. However, performing the optimization in the Riemannian space, where the parameters and meta-parameters are located on Riemannian manifolds is computationally intensive. Unlike the Euclidean methods, the Riemannian backpropagation needs computing the second-order derivatives that include backward computations through the Riemannian operators such as retraction and orthogonal projection. This paper introduces a Hessian-free approach that uses a first-order approximation of derivatives on the Stiefel manifold. Our method significantly reduces the computational load and memory footprint. We show how using a Stiefel fully-connected layer that enforces orthogonality constraint on the parameters of the last classification layer as the head of the backbone network, strengthens the representation reuse of the gradient-based meta-learning methods. Our experimental results across various few-shot learning datasets, demonstrate the superiority of our proposed method compared to the state-of-the-art methods, especially MAML, its Euclidean counterpart.
Read more6/4/2024
0
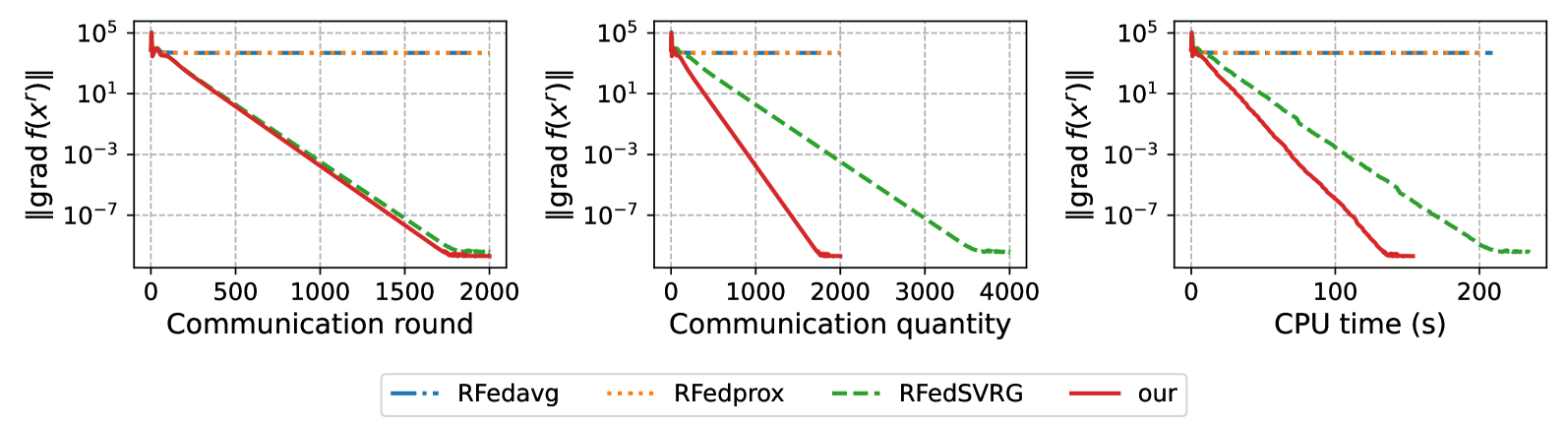
Nonconvex Federated Learning on Compact Smooth Submanifolds With Heterogeneous Data
Jiaojiao Zhang, Jiang Hu, Anthony Man-Cho So, Mikael Johansson
Many machine learning tasks, such as principal component analysis and low-rank matrix completion, give rise to manifold optimization problems. Although there is a large body of work studying the design and analysis of algorithms for manifold optimization in the centralized setting, there are currently very few works addressing the federated setting. In this paper, we consider nonconvex federated learning over a compact smooth submanifold in the setting of heterogeneous client data. We propose an algorithm that leverages stochastic Riemannian gradients and a manifold projection operator to improve computational efficiency, uses local updates to improve communication efficiency, and avoids client drift. Theoretically, we show that our proposed algorithm converges sub-linearly to a neighborhood of a first-order optimal solution by using a novel analysis that jointly exploits the manifold structure and properties of the loss functions. Numerical experiments demonstrate that our algorithm has significantly smaller computational and communication overhead than existing methods.
Read more6/13/2024