Stochastic Constrained Decentralized Optimization for Machine Learning with Fewer Data Oracles: a Gradient Sliding Approach
2404.02511
0
0

Abstract
In modern decentralized applications, ensuring communication efficiency and privacy for the users are the key challenges. In order to train machine-learning models, the algorithm has to communicate to the data center and sample data for its gradient computation, thus exposing the data and increasing the communication cost. This gives rise to the need for a decentralized optimization algorithm that is communication-efficient and minimizes the number of gradient computations. To this end, we propose the primal-dual sliding with conditional gradient sliding framework, which is communication-efficient and achieves an $varepsilon$-approximate solution with the optimal gradient complexity of $O(1/sqrt{varepsilon}+sigma^2/{varepsilon^2})$ and $O(log(1/varepsilon)+sigma^2/varepsilon)$ for the convex and strongly convex setting respectively and an LO (Linear Optimization) complexity of $O(1/varepsilon^2)$ for both settings given a stochastic gradient oracle with variance $sigma^2$. Compared with the prior work cite{wai-fw-2017}, our framework relaxes the assumption of the optimal solution being a strict interior point of the feasible set and enjoys wider applicability for large-scale training using a stochastic gradient oracle. We also demonstrate the efficiency of our algorithms with various numerical experiments.
Create account to get full access
Overview
- This paper proposes a novel stochastic constrained decentralized optimization algorithm for machine learning problems with fewer data oracles.
- The algorithm, called Gradient Sliding, aims to improve the efficiency and performance of decentralized optimization in settings with limited data access.
- The authors conduct experiments to demonstrate the algorithm's effectiveness compared to existing methods.
Plain English Explanation
The paper introduces a new way to optimize machine learning models in a decentralized setting, where different computers or devices work together to train the model but each has access to only a subset of the training data.
In a typical decentralized setup, each device would have its own "oracle" - a source of training data it can access. The more oracles available, the better the optimization can perform. However, in some cases, there may be constraints or limitations that reduce the number of available oracles.
The Gradient Sliding algorithm proposed in this paper aims to work effectively even when the number of oracles is limited. It does this by carefully coordinating the information sharing and optimization steps between the different devices. This allows the model to be trained efficiently without requiring full access to all the training data.
The key idea is to have the devices "slide" their optimization gradients - the directions in which to update the model parameters - in a way that compensates for the missing data from unavailable oracles. This gradient sliding process enables effective optimization despite the data limitations.
Through experiments, the authors demonstrate that their Gradient Sliding approach outperforms existing decentralized optimization methods, especially when the number of available oracles is relatively small. This suggests the algorithm could be particularly useful in scenarios with strict data access constraints.
Technical Explanation
The paper introduces a novel stochastic constrained decentralized optimization algorithm called Gradient Sliding for solving machine learning problems in a data-limited setting. In a decentralized optimization setup, multiple computing devices or "agents" collaborate to train a shared model, with each agent having access to a subset of the training data through local "data oracles."
The authors observe that existing decentralized optimization methods tend to perform poorly when the number of available data oracles is limited, as this reduces the overall amount of information available to the optimization process. To address this, the Gradient Sliding algorithm employs a careful coordination of information sharing and gradient updates between agents.
The key idea is to have each agent "slide" its gradient updates in a specific direction, determined by the gradients of the other agents. This gradient sliding process allows the agents to compensate for the missing data from unavailable oracles, enabling effective optimization despite the data constraints.
The authors derive theoretical guarantees for the convergence and optimality of the Gradient Sliding algorithm. They also conduct extensive experiments on both synthetic and real-world machine learning tasks, demonstrating that their approach outperforms existing decentralized optimization methods, especially when the number of available oracles is relatively small.
Critical Analysis
The paper presents a well-designed and comprehensive study of the Gradient Sliding algorithm for stochastic constrained decentralized optimization. The authors have thoroughly analyzed the theoretical properties of the algorithm and provided compelling experimental results to support its effectiveness.
One potential limitation mentioned in the paper is the assumption of a "fully connected" communication network between agents, which may not always be realistic in practical scenarios. It would be interesting to see how the Gradient Sliding algorithm could be extended to handle more general network topologies or communication constraints.
Additionally, the paper does not discuss the computational and communication overhead introduced by the gradient sliding process. As the number of agents and optimization iterations increases, the coordination and information exchange required by the algorithm may become a significant factor. Investigating the scalability of Gradient Sliding would be a valuable area for future research.
Another aspect that could be explored is the algorithm's performance in the presence of heterogeneous data distributions or non-iid data across the agents. Real-world decentralized scenarios often involve agents with diverse data sources, and understanding the algorithm's robustness to such scenarios would be an important consideration.
Overall, the Gradient Sliding algorithm presented in this paper represents a promising approach to address the challenges of decentralized optimization with limited data access. The authors have made a valuable contribution to the field, and their work opens up interesting avenues for further research and practical applications.
Conclusion
This paper introduces a novel stochastic constrained decentralized optimization algorithm called Gradient Sliding, which addresses the challenge of training machine learning models in a decentralized setting with limited data access. By carefully coordinating the information sharing and gradient updates between agents, the Gradient Sliding algorithm can effectively optimize the model even when the number of available data oracles is relatively small.
The authors have provided a comprehensive theoretical analysis and extensive experimental evaluation, demonstrating the superior performance of their approach compared to existing decentralized optimization methods. This work has the potential to significantly impact the field of decentralized machine learning, enabling more efficient and effective model training in scenarios with strict data access constraints.
As the demand for privacy-preserving and resource-efficient machine learning solutions continues to grow, the Gradient Sliding algorithm represents an important step forward in addressing these challenges. The insights and techniques presented in this paper can inspire further research and development in the area of decentralized optimization, ultimately contributing to the advancement of machine learning applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Structured Reinforcement Learning for Incentivized Stochastic Covert Optimization
Adit Jain, Vikram Krishnamurthy
0
0
This paper studies how a stochastic gradient algorithm (SG) can be controlled to hide the estimate of the local stationary point from an eavesdropper. Such problems are of significant interest in distributed optimization settings like federated learning and inventory management. A learner queries a stochastic oracle and incentivizes the oracle to obtain noisy gradient measurements and perform SG. The oracle probabilistically returns either a noisy gradient of the function} or a non-informative measurement, depending on the oracle state and incentive. The learner's query and incentive are visible to an eavesdropper who wishes to estimate the stationary point. This paper formulates the problem of the learner performing covert optimization by dynamically incentivizing the stochastic oracle and obfuscating the eavesdropper as a finite-horizon Markov decision process (MDP). Using conditions for interval-dominance on the cost and transition probability structure, we show that the optimal policy for the MDP has a monotone threshold structure. We propose searching for the optimal stationary policy with the threshold structure using a stochastic approximation algorithm and a multi-armed bandit approach. The effectiveness of our methods is numerically demonstrated on a covert federated learning hate-speech classification task.
5/14/2024
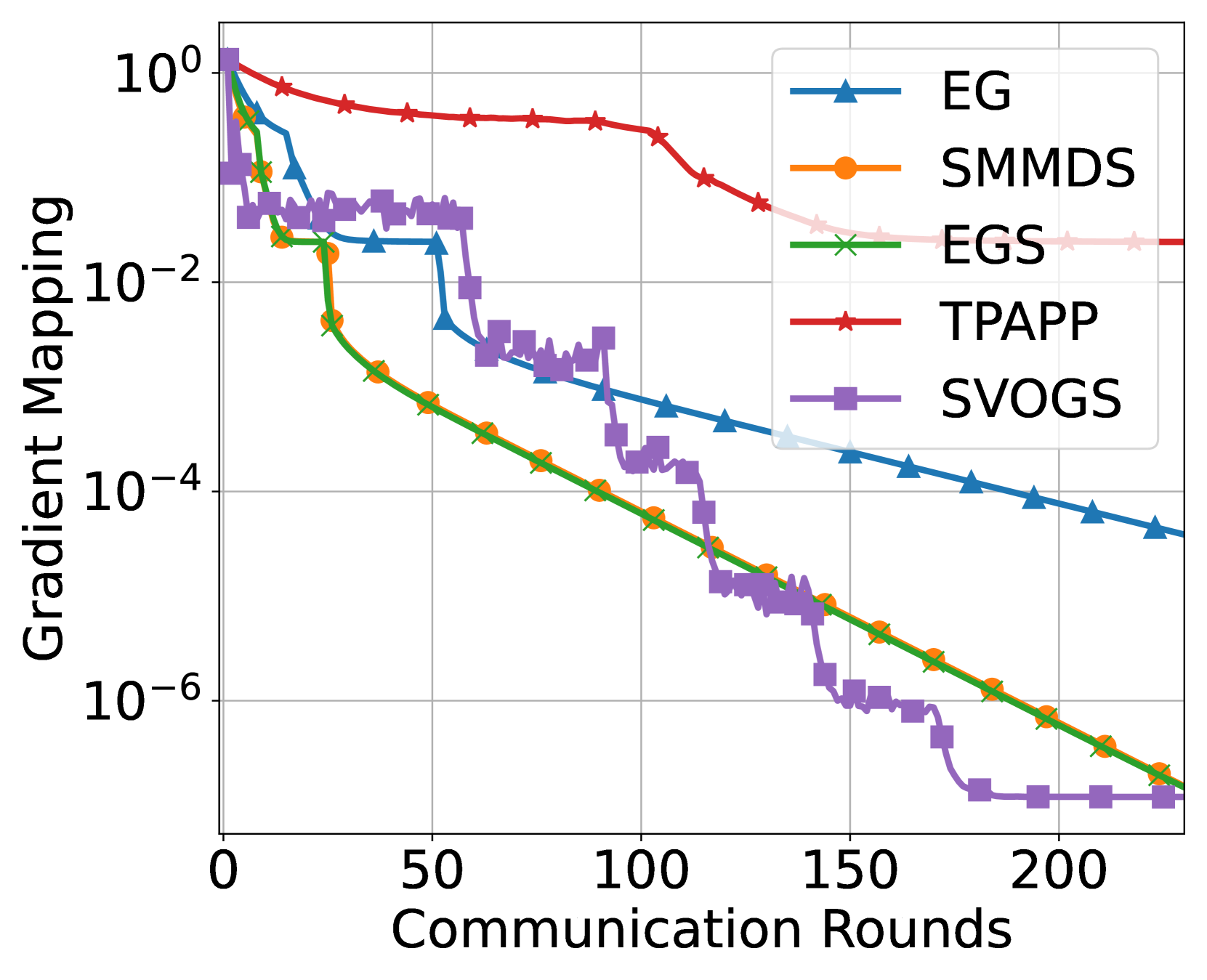
Near-Optimal Distributed Minimax Optimization under the Second-Order Similarity
Qihao Zhou, Haishan Ye, Luo Luo
0
0
This paper considers the distributed convex-concave minimax optimization under the second-order similarity. We propose stochastic variance-reduced optimistic gradient sliding (SVOGS) method, which takes the advantage of the finite-sum structure in the objective by involving the mini-batch client sampling and variance reduction. We prove SVOGS can achieve the $varepsilon$-duality gap within communication rounds of ${mathcal O}(delta D^2/varepsilon)$, communication complexity of ${mathcal O}(n+sqrt{n}delta D^2/varepsilon)$, and local gradient calls of $tilde{mathcal O}(n+(sqrt{n}delta+L)D^2/varepsilonlog(1/varepsilon))$, where $n$ is the number of nodes, $delta$ is the degree of the second-order similarity, $L$ is the smoothness parameter and $D$ is the diameter of the constraint set. We can verify that all of above complexity (nearly) matches the corresponding lower bounds. For the specific $mu$-strongly-convex-$mu$-strongly-convex case, our algorithm has the upper bounds on communication rounds, communication complexity, and local gradient calls of $mathcal O(delta/mulog(1/varepsilon))$, ${mathcal O}((n+sqrt{n}delta/mu)log(1/varepsilon))$, and $tilde{mathcal O}(n+(sqrt{n}delta+L)/mu)log(1/varepsilon))$ respectively, which are also nearly tight. Furthermore, we conduct the numerical experiments to show the empirical advantages of proposed method.
5/28/2024
🛠️
On the Communication Complexity of Decentralized Bilevel Optimization
Yihan Zhang, My T. Thai, Jie Wu, Hongchang Gao
0
0
Stochastic bilevel optimization finds widespread applications in machine learning, including meta-learning, hyperparameter optimization, and neural architecture search. To extend stochastic bilevel optimization to distributed data, several decentralized stochastic bilevel optimization algorithms have been developed. However, existing methods often suffer from slow convergence rates and high communication costs in heterogeneous settings, limiting their applicability to real-world tasks. To address these issues, we propose two novel decentralized stochastic bilevel gradient descent algorithms based on simultaneous and alternating update strategies. Our algorithms can achieve faster convergence rates and lower communication costs than existing methods. Importantly, our convergence analyses do not rely on strong assumptions regarding heterogeneity. More importantly, our theoretical analysis clearly discloses how the additional communication required for estimating hypergradient under the heterogeneous setting affects the convergence rate. To the best of our knowledge, this is the first time such favorable theoretical results have been achieved with mild assumptions in the heterogeneous setting. Furthermore, we demonstrate how to establish the convergence rate for the alternating update strategy when combined with the variance-reduced gradient. Finally, experimental results confirm the efficacy of our algorithms.
6/4/2024
🔍
An Efficient Stochastic Algorithm for Decentralized Nonconvex-Strongly-Concave Minimax Optimization
Lesi Chen, Haishan Ye, Luo Luo
0
0
This paper studies the stochastic nonconvex-strongly-concave minimax optimization over a multi-agent network. We propose an efficient algorithm, called Decentralized Recursive gradient descEnt Ascent Method (DREAM), which achieves the best-known theoretical guarantee for finding the $epsilon$-stationary points. Concretely, it requires $mathcal{O}(min (kappa^3epsilon^{-3},kappa^2 sqrt{N} epsilon^{-2} ))$ stochastic first-order oracle (SFO) calls and $tilde{mathcal{O}}(kappa^2 epsilon^{-2})$ communication rounds, where $kappa$ is the condition number and $N$ is the total number of individual functions. Our numerical experiments also validate the superiority of DREAM over previous methods.
5/15/2024