Global-Local Distillation Network-Based Audio-Visual Speaker Tracking with Incomplete Modalities

0

Sign in to get full access
Overview
- Speaker tracking is the task of locating and following the position of a speaker in a video or audio recording.
- This paper proposes a Global-Local Distillation Network for audio-visual speaker tracking, which can handle incomplete modalities (e.g., missing audio or video).
- The method uses knowledge distillation to train a compact student model that can accurately track speakers even when one modality is missing.
Plain English Explanation
The paper describes a new system for tracking the location of speakers in videos or audio recordings. Tracking the speaker is important for applications like video conferencing, surveillance, and human-robot interaction.
The key idea is to use knowledge distillation to train a compact "student" model that can accurately track speakers even when one of the input modalities (audio or video) is missing. The student model learns from a larger "teacher" model that uses both audio and video. This allows the student to perform well with incomplete information.
For example, if the video feed is temporarily lost, the student model can still use the audio cues to continue tracking the speaker's location. This robustness to missing modalities is an important practical advantage.
The authors show that their Global-Local Distillation Network outperforms other audio-visual speaker tracking methods, especially when one modality is unavailable. This makes it a promising approach for real-world applications where sensor failures or occlusions are common.
Technical Explanation
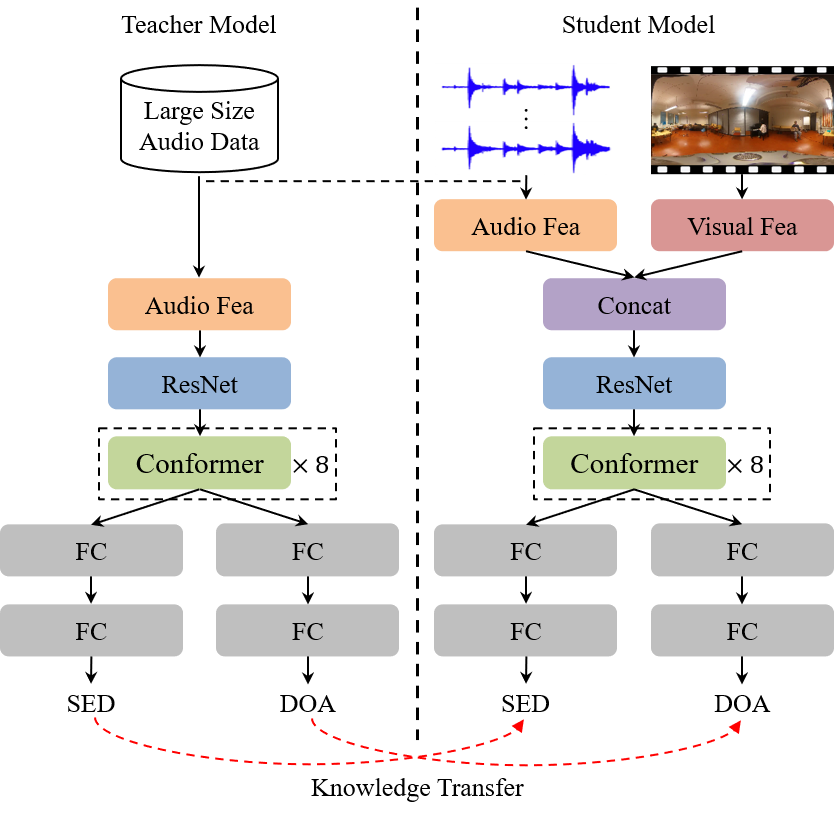
The paper introduces the Global-Local Distillation Network (GLDN) for audio-visual speaker tracking. The key components are:
-
Teacher Model: A large multi-modal model that uses both audio and video inputs to predict the speaker's location. This serves as the "teacher" for knowledge distillation.
-
Student Model: A compact single-modal model (using either audio or video) that is trained to mimic the teacher's performance through knowledge distillation. This allows the student to learn robust features for speaker tracking even with incomplete modalities.
-
Distillation Loss: The student model is trained to minimize the difference between its output and the teacher's output, encouraging it to learn the teacher's underlying speaker tracking capabilities.
The authors evaluate GLDN on public audio-visual speaker tracking datasets. They show that the student model trained with distillation can match or outperform other models that use both modalities, especially when one input is missing. This demonstrates the effectiveness of the distillation approach for building robust multi-modal systems.
Critical Analysis
The paper makes a compelling case for the GLDN approach, but there are a few potential limitations and areas for further research:
-
Generalization to More Modalities: The current work only considers audio and video as input modalities. It would be interesting to see how the distillation approach extends to additional modalities, such as depth or infrared data, to further improve robustness.
-
Real-World Deployment Challenges: While the results on benchmark datasets are promising, deploying such a system in the real world may introduce additional challenges, such as sensor calibration, synchronization, and environmental noise. Evaluating GLDN in more realistic settings would be valuable.
-
Computational Efficiency: The paper does not provide detailed comparisons of the computational efficiency of the teacher and student models. This is an important consideration for deploying such systems on resource-constrained devices.
-
Interpretability and Explainability: As with many deep learning models, the internal workings of GLDN may be difficult to interpret. Developing more explainable approaches could enhance trust and understanding of the system's decision-making.
Overall, the GLDN presents a compelling and practical solution for audio-visual speaker tracking, particularly in the face of incomplete or unreliable sensor data. Further research to address the identified limitations could strengthen the approach and expand its real-world applicability.
Conclusion
This paper introduces the Global-Local Distillation Network (GLDN), a novel audio-visual speaker tracking system that can maintain accurate performance even when one of the input modalities is missing. By using knowledge distillation to train a compact student model, GLDN achieves robustness to incomplete data while preserving high tracking accuracy.
The key innovation is the distillation-based training process, which allows the student model to learn effective speaker tracking capabilities from a larger teacher model. This makes GLDN a promising solution for real-world applications where sensor failures or occlusions are common, such as video conferencing, surveillance, and human-robot interaction.
The paper provides a thorough evaluation of GLDN on public datasets, demonstrating its advantages over other audio-visual speaker tracking methods. While there are some potential areas for further research, this work represents an important step towards building reliable and versatile multi-modal systems for speaker localization and tracking.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Global-Local Distillation Network-Based Audio-Visual Speaker Tracking with Incomplete Modalities
Yidi Li, Yihan Li, Yixin Guo, Bin Ren, Zhenhuan Xu, Hao Guo, Hong Liu, Nicu Sebe
In speaker tracking research, integrating and complementing multi-modal data is a crucial strategy for improving the accuracy and robustness of tracking systems. However, tracking with incomplete modalities remains a challenging issue due to noisy observations caused by occlusion, acoustic noise, and sensor failures. Especially when there is missing data in multiple modalities, the performance of existing multi-modal fusion methods tends to decrease. To this end, we propose a Global-Local Distillation-based Tracker (GLDTracker) for robust audio-visual speaker tracking. GLDTracker is driven by a teacher-student distillation model, enabling the flexible fusion of incomplete information from each modality. The teacher network processes global signals captured by camera and microphone arrays, and the student network handles local information subject to visual occlusion and missing audio channels. By transferring knowledge from teacher to student, the student network can better adapt to complex dynamic scenes with incomplete observations. In the student network, a global feature reconstruction module based on the generative adversarial network is constructed to reconstruct global features from feature embedding with missing local information. Furthermore, a multi-modal multi-level fusion attention is introduced to integrate the incomplete feature and the reconstructed feature, leveraging the complementarity and consistency of audio-visual and global-local features. Experimental results on the AV16.3 dataset demonstrate that the proposed GLDTracker outperforms existing state-of-the-art audio-visual trackers and achieves leading performance on both standard and incomplete modalities datasets, highlighting its superiority and robustness in complex conditions. The code and models will be available.
Read more8/28/2024
0
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Read more6/24/2024
0
Multi-Modal Video Dialog State Tracking in the Wild
Adnen Abdessaied, Lei Shi, Andreas Bulling
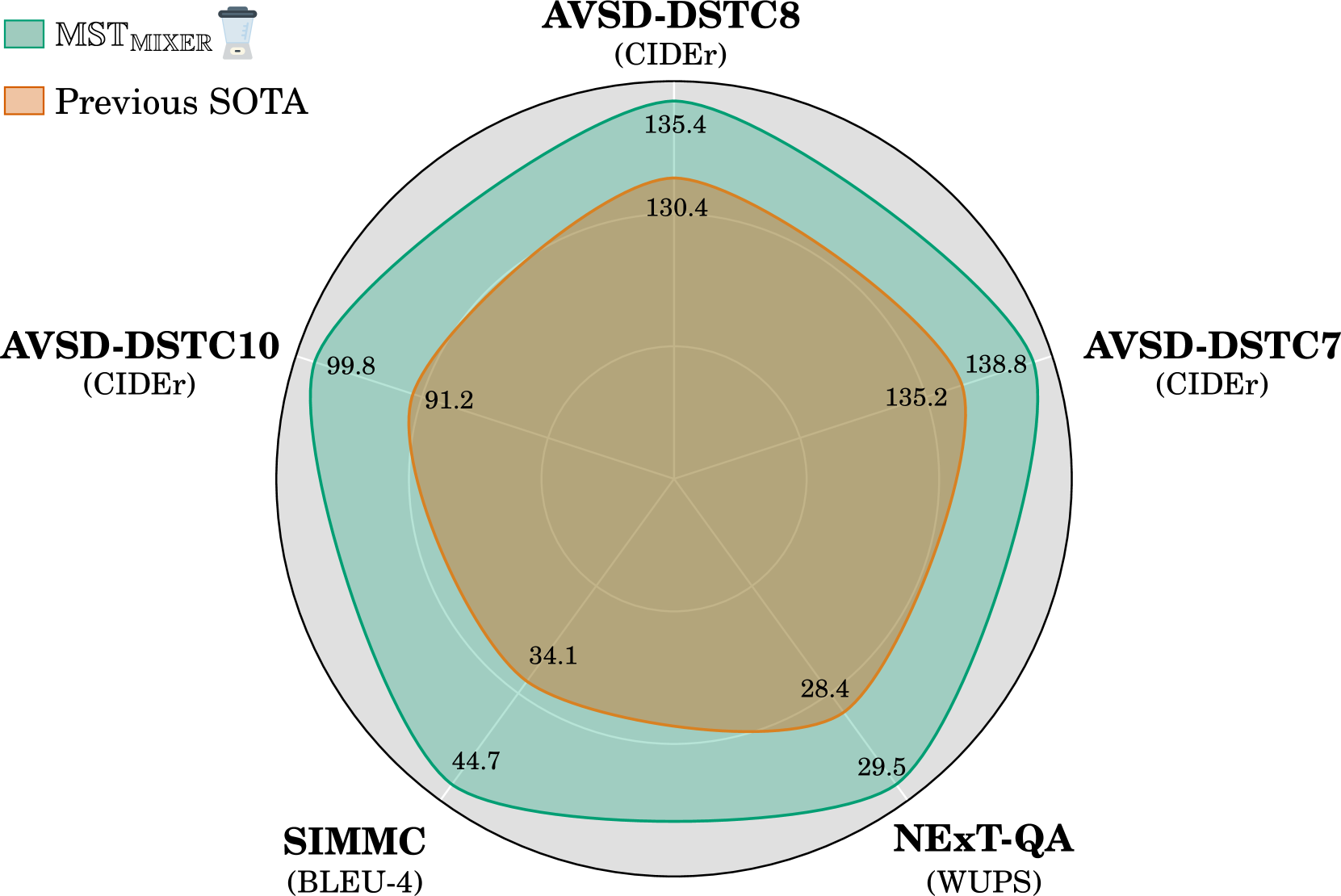
We present MST-MIXER - a novel video dialog model operating over a generic multi-modal state tracking scheme. Current models that claim to perform multi-modal state tracking fall short of two major aspects: (1) They either track only one modality (mostly the visual input) or (2) they target synthetic datasets that do not reflect the complexity of real-world in the wild scenarios. Our model addresses these two limitations in an attempt to close this crucial research gap. Specifically, MST-MIXER first tracks the most important constituents of each input modality. Then, it predicts the missing underlying structure of the selected constituents of each modality by learning local latent graphs using a novel multi-modal graph structure learning method. Subsequently, the learned local graphs and features are parsed together to form a global graph operating on the mix of all modalities which further refines its structure and node embeddings. Finally, the fine-grained graph node features are used to enhance the hidden states of the backbone Vision-Language Model (VLM). MST-MIXER achieves new state-of-the-art results on five challenging benchmarks.
Read more7/8/2024
0
Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
Akio Hayakawa, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
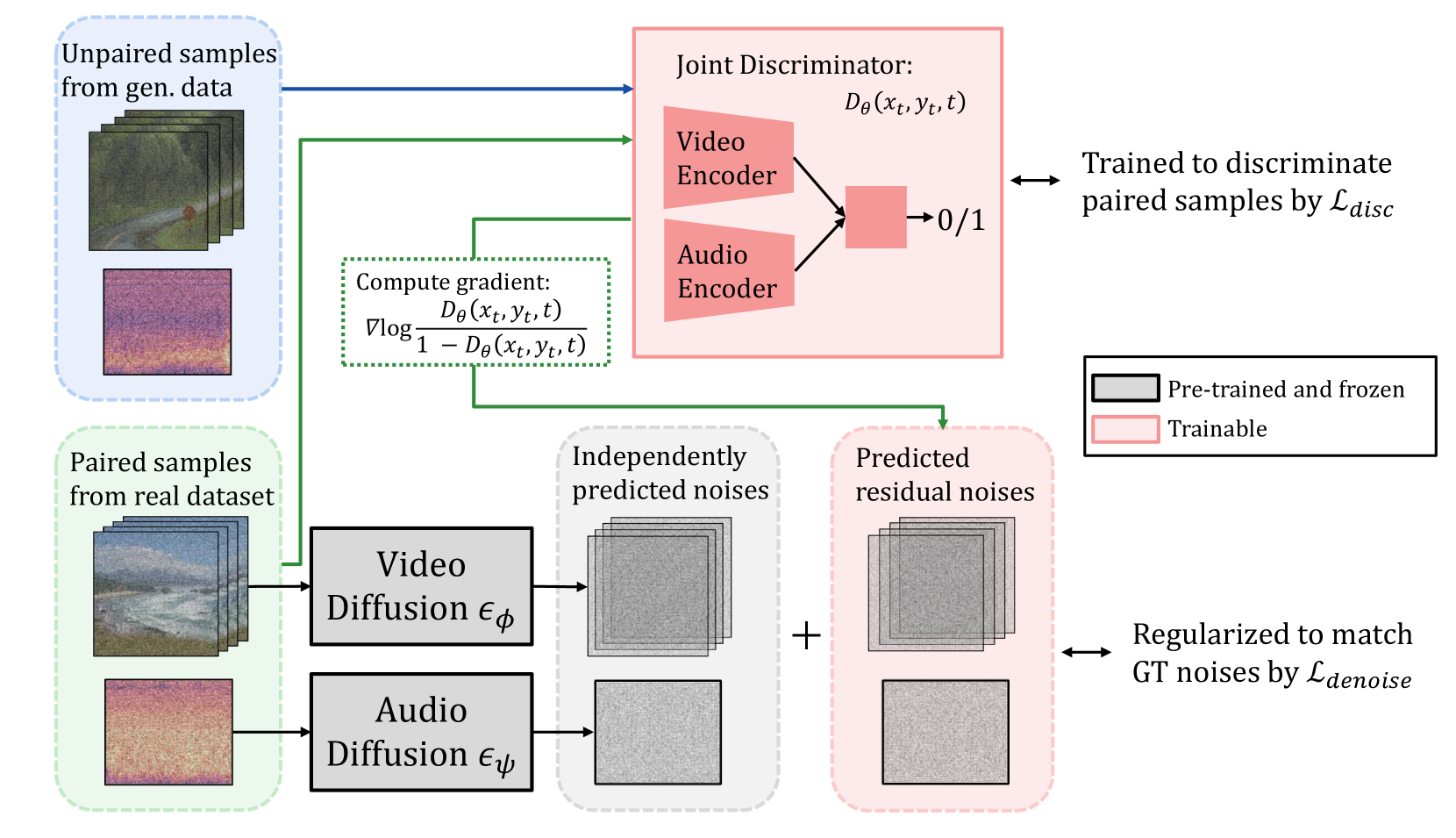
In this study, we aim to construct an audio-video generative model with minimal computational cost by leveraging pre-trained single-modal generative models for audio and video. To achieve this, we propose a novel method that guides each single-modal model to cooperatively generate well-aligned samples across modalities. Specifically, given two pre-trained base diffusion models, we train a lightweight joint guidance module to adjust scores separately estimated by the base models to match the score of joint distribution over audio and video. We theoretically show that this guidance can be computed through the gradient of the optimal discriminator distinguishing real audio-video pairs from fake ones independently generated by the base models. On the basis of this analysis, we construct the joint guidance module by training this discriminator. Additionally, we adopt a loss function to make the gradient of the discriminator work as a noise estimator, as in standard diffusion models, stabilizing the gradient of the discriminator. Empirical evaluations on several benchmark datasets demonstrate that our method improves both single-modal fidelity and multi-modal alignment with a relatively small number of parameters.
Read more5/29/2024