GNNavi: Navigating the Information Flow in Large Language Models by Graph Neural Network
2402.11709
0
0
💬
Abstract
Large Language Models (LLMs) exhibit strong In-Context Learning (ICL) capabilities when prompts with demonstrations are used. However, fine-tuning still remains crucial to further enhance their adaptability. Prompt-based fine-tuning proves to be an effective fine-tuning method in low-data scenarios, but high demands on computing resources limit its practicality. We address this issue by introducing a prompt-based parameter-efficient fine-tuning (PEFT) approach. GNNavi leverages insights into ICL's information flow dynamics, which indicates that label words act in prompts as anchors for information propagation. GNNavi employs a Graph Neural Network (GNN) layer to precisely guide the aggregation and distribution of information flow during the processing of prompts by hardwiring the desired information flow into the GNN. Our experiments on text classification tasks with GPT-2 and Llama2 show GNNavi surpasses standard prompt-based fine-tuning methods in few-shot settings by updating just 0.2% to 0.5% of parameters. We compare GNNavi with prevalent PEFT approaches, such as prefix tuning, LoRA and Adapter in terms of performance and efficiency. Our analysis reveals that GNNavi enhances information flow and ensures a clear aggregation process.
Create account to get full access
Overview
- Large Language Models (LLMs) exhibit strong In-Context Learning (ICL) capabilities when provided with demonstrations in prompts.
- Fine-tuning remains crucial to further enhance the adaptability of LLMs.
- Prompt-based fine-tuning is an effective method for low-data scenarios, but it is resource-intensive.
- The paper introduces GNNavi, a prompt-based parameter-efficient fine-tuning (PEFT) approach that addresses the high computing resource demands of traditional prompt-based fine-tuning.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models have an impressive ability to learn new tasks and adapt to different situations just by being given examples or "demonstrations" in the prompts they receive.
However, to truly excel at specific tasks, LLMs often need to be "fine-tuned" - that is, their internal parameters need to be adjusted through additional training. Traditional fine-tuning methods can be very computationally expensive, requiring a lot of time and computing power.
The researchers behind GNNavi have come up with a more efficient way to fine-tune LLMs using prompts. Their approach, called "prompt-based parameter-efficient fine-tuning" (PEFT), only requires updating a small fraction of the model's parameters (as little as 0.2% to 0.5%) to achieve significant performance improvements, especially in situations where there is limited training data available.
The key insight behind GNNavi is that the words used in the prompt as "labels" or examples play a crucial role in how information flows through the model during processing. By using a specialized graph neural network (GNN) layer, GNNavi can precisely control and optimize this information flow, leading to better performance with much fewer parameter updates.
Technical Explanation
The paper introduces GNNavi, a prompt-based parameter-efficient fine-tuning (PEFT) approach for large language models (LLMs). The researchers leverage insights into the information flow dynamics of in-context learning (ICL), where the label words in prompts act as anchors for information propagation.
GNNavi employs a Graph Neural Network (GNN) layer to precisely guide the aggregation and distribution of information flow during the processing of prompts. This GNN layer "hardwires" the desired information flow into the model, allowing for efficient fine-tuning with just 0.2% to 0.5% of the model's parameters updated.
The authors evaluate GNNavi on text classification tasks using GPT-2 and LLaMA2 models. They compare GNNavi's performance and efficiency against other PEFT approaches, such as prefix tuning, LoRA, and Adapters. The results show that GNNavi outperforms these methods in few-shot settings, demonstrating its ability to enhance information flow and ensure a clear aggregation process.
Critical Analysis
The paper presents a novel and promising approach to fine-tuning large language models using prompts in a parameter-efficient manner. The key strengths of the GNNavi method are its ability to significantly improve model performance with minimal parameter updates, as well as its strong performance in low-data scenarios.
However, the paper does not discuss the potential limitations or caveats of the GNNavi approach. For example, it would be valuable to understand how the method scales to larger language models or more complex tasks, and whether there are any trade-offs in terms of inference speed or model size. Additionally, the paper could benefit from a more thorough exploration of the internal mechanisms and information flow dynamics that underlie the GNNavi approach, to provide deeper insights into its workings.
Further research could also investigate the broader applicability of the GNNavi technique, such as its potential use in graph-based instruction tuning or automated data visualization tasks. Exploring the connections between GNNavi and other prompt-based fine-tuning or iterative forward tuning approaches could also yield valuable insights.
Conclusion
The GNNavi method presented in this paper offers a promising solution to the challenge of fine-tuning large language models in a parameter-efficient manner, particularly in low-data scenarios. By leveraging insights into the information flow dynamics of in-context learning, GNNavi is able to surpass the performance of other prompt-based fine-tuning approaches while only updating a tiny fraction of the model's parameters.
This research highlights the importance of understanding the underlying mechanisms that drive the success of language models and demonstrates how this knowledge can be leveraged to develop more efficient fine-tuning techniques. As the field of large language models continues to evolve, approaches like GNNavi may play a crucial role in making these powerful AI systems more accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Qi Zhu, Da Zheng, Xiang Song, Shichang Zhang, Bowen Jin, Yizhou Sun, George Karypis
0
0
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.
4/30/2024
In-Context Learning and Fine-Tuning GPT for Argument Mining
J'er'emie Cabessa, Hugo Hernault, Umer Mushtaq
0
0
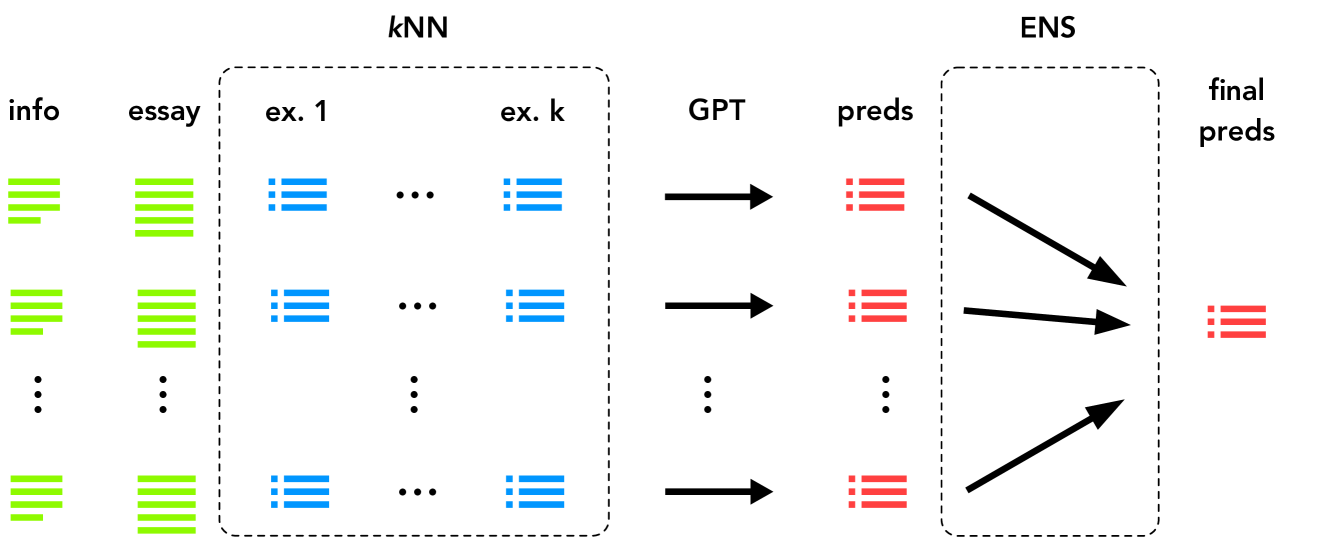
Large Language Models (LLMs) have become ubiquitous in NLP and deep learning. In-Context Learning (ICL) has been suggested as a bridging paradigm between the training-free and fine-tuning LLMs settings. In ICL, an LLM is conditioned to solve tasks by means of a few solved demonstration examples included as prompt. Argument Mining (AM) aims to extract the complex argumentative structure of a text, and Argument Type Classification (ATC) is an essential sub-task of AM. We introduce an ICL strategy for ATC combining kNN-based examples selection and majority vote ensembling. In the training-free ICL setting, we show that GPT-4 is able to leverage relevant information from only a few demonstration examples and achieve very competitive classification accuracy on ATC. We further set up a fine-tuning strategy incorporating well-crafted structural features given directly in textual form. In this setting, GPT-3.5 achieves state-of-the-art performance on ATC. Overall, these results emphasize the emergent ability of LLMs to grasp global discursive flow in raw text in both off-the-shelf and fine-tuned setups.
6/12/2024

GraphGPT: Graph Instruction Tuning for Large Language Models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, Chao Huang
0
0
Graph Neural Networks (GNNs) have evolved to understand graph structures through recursive exchanges and aggregations among nodes. To enhance robustness, self-supervised learning (SSL) has become a vital tool for data augmentation. Traditional methods often depend on fine-tuning with task-specific labels, limiting their effectiveness when labeled data is scarce. Our research tackles this by advancing graph model generalization in zero-shot learning environments. Inspired by the success of large language models (LLMs), we aim to create a graph-oriented LLM capable of exceptional generalization across various datasets and tasks without relying on downstream graph data. We introduce the GraphGPT framework, which integrates LLMs with graph structural knowledge through graph instruction tuning. This framework includes a text-graph grounding component to link textual and graph structures and a dual-stage instruction tuning approach with a lightweight graph-text alignment projector. These innovations allow LLMs to comprehend complex graph structures and enhance adaptability across diverse datasets and tasks. Our framework demonstrates superior generalization in both supervised and zero-shot graph learning tasks, surpassing existing benchmarks. The open-sourced model implementation of our GraphGPT is available at https://github.com/HKUDS/GraphGPT.
5/8/2024
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Yang Wu, Yao Wan, Hongyu Zhang, Yulei Sui, Wucai Wei, Wei Zhao, Guandong Xu, Hai Jin
0
0
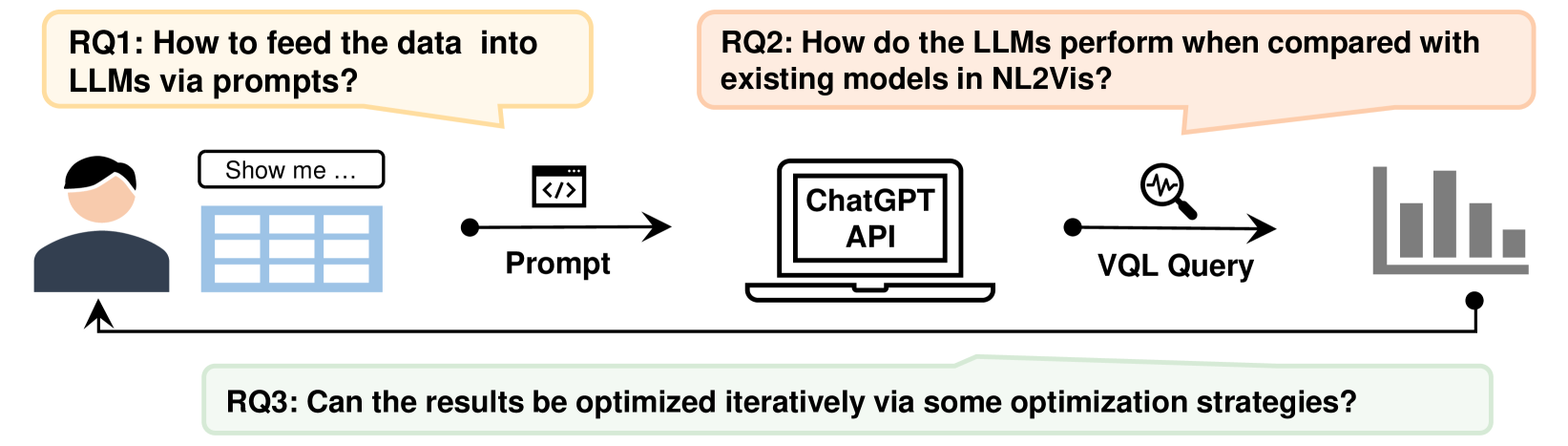
The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
4/29/2024