In-Context Learning and Fine-Tuning GPT for Argument Mining

0
Sign in to get full access
Overview
- This paper explores the use of in-context learning and fine-tuning of the GPT language model for the task of argument mining.
- Argument mining is the process of automatically identifying and extracting arguments from text, which is important for applications like summarization, debate analysis, and fact-checking.
- The researchers investigate how well GPT can perform argument mining through in-context learning (where the model learns from the provided task examples) and fine-tuning (where the model is further trained on a specific argument mining dataset).
Plain English Explanation
The researchers in this paper looked at using a large language model called GPT to do a task called "argument mining." Argument mining is the process of automatically finding and extracting arguments from text. This is useful for things like summarizing documents, analyzing debates, and verifying facts.
The key idea the researchers explored was using two different techniques with GPT to help it learn how to do argument mining:
-
In-context learning: Providing GPT with some example arguments and having it learn directly from those examples, without explicitly training it on a large dataset.
-
Fine-tuning: Taking a pre-trained GPT model and further training it on a specific argument mining dataset to improve its performance on that task.
The researchers wanted to see how well these two techniques could work for argument mining, and what the tradeoffs might be between the two approaches.
Technical Explanation
The paper first discusses the task of argument mining and how it can be approached using large language models like GPT.
To evaluate GPT's performance on argument mining, the researchers used two main techniques:
-
In-context learning: They provided GPT with a few examples of argument-annotated text, and had it learn to identify arguments directly from those examples, without any explicit training.
-
Fine-tuning: They took a pre-trained GPT model and fine-tuned it on a specific argument mining dataset, to see if that could improve its performance on the task.
The researchers conducted experiments on several argument mining datasets to compare the effectiveness of these two techniques. They found that in-context learning can enable GPT to perform reasonably well on argument mining, but fine-tuning generally led to better overall performance.
The paper also discusses the limitations of both approaches, such as the fact that in-context learning performance can be sensitive to the specific examples provided, and fine-tuning requires access to a suitable training dataset.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work. For example, they note that the performance of in-context learning can be quite sensitive to the specific examples used, and that fine-tuning requires access to a suitable argument mining dataset, which may not always be available.
Additionally, the researchers did not explore the robustness of the fine-tuned GPT model to distributional shift or adversarial attacks, which is an important consideration for real-world deployment. Further research could investigate the ability of these techniques to generalize to out-of-distribution data or handle adversarial inputs.
It would also be interesting to see how other techniques, such as prompt engineering or the use of syntactic information, could be combined with in-context learning and fine-tuning to further improve argument mining performance.
Conclusion
This paper explores the use of in-context learning and fine-tuning of the GPT language model for the task of argument mining. The researchers found that both techniques can be effective, with fine-tuning generally outperforming in-context learning, but with some important caveats and limitations.
The work highlights the potential of large language models like GPT for argument mining, but also the need for further research to improve the robustness and generalization of these techniques. As argument mining becomes increasingly important for applications like summarization, debate analysis, and fact-checking, continued advancements in this area could have significant real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Context Learning and Fine-Tuning GPT for Argument Mining
J'er'emie Cabessa, Hugo Hernault, Umer Mushtaq
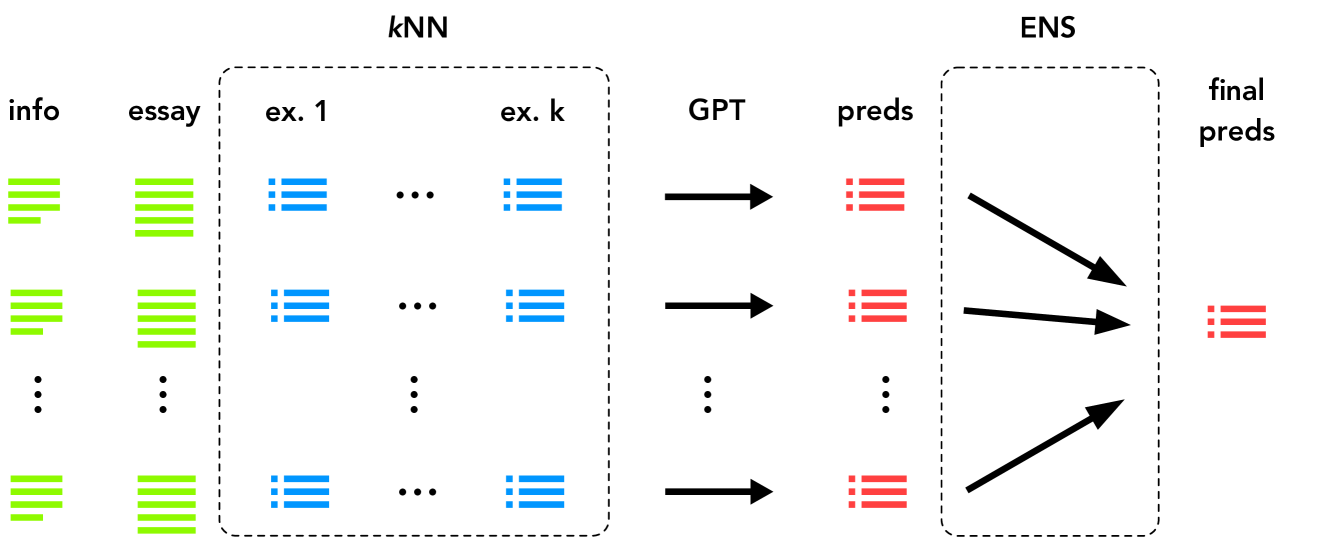
Large Language Models (LLMs) have become ubiquitous in NLP and deep learning. In-Context Learning (ICL) has been suggested as a bridging paradigm between the training-free and fine-tuning LLMs settings. In ICL, an LLM is conditioned to solve tasks by means of a few solved demonstration examples included as prompt. Argument Mining (AM) aims to extract the complex argumentative structure of a text, and Argument Type Classification (ATC) is an essential sub-task of AM. We introduce an ICL strategy for ATC combining kNN-based examples selection and majority vote ensembling. In the training-free ICL setting, we show that GPT-4 is able to leverage relevant information from only a few demonstration examples and achieve very competitive classification accuracy on ATC. We further set up a fine-tuning strategy incorporating well-crafted structural features given directly in textual form. In this setting, GPT-3.5 achieves state-of-the-art performance on ATC. Overall, these results emphasize the emergent ability of LLMs to grasp global discursive flow in raw text in both off-the-shelf and fine-tuned setups.
Read more6/12/2024
🌿
0
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
Read more9/30/2024
📈
0
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
Read more6/6/2024
🌀
0
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
Read more4/11/2024