GPT-4 passes most of the 297 written Polish Board Certification Examinations
2405.01589
1
0
🔮
Abstract
Introduction: Recently, the effectiveness of Large Language Models (LLMs) has increased rapidly, allowing them to be used in a great number of applications. However, the risks posed by the generation of false information through LLMs significantly limit their applications in sensitive areas such as healthcare, highlighting the necessity for rigorous validations to determine their utility and reliability. To date, no study has extensively compared the performance of LLMs on Polish medical examinations across a broad spectrum of specialties on a very large dataset. Objectives: This study evaluated the performance of three Generative Pretrained Transformer (GPT) models on the Polish Board Certification Exam (Pa'nstwowy Egzamin Specjalizacyjny, PES) dataset, which consists of 297 tests. Methods: We developed a software program to download and process PES exams and tested the performance of GPT models using OpenAI Application Programming Interface. Results: Our findings reveal that GPT-3.5 did not pass any of the analyzed exams. In contrast, the GPT-4 models demonstrated the capability to pass the majority of the exams evaluated, with the most recent model, gpt-4-0125, successfully passing 222 (75%) of them. The performance of the GPT models varied significantly, displaying excellence in exams related to certain specialties while completely failing others. Conclusions: The significant progress and impressive performance of LLM models hold great promise for the increased application of AI in the field of medicine in Poland. For instance, this advancement could lead to the development of AI-based medical assistants for healthcare professionals, enhancing the efficiency and accuracy of medical services.
Create account to get full access
Overview
- Recent advancements in Large Language Models (LLMs) have significantly improved their capabilities, enabling their use in various applications.
- However, the risks of generating false information through LLMs limit their applications in sensitive areas like healthcare, underscoring the need for rigorous validation.
- This study extensively evaluated the performance of three Generative Pretrained Transformer (GPT) models on the Polish Board Certification Exam (PES) dataset, a large dataset of 297 medical exams.
Plain English Explanation
Large Language Models (LLMs) are a type of artificial intelligence that can generate human-like text. They have become increasingly capable in recent years, allowing them to be used in a wide range of applications. However, there is a concern that these models could be used to create false information, which could be particularly problematic in sensitive areas like healthcare.
To address this issue, the researchers in this study tested the performance of three different GPT models, a type of LLM, on a large dataset of Polish medical exams. The dataset, called the Polish Board Certification Exam (PES), consists of 297 exams covering a variety of medical specialties. The researchers wanted to see how well these AI models could perform on these challenging medical tests.
Technical Explanation
The researchers developed a software program to download and process the PES exam dataset. They then used the OpenAI API to test the performance of three different GPT models: GPT-3.5, GPT-4, and the most recent GPT-4-0125.
The results showed that the GPT-3.5 model was unable to pass any of the exams. In contrast, the GPT-4 models demonstrated a much stronger performance, with the latest GPT-4-0125 model successfully passing 222 (75%) of the 297 exams.
However, the performance of the GPT models varied significantly across different medical specialties. While they excelled in some exam areas, they completely failed in others.
Critical Analysis
The research highlights the impressive progress made in LLM models, such as GPT-4, which can outperform experts in certain tasks. This advancement could potentially lead to the development of AI-based medical assistants that could enhance the efficiency and accuracy of healthcare services in Poland.
At the same time, the significant variation in performance across different medical specialties suggests that these models may not be reliable or accurate enough to be used in high-stakes healthcare settings without further validation and safeguards. The researchers note that the risks of generating false information through LLMs still need to be addressed before these models can be widely deployed in sensitive domains like medicine.
Additionally, the study is limited to the Polish medical exam dataset, and it's unclear how well the GPT models would perform on medical exams in other languages or contexts. Expanding the analysis to a more diverse set of medical datasets could provide a more comprehensive understanding of the capabilities and limitations of these models.
Conclusion
This study demonstrates the significant progress made in LLM models, such as GPT-4, which can now pass the majority of Polish medical board exams. This advancement holds great promise for the increased application of AI in the field of medicine in Poland, potentially leading to the development of AI-based medical assistants that could enhance the efficiency and accuracy of healthcare services.
However, the study also highlights the need for continued validation and safeguards to ensure the reliability and accuracy of these models, particularly in sensitive domains like healthcare. Further research is needed to understand the full capabilities and limitations of LLMs across different medical specialties and languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Fan Gao, Hang Jiang, Rui Yang, Qingcheng Zeng, Jinghui Lu, Moritz Blum, Dairui Liu, Tianwei She, Yuang Jiang, Irene Li
0
0
Educational materials such as survey articles in specialized fields like computer science traditionally require tremendous expert inputs and are therefore expensive to create and update. Recently, Large Language Models (LLMs) have achieved significant success across various general tasks. However, their effectiveness and limitations in the education domain are yet to be fully explored. In this work, we examine the proficiency of LLMs in generating succinct survey articles specific to the niche field of NLP in computer science, focusing on a curated list of 99 topics. Automated benchmarks reveal that GPT-4 surpasses its predecessors, inluding GPT-3.5, PaLM2, and LLaMa2 by margins ranging from 2% to 20% in comparison to the established ground truth. We compare both human and GPT-based evaluation scores and provide in-depth analysis. While our findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, certain limitations were observed. Notably, GPT-4, despite often delivering outstanding content, occasionally exhibited lapses like missing details or factual errors. At last, we compared the rating behavior between humans and GPT-4 and found systematic bias in using GPT evaluation.
5/24/2024

Are Large Language Models True Healthcare Jacks-of-All-Trades? Benchmarking Across Health Professions Beyond Physician Exams
Zheheng Luo, Chenhan Yuan, Qianqian Xie, Sophia Ananiadou
0
0
Recent advancements in Large Language Models (LLMs) have demonstrated their potential in delivering accurate answers to questions about world knowledge. Despite this, existing benchmarks for evaluating LLMs in healthcare predominantly focus on medical doctors, leaving other critical healthcare professions underrepresented. To fill this research gap, we introduce the Examinations for Medical Personnel in Chinese (EMPEC), a pioneering large-scale healthcare knowledge benchmark in traditional Chinese. EMPEC consists of 157,803 exam questions across 124 subjects and 20 healthcare professions, including underrepresented occupations like Optometrists and Audiologists. Each question is tagged with its release time and source, ensuring relevance and authenticity. We conducted extensive experiments on 17 LLMs, including proprietary, open-source models, general domain models and medical specific models, evaluating their performance under various settings. Our findings reveal that while leading models like GPT-4 achieve over 75% accuracy, they still struggle with specialized fields and alternative medicine. Surprisingly, general-purpose LLMs outperformed medical-specific models, and incorporating EMPEC's training data significantly enhanced performance. Additionally, the results on questions released after the models' training cutoff date were consistent with overall performance trends, suggesting that the models' performance on the test set can predict their effectiveness in addressing unseen healthcare-related queries. The transition from traditional to simplified Chinese characters had a negligible impact on model performance, indicating robust linguistic versatility. Our study underscores the importance of expanding benchmarks to cover a broader range of healthcare professions to better assess the applicability of LLMs in real-world healthcare scenarios.
6/18/2024
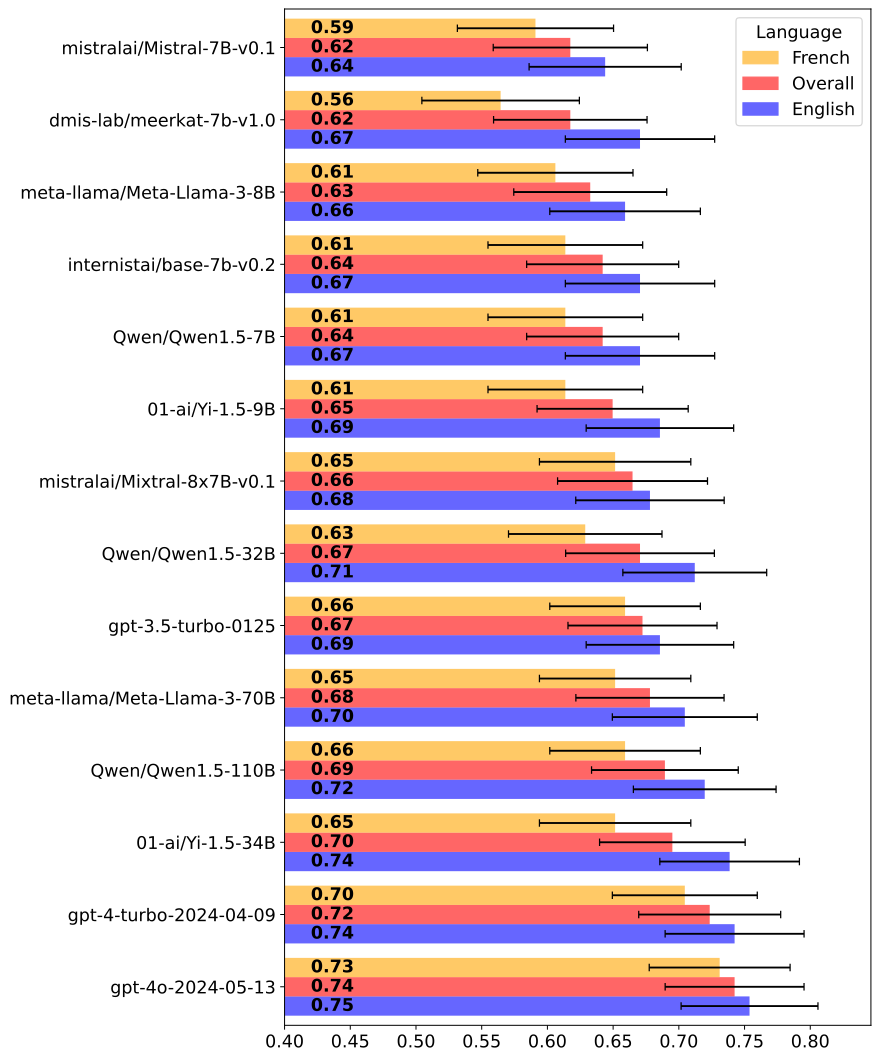
Multiple Choice Questions and Large Languages Models: A Case Study with Fictional Medical Data
Maxime Griot, Jean Vanderdonckt, Demet Yuksel, Coralie Hemptinne
0
0
Large Language Models (LLMs) like ChatGPT demonstrate significant potential in the medical field, often evaluated using multiple-choice questions (MCQs) similar to those found on the USMLE. Despite their prevalence in medical education, MCQs have limitations that might be exacerbated when assessing LLMs. To evaluate the effectiveness of MCQs in assessing the performance of LLMs, we developed a fictional medical benchmark focused on a non-existent gland, the Glianorex. This approach allowed us to isolate the knowledge of the LLM from its test-taking abilities. We used GPT-4 to generate a comprehensive textbook on the Glianorex in both English and French and developed corresponding multiple-choice questions in both languages. We evaluated various open-source, proprietary, and domain-specific LLMs using these questions in a zero-shot setting. The models achieved average scores around 67%, with minor performance differences between larger and smaller models. Performance was slightly higher in English than in French. Fine-tuned medical models showed some improvement over their base versions in English but not in French. The uniformly high performance across models suggests that traditional MCQ-based benchmarks may not accurately measure LLMs' clinical knowledge and reasoning abilities, instead highlighting their pattern recognition skills. This study underscores the need for more robust evaluation methods to better assess the true capabilities of LLMs in medical contexts.
6/5/2024
💬
Digital Diagnostics: The Potential Of Large Language Models In Recognizing Symptoms Of Common Illnesses
Gaurav Kumar Gupta, Aditi Singh, Sijo Valayakkad Manikandan, Abul Ehtesham
0
0
The recent swift development of LLMs like GPT-4, Gemini, and GPT-3.5 offers a transformative opportunity in medicine and healthcare, especially in digital diagnostics. This study evaluates each model diagnostic abilities by interpreting a user symptoms and determining diagnoses that fit well with common illnesses, and it demonstrates how each of these models could significantly increase diagnostic accuracy and efficiency. Through a series of diagnostic prompts based on symptoms from medical databases, GPT-4 demonstrates higher diagnostic accuracy from its deep and complete history of training on medical data. Meanwhile, Gemini performs with high precision as a critical tool in disease triage, demonstrating its potential to be a reliable model when physicians are trying to make high-risk diagnoses. GPT-3.5, though slightly less advanced, is a good tool for medical diagnostics. This study highlights the need to study LLMs for healthcare and clinical practices with more care and attention, ensuring that any system utilizing LLMs promotes patient privacy and complies with health information privacy laws such as HIPAA compliance, as well as the social consequences that affect the varied individuals in complex healthcare contexts. This study marks the start of a larger future effort to study the various ways in which assigning ethical concerns to LLMs task of learning from human biases could unearth new ways to apply AI in complex medical settings.
5/14/2024