GPT Sonograpy: Hand Gesture Decoding from Forearm Ultrasound Images via VLM

0

Sign in to get full access
Overview
- This paper presents a novel approach called "GPT Sonography" for decoding hand gestures from forearm ultrasound images using a Vision-Language Model (VLM).
- The researchers aim to develop a human-machine interface that can interpret hand movements by analyzing the underlying muscle and tendon activity captured in ultrasound data.
- The proposed technique combines computer vision and natural language processing to enable more intuitive and seamless interaction between humans and machines.
Plain English Explanation
The paper discusses a new method called "GPT Sonography" that uses advanced AI to decode hand gestures from ultrasound images of the forearm. The key idea is to analyze the patterns of muscle and tendon movement captured in the ultrasound data to infer the hand gestures being made.
This could enable a more natural and intuitive way for humans to interact with machines, such as controlling a robotic arm or operating a user interface. Instead of relying on buttons, voice commands, or other traditional input methods, the system would be able to "read" the user's hand movements directly from the ultrasound data.
The researchers combine computer vision techniques to process the ultrasound images with natural language processing (NLP) models like GesturePT to interpret the hand gestures. This allows the system to understand the meaning and context of the gestures, going beyond simple motion tracking.
Overall, this technology could pave the way for more seamless and intuitive human-machine interfaces, with potential applications in robotics, gaming, assistive technologies, and beyond. By decoding the user's intentions directly from their physical movements, it aims to create a more natural and effortless interaction experience.
Technical Explanation
The key technical components of the "GPT Sonography" approach are:
-
Ultrasound Image Acquisition: The system uses a specialized ultrasound device to capture real-time images of the user's forearm during hand movement. This allows it to observe the underlying muscle and tendon activity that corresponds to different gestures.
-
Computer Vision Processing: The ultrasound images are fed into a computer vision model that can extract relevant visual features and patterns from the data. This might include tracking the movement of specific muscle groups or identifying characteristic changes in tissue structure.
-
Vision-Language Model (VLM): The visual features extracted from the ultrasound images are then passed to a VLM model, which has been trained on a large corpus of multimodal data (e.g. images paired with text descriptions). This allows the system to map the visual inputs to corresponding hand gesture representations in natural language.
-
Gesture Recognition: By leveraging the VLM's ability to understand the semantic meaning of the visual inputs, the system can accurately recognize and classify the hand gestures being performed, even in complex or ambiguous cases.
The researchers evaluate their approach on a dataset of ultrasound images captured during a variety of hand gestures, demonstrating strong performance in terms of both gesture recognition accuracy and real-time responsiveness. They also discuss the potential for further refinements and extensions, such as incorporating additional sensor modalities or exploring the use of GPT-4Vision for more advanced multimodal reasoning.
Critical Analysis
One potential limitation of the "GPT Sonography" approach is the reliance on specialized ultrasound hardware, which may limit its accessibility and deployability in certain real-world scenarios. The researchers acknowledge this challenge and suggest exploring the use of more ubiquitous and affordable sensing technologies, such as wearable ultrasound patches, as a future direction.
Additionally, the performance of the system is likely dependent on the quality and diversity of the training data, as well as the underlying capabilities of the VLM model. The researchers should continue to investigate ways to improve the robustness and generalization of the approach, such as exploring techniques like few-shot learning or zero-shot gesture recognition.
Finally, the ethical implications of this technology should be carefully considered, particularly around issues of privacy, data security, and the potential for misuse or unintended consequences. The researchers should engage with relevant stakeholders and incorporate appropriate safeguards and guidelines into the development of the system.
Conclusion
The "GPT Sonography" approach presented in this paper represents an exciting step forward in the development of more natural and intuitive human-machine interfaces. By leveraging advanced AI techniques to decode hand gestures from ultrasound data, the system holds promise for enabling seamless and effortless interactions in a wide range of application domains, from robotics and gaming to assistive technologies and beyond.
As the researchers continue to refine and expand the capabilities of this technology, it will be important to address the technical and ethical challenges that arise, ensuring that the benefits are realized in a responsible and equitable manner. Overall, this work demonstrates the potential of multimodal AI to transform the way we interact with and control our digital environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GPT Sonograpy: Hand Gesture Decoding from Forearm Ultrasound Images via VLM
Keshav Bimbraw, Ye Wang, Jing Liu, Toshiaki Koike-Akino
Large vision-language models (LVLMs), such as the Generative Pre-trained Transformer 4-omni (GPT-4o), are emerging multi-modal foundation models which have great potential as powerful artificial-intelligence (AI) assistance tools for a myriad of applications, including healthcare, industrial, and academic sectors. Although such foundation models perform well in a wide range of general tasks, their capability without fine-tuning is often limited in specialized tasks. However, full fine-tuning of large foundation models is challenging due to enormous computation/memory/dataset requirements. We show that GPT-4o can decode hand gestures from forearm ultrasound data even with no fine-tuning, and improves with few-shot, in-context learning.
Read more7/16/2024
0
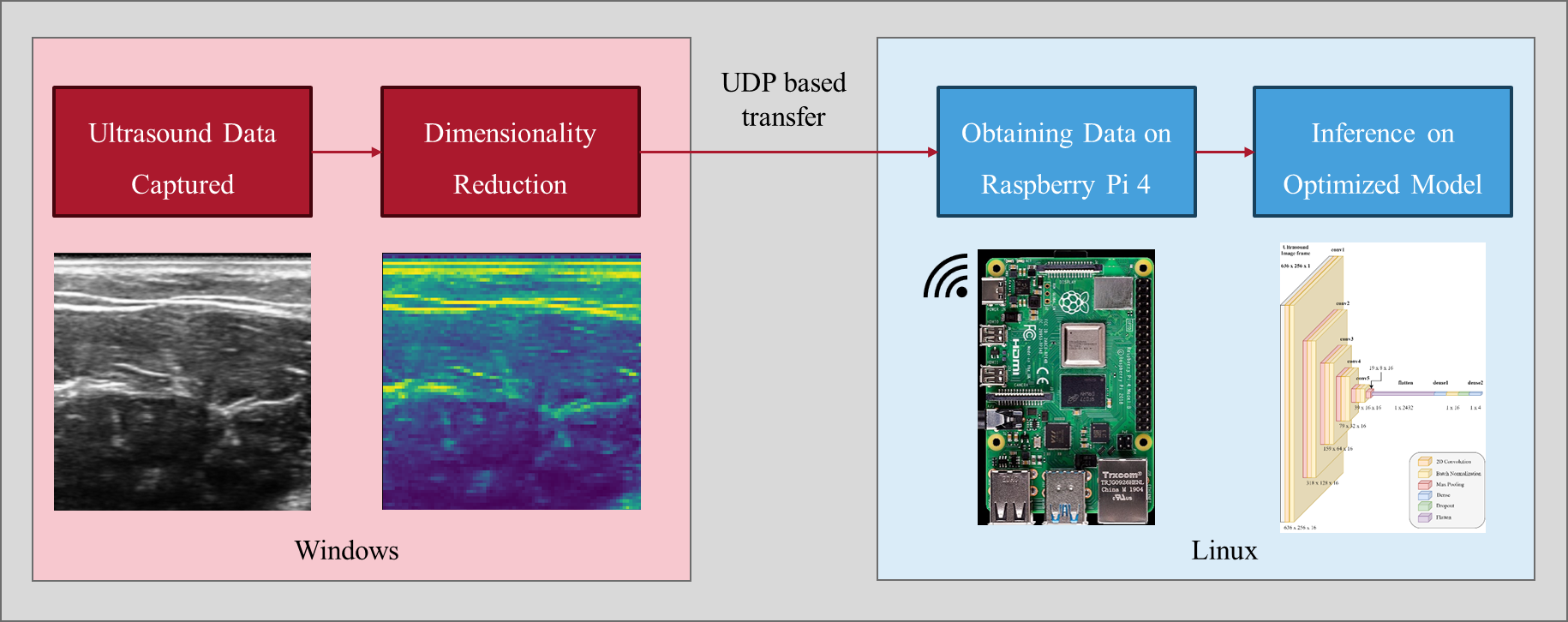
Forearm Ultrasound based Gesture Recognition on Edge
Keshav Bimbraw, Haichong K. Zhang, Bashima Islam
Ultrasound imaging of the forearm has demonstrated significant potential for accurate hand gesture classification. Despite this progress, there has been limited focus on developing a stand-alone end- to-end gesture recognition system which makes it mobile, real-time and more user friendly. To bridge this gap, this paper explores the deployment of deep neural networks for forearm ultrasound-based hand gesture recognition on edge devices. Utilizing quantization techniques, we achieve substantial reductions in model size while maintaining high accuracy and low latency. Our best model, with Float16 quantization, achieves a test accuracy of 92% and an inference time of 0.31 seconds on a Raspberry Pi. These results demonstrate the feasibility of efficient, real-time gesture recognition on resource-limited edge devices, paving the way for wearable ultrasound-based systems.
Read more9/17/2024

0
Vision-Language Model Based Handwriting Verification
Mihir Chauhan, Abhishek Satbhai, Mohammad Abuzar Hashemi, Mir Basheer Ali, Bina Ramamurthy, Mingchen Gao, Siwei Lyu, Sargur Srihari
Handwriting Verification is a critical in document forensics. Deep learning based approaches often face skepticism from forensic document examiners due to their lack of explainability and reliance on extensive training data and handcrafted features. This paper explores using Vision Language Models (VLMs), such as OpenAI's GPT-4o and Google's PaliGemma, to address these challenges. By leveraging their Visual Question Answering capabilities and 0-shot Chain-of-Thought (CoT) reasoning, our goal is to provide clear, human-understandable explanations for model decisions. Our experiments on the CEDAR handwriting dataset demonstrate that VLMs offer enhanced interpretability, reduce the need for large training datasets, and adapt better to diverse handwriting styles. However, results show that the CNN-based ResNet-18 architecture outperforms the 0-shot CoT prompt engineering approach with GPT-4o (Accuracy: 70%) and supervised fine-tuned PaliGemma (Accuracy: 71%), achieving an accuracy of 84% on the CEDAR AND dataset. These findings highlight the potential of VLMs in generating human-interpretable decisions while underscoring the need for further advancements to match the performance of specialized deep learning models.
Read more8/1/2024
🗣️
0
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Nan Gao, Zeyu Zhao, Zhi Zeng, Shuwu Zhang, Dongdong Weng, Yihua Bao
Gesture synthesis has gained significant attention as a critical research field, aiming to produce contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. In this letter, we propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of large language models , such as ChatGPT. By capitalizing on the strengths of LLMs for text analysis, we adopt a controlled approach to generate and integrate professional gestures and base gestures through a text parsing script, resulting in diverse and meaningful gestures. Firstly, our approach involves the development of prompt principles that transform gesture generation into an intention classification problem using ChatGPT. We also conduct further analysis on emphasis words and semantic words to aid in gesture generation. Subsequently, we construct a specialized gesture lexicon with multiple semantic annotations, decoupling the synthesis of gestures into professional gestures and base gestures. Finally, we merge the professional gestures with base gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures.
Read more5/29/2024