An Early Investigation into the Utility of Multimodal Large Language Models in Medical Imaging
2406.00667
0
0

Abstract
Recent developments in multimodal large language models (MLLMs) have spurred significant interest in their potential applications across various medical imaging domains. On the one hand, there is a temptation to use these generative models to synthesize realistic-looking medical image data, while on the other hand, the ability to identify synthetic image data in a pool of data is also significantly important. In this study, we explore the potential of the Gemini (textit{gemini-1.0-pro-vision-latest}) and GPT-4V (gpt-4-vision-preview) models for medical image analysis using two modalities of medical image data. Utilizing synthetic and real imaging data, both Gemini AI and GPT-4V are first used to classify real versus synthetic images, followed by an interpretation and analysis of the input images. Experimental results demonstrate that both Gemini and GPT-4 could perform some interpretation of the input images. In this specific experiment, Gemini was able to perform slightly better than the GPT-4V on the classification task. In contrast, responses associated with GPT-4V were mostly generic in nature. Our early investigation presented in this work provides insights into the potential of MLLMs to assist with the classification and interpretation of retinal fundoscopy and lung X-ray images. We also identify key limitations associated with the early investigation study on MLLMs for specialized tasks in medical image analysis.
Create account to get full access
Overview
- This paper explores the utility of multimodal large language models (LLMs) in medical imaging applications.
- It investigates the performance of Gemini AI, a multimodal LLM, in tasks such as retinal disease classification and lung disease detection.
- The researchers aim to understand the capabilities and limitations of these models in the medical imaging domain.
Plain English Explanation
Large language models (LLMs) like ChatGPT have shown impressive abilities in understanding and generating human language. Multimodal LLMs, like Gemini AI, can also process and understand visual information along with text.
In this study, the researchers wanted to see how well these multimodal LLMs could perform on medical imaging tasks, such as identifying signs of eye diseases in retinal scans or lung diseases in chest X-rays. They used Gemini AI, a state-of-the-art multimodal LLM, to test its capabilities in these medical imaging applications.
The key idea is that if these powerful language models can also understand and analyze medical images, they could potentially be used to assist doctors and radiologists in diagnosing diseases more accurately and efficiently. This could lead to improved digital diagnostics and better healthcare outcomes for patients.
Technical Explanation
The researchers used Gemini AI, a multimodal large language model that can process both text and images, to evaluate its performance on two medical imaging tasks: retinal disease classification and lung disease detection.
For the retinal disease task, they fine-tuned Gemini AI on a dataset of retinal fundus images labeled with different eye diseases. The model was then tested on its ability to correctly classify the retinal images into the appropriate disease categories.
In the lung disease detection task, the researchers used Gemini AI to analyze chest X-ray images and detect the presence of various lung pathologies, such as pneumonia, tuberculosis, and lung cancer. The model's performance was assessed based on its ability to accurately identify the correct lung conditions.
The results of these experiments showed that Gemini AI was able to achieve promising performance on both medical imaging tasks, demonstrating the potential of multimodal LLMs in the medical domain. The researchers also explored the model's interpretability by analyzing the attention maps and feature representations learned by Gemini AI during the medical image analysis.
Critical Analysis
The paper provides an early and exploratory investigation into the utility of multimodal LLMs in medical imaging, and the results are generally promising. However, the researchers acknowledge several limitations and areas for further research.
One key limitation is the relatively small size of the medical imaging datasets used in the experiments. Larger and more diverse datasets would be needed to fully assess the model's performance and generalization capabilities in real-world clinical settings.
Additionally, the paper does not delve deeply into the model's interpretability and the extent to which its decision-making processes are transparent and explainable to medical professionals. Improving the interpretability of these models is crucial for building trust and facilitating their adoption in clinical practice.
Further research is also needed to understand the specific strengths and weaknesses of multimodal LLMs compared to other AI-based medical imaging techniques, such as convolutional neural networks. Comparative studies could provide valuable insights into the most effective approaches for leveraging these models in the medical domain.
Conclusion
This paper represents an early but promising investigation into the utility of multimodal large language models, such as Gemini AI, in the field of medical imaging. The results suggest that these powerful models have the potential to assist doctors and radiologists in tasks like disease classification and detection, potentially leading to improved digital diagnostics and better healthcare outcomes for patients.
However, the researchers also identify several areas for further research and development, including the need for larger and more diverse medical imaging datasets, as well as a deeper understanding of the models' interpretability and their performance relative to other AI-based approaches. Nonetheless, this study lays the groundwork for exploring the exciting possibilities of applying multimodal LLMs in the medical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Junying Chen, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, Guangjun Yu, Xiang Wan, Benyou Wang
0
0
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
6/28/2024

Evaluating the Efficacy of Prompt-Engineered Large Multimodal Models Versus Fine-Tuned Vision Transformers in Image-Based Security Applications
Fouad Trad, Ali Chehab
0
0
The success of Large Language Models (LLMs) has led to a parallel rise in the development of Large Multimodal Models (LMMs), which have begun to transform a variety of applications. These sophisticated multimodal models are designed to interpret and analyze complex data by integrating multiple modalities such as text and images, thereby opening new avenues for a range of applications. This paper investigates the applicability and effectiveness of prompt-engineered LMMs that process both images and text, including models such as LLaVA, BakLLaVA, Moondream, Gemini-pro-vision, and GPT-4o, compared to fine-tuned Vision Transformer (ViT) models in addressing critical security challenges. We focus on two distinct security tasks: 1) a visually evident task of detecting simple triggers, such as small pixel variations in images that could be exploited to access potential backdoors in the models, and 2) a visually non-evident task of malware classification through visual representations. In the visually evident task, some LMMs, such as Gemini-pro-vision and GPT-4o, have demonstrated the potential to achieve good performance with careful prompt engineering, with GPT-4o achieving the highest accuracy and F1-score of 91.9% and 91%, respectively. However, the fine-tuned ViT models exhibit perfect performance in this task due to its simplicity. For the visually non-evident task, the results highlight a significant divergence in performance, with ViT models achieving F1-scores of 97.11% in predicting 25 malware classes and 97.61% in predicting 5 malware families, whereas LMMs showed suboptimal performance despite iterative prompt improvements. This study not only showcases the strengths and limitations of prompt-engineered LMMs in cybersecurity applications but also emphasizes the unmatched efficacy of fine-tuned ViT models for precise and dependable tasks.
6/11/2024
💬
A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
Hanguang Xiao, Feizhong Zhou, Xingyue Liu, Tianqi Liu, Zhipeng Li, Xin Liu, Xiaoxuan Huang
0
0
Since the release of ChatGPT and GPT-4, large language models (LLMs) and multimodal large language models (MLLMs) have garnered significant attention due to their powerful and general capabilities in understanding, reasoning, and generation, thereby offering new paradigms for the integration of artificial intelligence with medicine. This survey comprehensively overviews the development background and principles of LLMs and MLLMs, as well as explores their application scenarios, challenges, and future directions in medicine. Specifically, this survey begins by focusing on the paradigm shift, tracing the evolution from traditional models to LLMs and MLLMs, summarizing the model structures to provide detailed foundational knowledge. Subsequently, the survey details the entire process from constructing and evaluating to using LLMs and MLLMs with a clear logic. Following this, to emphasize the significant value of LLMs and MLLMs in healthcare, we survey and summarize 6 promising applications in healthcare. Finally, the survey discusses the challenges faced by medical LLMs and MLLMs and proposes a feasible approach and direction for the subsequent integration of artificial intelligence with medicine. Thus, this survey aims to provide researchers with a valuable and comprehensive reference guide from the perspectives of the background, principles, and clinical applications of LLMs and MLLMs.
5/15/2024
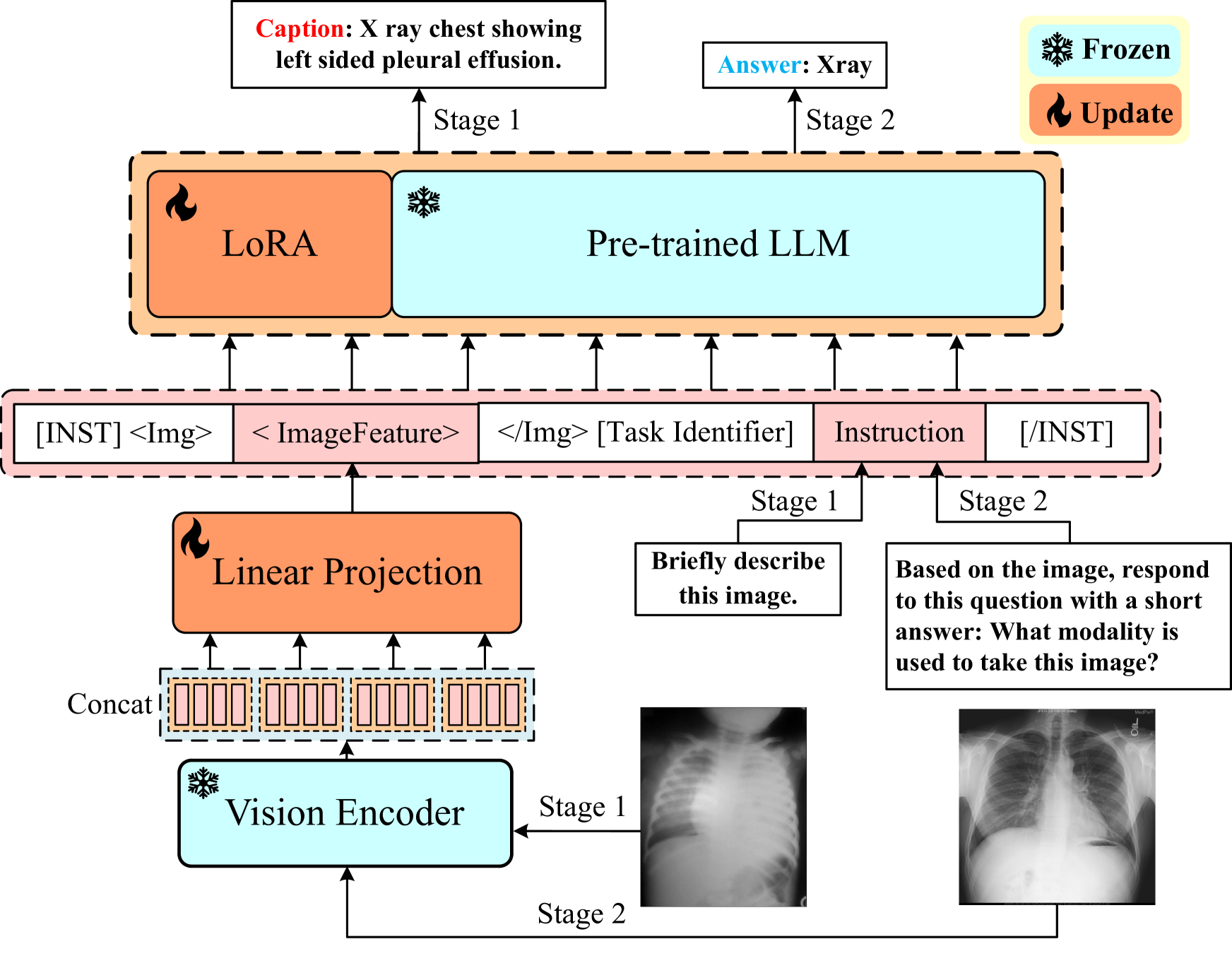
PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
Gang Liu, Jinlong He, Pengfei Li, Genrong He, Zhaolin Chen, Shenjun Zhong
0
0
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our fine-tuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
4/17/2024