Comparing Retrieval-Augmentation and Parameter-Efficient Fine-Tuning for Privacy-Preserving Personalization of Large Language Models

0

Sign in to get full access
Overview
- This paper compares two approaches for personalizing large language models while preserving privacy: retrieval-augmentation and parameter-efficient fine-tuning.
- The researchers conducted experiments to evaluate the performance and efficiency of these methods for personalization tasks.
- The findings offer insights into the trade-offs between these techniques and their suitability for different applications.
Plain English Explanation
Large language models like GPT-3 are powerful AI systems that can generate human-like text. However, these models are trained on vast amounts of online data, which can raise privacy concerns. To address this, researchers have explored ways to personalize language models while protecting an individual's private information.
This paper compares two approaches for personalization: retrieval-augmentation and parameter-efficient fine-tuning.
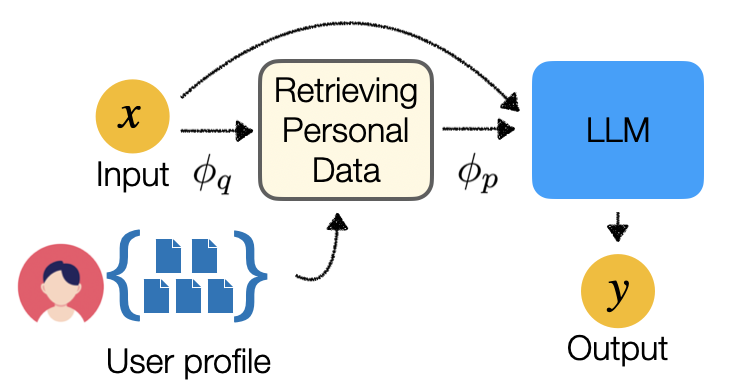
Retrieval-augmentation involves supplementing the model's knowledge with relevant information retrieved from a private database, rather than modifying the model's parameters. This allows the model to learn personalized responses without directly updating its internal structure.
Parameter-efficient fine-tuning, on the other hand, focuses on updating only a small number of the model's parameters, rather than the full set. This reduces the number of trainable weights, which can help preserve privacy and efficiency.
The researchers conducted experiments to evaluate the performance and efficiency of these methods on personalization tasks. They found that both approaches can effectively personalize language models while offering different trade-offs in terms of accuracy, efficiency, and privacy preservation.
Technical Explanation
The paper introduces two privacy-preserving techniques for personalizing large language models:
-
Retrieval-Augmentation: This approach supplements the language model's knowledge with relevant information retrieved from a private database, rather than modifying the model's parameters. The researchers use a dual-encoder architecture to retrieve the most relevant passages from the private database and incorporate them into the language model's output.
-
Parameter-Efficient Fine-Tuning (PEFT): This method updates only a small subset of the language model's parameters, rather than the full set, during the personalization process. The researchers experiment with several PEFT techniques, including prefix-tuning, prompt-tuning, and adapter-tuning, to identify the most effective approach.
The researchers conducted experiments to evaluate the performance and efficiency of these personalization methods on several tasks, including language modeling, sentiment analysis, and question answering. They compared the techniques in terms of task performance, parameter efficiency, and privacy preservation.
The results demonstrate that both retrieval-augmentation and PEFT can effectively personalize language models while offering different trade-offs. Retrieval-augmentation achieves strong performance but requires maintaining a private database, while PEFT is more parameter-efficient but may have slightly lower task performance.
Critical Analysis
The paper provides a thorough comparison of retrieval-augmentation and parameter-efficient fine-tuning for personalizing large language models, with a focus on privacy preservation. The authors acknowledge the limitations of their study, such as the use of simulated private data and the need for further evaluation on real-world personalization tasks.
One potential area for further research is the exploration of hybrid approaches that combine the strengths of both retrieval-augmentation and PEFT. Additionally, the paper does not address the long-term implications of these personalization techniques, such as the potential for model drift or the risk of information leakage from the private database.
Overall, the paper offers valuable insights into the trade-offs and considerations involved in developing privacy-preserving personalization methods for large language models. Readers are encouraged to think critically about the nuances and potential concerns raised in the research.
Conclusion
This paper compares two approaches, retrieval-augmentation and parameter-efficient fine-tuning, for personalizing large language models while preserving privacy. The findings demonstrate that both methods can effectively personalize language models, with different trade-offs in terms of performance, efficiency, and privacy preservation.
The research provides important insights for developers and researchers working on personalization of large language models and parameter-efficient fine-tuning techniques. As large language models become more ubiquitous, the need for privacy-preserving personalization will only grow, making this work a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Comparing Retrieval-Augmentation and Parameter-Efficient Fine-Tuning for Privacy-Preserving Personalization of Large Language Models
Alireza Salemi, Hamed Zamani
Privacy-preserving methods for personalizing large language models (LLMs) are relatively under-explored. There are two schools of thought on this topic: (1) generating personalized outputs by personalizing the input prompt through retrieval augmentation from the user's personal information (RAG-based methods), and (2) parameter-efficient fine-tuning of LLMs per user that considers efficiency and space limitations (PEFT-based methods). This paper presents the first systematic comparison between two approaches on a wide range of personalization tasks using seven diverse datasets. Our results indicate that RAG-based and PEFT-based personalization methods on average yield 14.92% and 1.07% improvements over the non-personalized LLM, respectively. We find that combining RAG with PEFT elevates these improvements to 15.98%. Additionally, we identify a positive correlation between the amount of user data and PEFT's effectiveness, indicating that RAG is a better choice for cold-start users (i.e., user's with limited personal data).
Read more9/17/2024
0
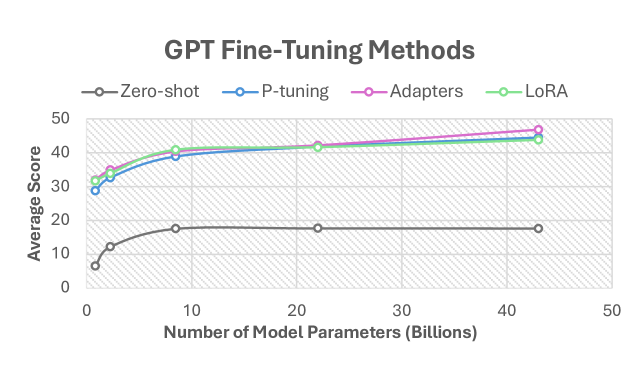
GPT vs RETRO: Exploring the Intersection of Retrieval and Parameter-Efficient Fine-Tuning
Aleksander Ficek, Jiaqi Zeng, Oleksii Kuchaiev
Parameter-Efficient Fine-Tuning (PEFT) and Retrieval-Augmented Generation (RAG) have become popular methods for adapting large language models while minimizing compute requirements. In this paper, we apply PEFT methods (P-tuning, Adapters, and LoRA) to a modified Retrieval-Enhanced Transformer (RETRO) and a baseline GPT model across several sizes, ranging from 823 million to 48 billion parameters. We show that RETRO models outperform GPT models in zero-shot settings due to their unique pre-training process but GPT models have higher performance potential with PEFT. Additionally, our study indicates that 8B parameter models strike an optimal balance between cost and performance and P-tuning lags behind other PEFT techniques. We further provide a comparative analysis of between applying PEFT to an Instruction-tuned RETRO model and base RETRO model. This work presents the first comprehensive comparison of various PEFT methods integrated with RAG, applied to both GPT and RETRO models, highlighting their relative performance.
Read more7/8/2024
📉
0
PEFT-U: Parameter-Efficient Fine-Tuning for User Personalization
Christopher Clarke, Yuzhao Heng, Lingjia Tang, Jason Mars
The recent emergence of Large Language Models (LLMs) has heralded a new era of human-AI interaction. These sophisticated models, exemplified by Chat-GPT and its successors, have exhibited remarkable capabilities in language understanding. However, as these LLMs have undergone exponential growth, a crucial dimension that remains understudied is the personalization of these models. Large foundation models such as GPT-3 etc. focus on creating a universal model that serves a broad range of tasks and users. This approach emphasizes the model's generalization capabilities, treating users as a collective rather than as distinct individuals. While practical for many common applications, this one-size-fits-all approach often fails to address the rich tapestry of human diversity and individual needs. To explore this issue we introduce the PEFT-U Benchmark: a new dataset for building and evaluating NLP models for user personalization. datasetname{} consists of a series of user-centered tasks containing diverse and individualized expressions where the preferences of users can potentially differ for the same input. Using PEFT-U, we explore the challenge of efficiently personalizing LLMs to accommodate user-specific preferences in the context of diverse user-centered tasks.
Read more7/26/2024
0
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Read more4/10/2024