GraCo: Granularity-Controllable Interactive Segmentation

0

Sign in to get full access
Overview
- The paper introduces GraCo, a novel interactive segmentation approach that allows users to control the granularity of the segmentation results.
- GraCo combines object-level and instance-level segmentation to provide a flexible and user-friendly interface for interactive refinement.
- The method leverages attention mechanisms to incorporate user inputs and iteratively update the segmentation, enabling fine-grained control over the output.
Plain English Explanation
The paper presents a new interactive segmentation system called GraCo that lets users decide how detailed or coarse the segmentation should be. Instead of just providing a single, fixed segmentation, GraCo combines two different ways of segmenting the image - one that groups objects together, and one that separates individual instances. This gives users more control and flexibility to refine the segmentation as needed, by allowing them to adjust the level of detail.
The key innovation is the use of attention mechanisms, which help the system incorporate the user's input and iteratively update the segmentation. This means the user can provide feedback, and the segmentation will adapt accordingly, enabling precise control over the final result. The approach aims to make interactive segmentation more accessible and useful for a wide range of applications, such as image editing and 3D modeling.
Technical Explanation
The paper introduces the GraCo (Granularity-Controllable) framework for interactive image segmentation. GraCo combines object-level segmentation and instance-level segmentation to provide users with granularity control over the segmentation results.
The key components of GraCo include:
- Object-level segmentation: GraCo first performs a coarse, object-level segmentation to group related pixels into semantic objects.
- Instance-level segmentation: In parallel, GraCo conducts a fine-grained, instance-level segmentation to separate individual instances within each object.
- Attention-based refinement: GraCo uses attention mechanisms to incorporate user inputs and iteratively refine the segmentation, enabling users to adjust the level of detail.
The attention-based refinement process allows users to provide feedback on the segmentation, such as highlighting errors or areas that need further refinement. The model then updates the segmentation accordingly, seamlessly integrating the user's intent. This approach builds upon prior work on interactive 3D segmentation and attention-guided interactive segmentation.
Critical Analysis
The paper presents a compelling approach to interactive image segmentation that addresses the need for granularity control, which is an important aspect for many real-world applications. The authors demonstrate the effectiveness of the GraCo framework through extensive experiments and comparisons to state-of-the-art methods.
One potential limitation of the approach is the computational complexity introduced by the dual segmentation and attention-based refinement processes. While the paper reports efficient runtime performance, the practical scalability of the method for large-scale or high-resolution images may require further investigation.
Additionally, the paper could have explored the generalization of the GraCo framework to other modalities, such as 3D segmentation, to further demonstrate the versatility and broader applicability of the approach.
Conclusion
The GraCo framework presented in this paper represents a significant advancement in interactive image segmentation by providing users with granularity control. The ability to adjust the level of detail in the segmentation results can greatly enhance the usefulness of interactive segmentation for a wide range of applications, from image editing to 3D modeling. The attention-based refinement process is a promising approach that can potentially be extended to other interactive segmentation tasks, making the research a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GraCo: Granularity-Controllable Interactive Segmentation
Yian Zhao, Kehan Li, Zesen Cheng, Pengchong Qiao, Xiawu Zheng, Rongrong Ji, Chang Liu, Li Yuan, Jie Chen
Interactive Segmentation (IS) segments specific objects or parts in the image according to user input. Current IS pipelines fall into two categories: single-granularity output and multi-granularity output. The latter aims to alleviate the spatial ambiguity present in the former. However, the multi-granularity output pipeline suffers from limited interaction flexibility and produces redundant results. In this work, we introduce Granularity-Controllable Interactive Segmentation (GraCo), a novel approach that allows precise control of prediction granularity by introducing additional parameters to input. This enhances the customization of the interactive system and eliminates redundancy while resolving ambiguity. Nevertheless, the exorbitant cost of annotating multi-granularity masks and the lack of available datasets with granularity annotations make it difficult for models to acquire the necessary guidance to control output granularity. To address this problem, we design an any-granularity mask generator that exploits the semantic property of the pre-trained IS model to automatically generate abundant mask-granularity pairs without requiring additional manual annotation. Based on these pairs, we propose a granularity-controllable learning strategy that efficiently imparts the granularity controllability to the IS model. Extensive experiments on intricate scenarios at object and part levels demonstrate that our GraCo has significant advantages over previous methods. This highlights the potential of GraCo to be a flexible annotation tool, capable of adapting to diverse segmentation scenarios. The project page: https://zhao-yian.github.io/GraCo.
Read more5/17/2024
0
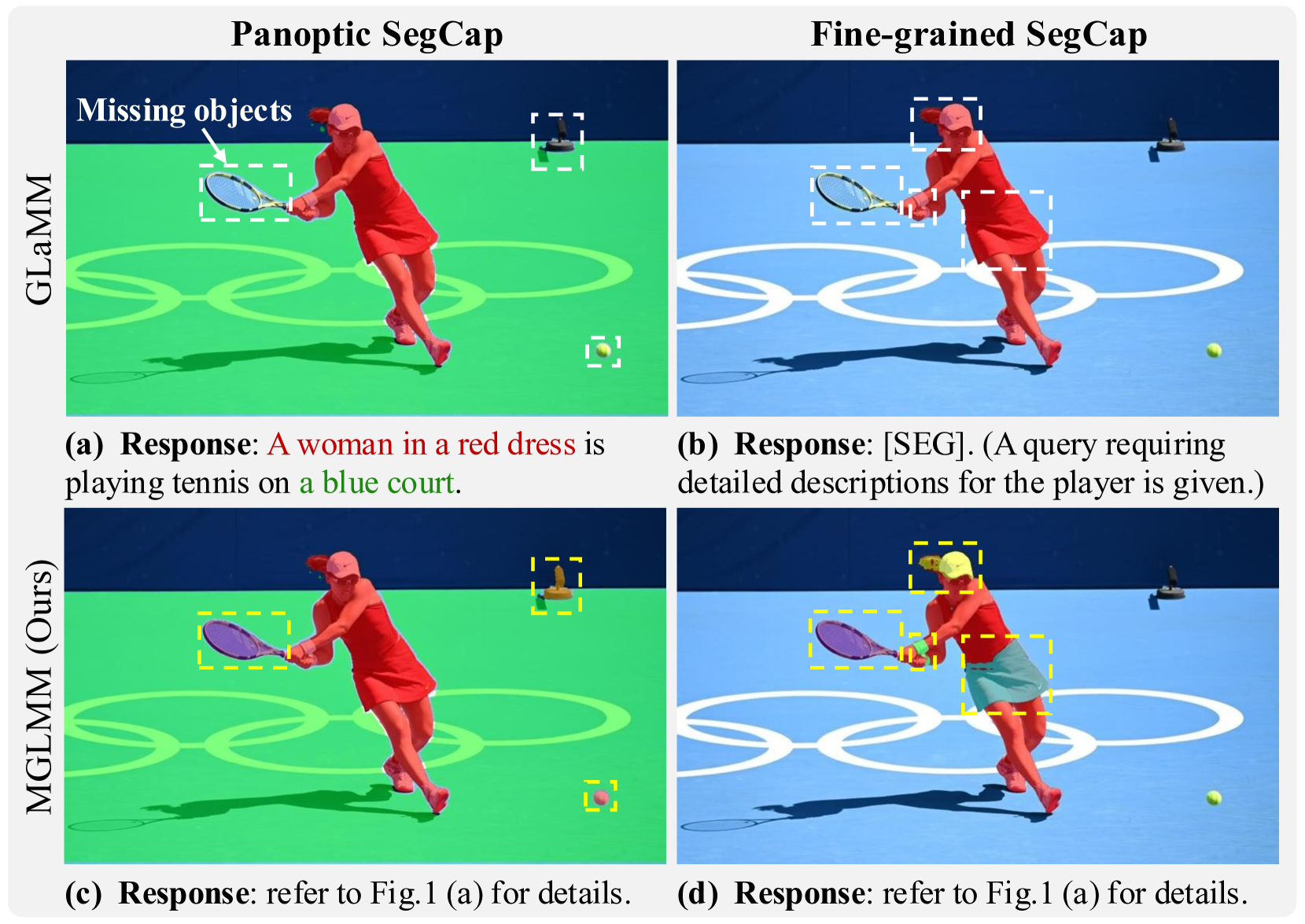
Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model
Li Zhou, Xu Yuan, Zenghui Sun, Zikun Zhou, Jingsong Lan
Large Multimodal Models (LMMs) have achieved significant progress by extending large language models. Building on this progress, the latest developments in LMMs demonstrate the ability to generate dense pixel-wise segmentation through the integration of segmentation models.Despite the innovations, the textual responses and segmentation masks of existing works remain at the instance level, showing limited ability to perform fine-grained understanding and segmentation even provided with detailed textual cues.To overcome this limitation, we introduce a Multi-Granularity Large Multimodal Model (MGLMM), which is capable of seamlessly adjusting the granularity of Segmentation and Captioning (SegCap) following user instructions, from panoptic SegCap to fine-grained SegCap. We name such a new task Multi-Granularity Segmentation and Captioning (MGSC). Observing the lack of a benchmark for model training and evaluation over the MGSC task, we establish a benchmark with aligned masks and captions in multi-granularity using our customized automated annotation pipeline. This benchmark comprises 10K images and more than 30K image-question pairs. We will release our dataset along with the implementation of our automated dataset annotation pipeline for further research.Besides, we propose a novel unified SegCap data format to unify heterogeneous segmentation datasets; it effectively facilitates learning to associate object concepts with visual features during multi-task training. Extensive experiments demonstrate that our MGLMM excels at tackling more than eight downstream tasks and achieves state-of-the-art performance in MGSC, GCG, image captioning, referring segmentation, multiple and empty segmentation, and reasoning segmentation tasks. The great performance and versatility of MGLMM underscore its potential impact on advancing multimodal research.
Read more9/23/2024

0
Interactive3D: Create What You Want by Interactive 3D Generation
Shaocong Dong, Lihe Ding, Zhanpeng Huang, Zibin Wang, Tianfan Xue, Dan Xu
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at url{https://interactive-3d.github.io/}.
Read more4/26/2024

0
Click-Gaussian: Interactive Segmentation to Any 3D Gaussians
Seokhun Choi, Hyeonseop Song, Jaechul Kim, Taehyeong Kim, Hoseok Do
Interactive segmentation of 3D Gaussians opens a great opportunity for real-time manipulation of 3D scenes thanks to the real-time rendering capability of 3D Gaussian Splatting. However, the current methods suffer from time-consuming post-processing to deal with noisy segmentation output. Also, they struggle to provide detailed segmentation, which is important for fine-grained manipulation of 3D scenes. In this study, we propose Click-Gaussian, which learns distinguishable feature fields of two-level granularity, facilitating segmentation without time-consuming post-processing. We delve into challenges stemming from inconsistently learned feature fields resulting from 2D segmentation obtained independently from a 3D scene. 3D segmentation accuracy deteriorates when 2D segmentation results across the views, primary cues for 3D segmentation, are in conflict. To overcome these issues, we propose Global Feature-guided Learning (GFL). GFL constructs the clusters of global feature candidates from noisy 2D segments across the views, which smooths out noises when training the features of 3D Gaussians. Our method runs in 10 ms per click, 15 to 130 times as fast as the previous methods, while also significantly improving segmentation accuracy. Our project page is available at https://seokhunchoi.github.io/Click-Gaussian
Read more7/17/2024