Gradient Boosting Reinforcement Learning

0
Sign in to get full access
Overview
- Gradient Boosting Reinforcement Learning is a novel approach that combines gradient boosting, a powerful machine learning technique, with reinforcement learning, a field focused on training agents to make decisions in dynamic environments.
- The paper explores the potential of this hybrid approach to tackle complex decision-making problems, leveraging the strengths of both gradient boosting and reinforcement learning.
Plain English Explanation
Gradient boosting is a machine learning method that builds a powerful model by combining many simpler models, like decision trees. Reinforcement learning is a way of training AI systems to make good decisions in tricky, ever-changing situations.
The researchers in this paper had the idea to bring these two techniques together. By using gradient boosting to improve a reinforcement learning agent's decision-making abilities, they hope to create AI systems that can tackle complex real-world problems more effectively.
The key innovation is using gradient boosting to gradually refine the reinforcement learning agent's understanding of the environment and the best actions to take. This could lead to more robust, high-performing agents compared to traditional reinforcement learning approaches.
Technical Explanation
The paper presents a novel framework called Gradient Boosting Reinforcement Learning (GBRL) that integrates gradient boosting techniques into the reinforcement learning process.
The core idea is to use gradient boosted trees to approximate the value function and policy in the reinforcement learning setup. This allows the agent to learn a more accurate representation of the environment dynamics and optimal actions, building on the strengths of both gradient boosting and reinforcement learning.
The authors design an algorithm that alternates between updating the gradient boosted trees and performing reinforcement learning updates. This iterative approach aims to refine the agent's decision-making capabilities over time.
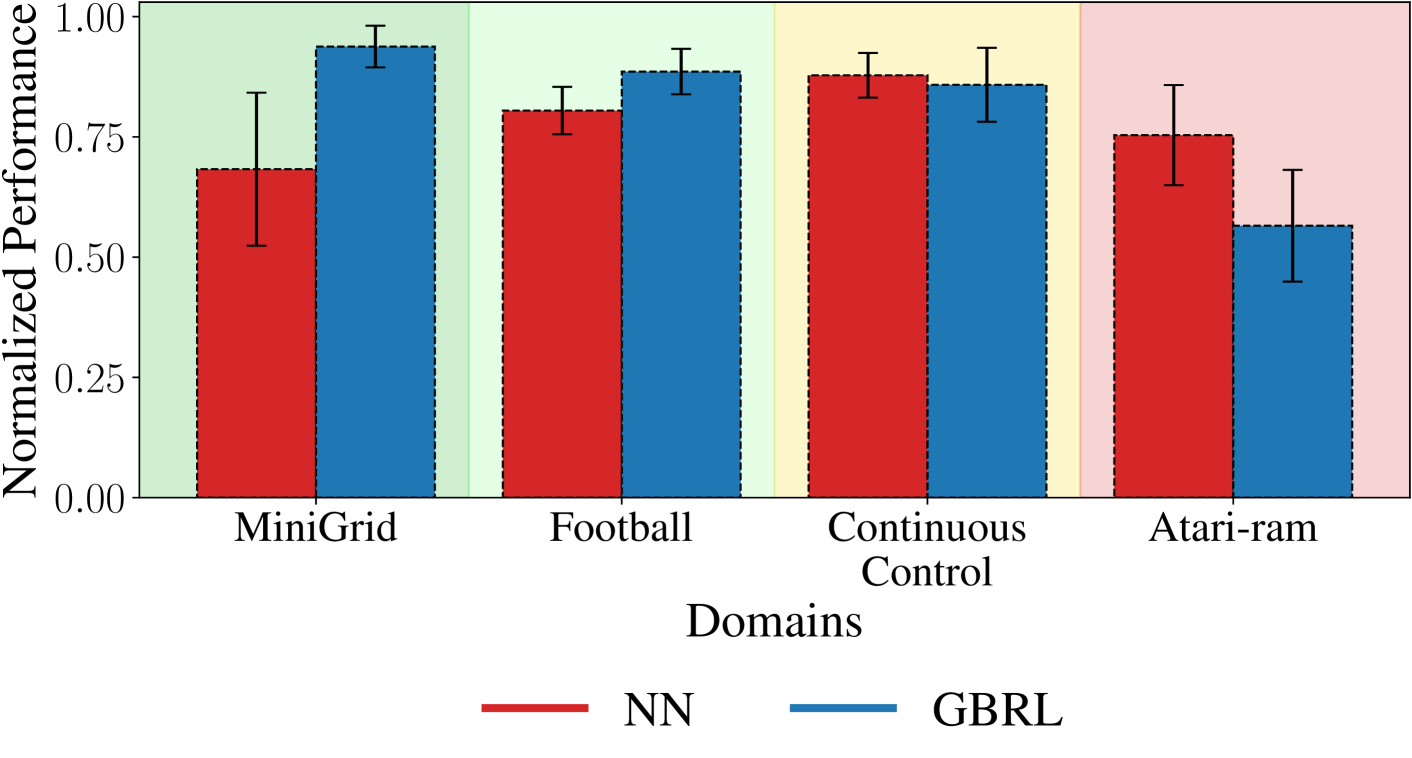
The paper evaluates GBRL on several benchmark reinforcement learning tasks, comparing its performance to standard reinforcement learning methods as well as other hybrid approaches that combine reinforcement learning with supervised learning. The results demonstrate the potential of GBRL to outperform these baselines, particularly in complex environments.
Critical Analysis
The paper provides a compelling conceptual framework for integrating gradient boosting into reinforcement learning. By leveraging the powerful function approximation capabilities of gradient boosted trees, the GBRL approach could lead to more efficient and effective reinforcement learning agents.
However, the paper does not fully explore the limitations and potential drawbacks of this hybrid approach. For example, the computational complexity of training the gradient boosted trees in conjunction with the reinforcement learning updates is not thoroughly analyzed. Scalability to larger, more complex problem domains is also an area that warrants further investigation.
Additionally, the paper's experimental evaluation, while promising, is relatively limited in scope. Exploring GBRL's performance on a wider range of reinforcement learning benchmarks, including more challenging real-world tasks, would help validate the generalizability of the approach.
Future research could also delve into the theoretical underpinnings of GBRL, analyzing the convergence properties and exploring potential connections to other hybrid reinforcement learning methods, such as graph reinforcement learning for power grids or diffusion boosted trees.
Conclusion
The Gradient Boosting Reinforcement Learning (GBRL) framework presented in this paper represents an innovative approach to combining the strengths of gradient boosting and reinforcement learning. By leveraging gradient boosted trees to approximate the value function and policy, the GBRL agent can learn more accurate representations of the environment and optimal actions, potentially leading to improved performance on complex decision-making tasks.
While the initial results are promising, further research is needed to fully understand the limitations and scalability of the GBRL approach. Exploring the theoretical foundations, expanding the experimental evaluation, and investigating connections to other hybrid reinforcement learning methods could help solidify the potential of this novel framework and its applications in real-world domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gradient Boosting Reinforcement Learning
Benjamin Fuhrer, Chen Tessler, Gal Dalal
Neural networks (NN) achieve remarkable results in various tasks, but lack key characteristics: interpretability, support for categorical features, and lightweight implementations suitable for edge devices. While ongoing efforts aim to address these challenges, Gradient Boosting Trees (GBT) inherently meet these requirements. As a result, GBTs have become the go-to method for supervised learning tasks in many real-world applications and competitions. However, their application in online learning scenarios, notably in reinforcement learning (RL), has been limited. In this work, we bridge this gap by introducing Gradient-Boosting RL (GBRL), a framework that extends the advantages of GBT to the RL domain. Using the GBRL framework, we implement various actor-critic algorithms and compare their performance with their NN counterparts. Inspired by shared backbones in NN we introduce a tree-sharing approach for policy and value functions with distinct learning rates, enhancing learning efficiency over millions of interactions. GBRL achieves competitive performance across a diverse array of tasks, excelling in domains with structured or categorical features. Additionally, we present a high-performance, GPU-accelerated implementation that integrates seamlessly with widely-used RL libraries (available at https://github.com/NVlabs/gbrl). GBRL expands the toolkit for RL practitioners, demonstrating the viability and promise of GBT within the RL paradigm, particularly in domains characterized by structured or categorical features.
Read more7/12/2024
🤷
0
Class-Balanced and Reinforced Active Learning on Graphs
Chengcheng Yu, Jiapeng Zhu, Xiang Li
Graph neural networks (GNNs) have demonstrated significant success in various applications, such as node classification, link prediction, and graph classification. Active learning for GNNs aims to query the valuable samples from the unlabeled data for annotation to maximize the GNNs' performance at a lower cost. However, most existing algorithms for reinforced active learning in GNNs may lead to a highly imbalanced class distribution, especially in highly skewed class scenarios. GNNs trained with class-imbalanced labeled data are susceptible to bias toward majority classes, and the lower performance of minority classes may lead to a decline in overall performance. To tackle this issue, we propose a novel class-balanced and reinforced active learning framework for GNNs, namely, GCBR. It learns an optimal policy to acquire class-balanced and informative nodes for annotation, maximizing the performance of GNNs trained with selected labeled nodes. GCBR designs class-balance-aware states, as well as a reward function that achieves trade-off between model performance and class balance. The reinforcement learning algorithm Advantage Actor-Critic (A2C) is employed to learn an optimal policy stably and efficiently. We further upgrade GCBR to GCBR++ by introducing a punishment mechanism to obtain a more class-balanced labeled set. Extensive experiments on multiple datasets demonstrate the effectiveness of the proposed approaches, achieving superior performance over state-of-the-art baselines.
Read more5/8/2024
↗️
0
GNN with Model-based RL for Multi-agent Systems
Hanxiao Chen
Multi-agent systems (MAS) constitute a significant role in exploring machine intelligence and advanced applications. In order to deeply investigate complicated interactions within MAS scenarios, we originally propose GNN for MBRL model, which utilizes a state-spaced Graph Neural Networks with Model-based Reinforcement Learning to address specific MAS missions (e.g., Billiard-Avoidance, Autonomous Driving Cars). In detail, we firstly used GNN model to predict future states and trajectories of multiple agents, then applied the Cross-Entropy Method (CEM) optimized Model Predictive Control to assist the ego-agent planning actions and successfully accomplish certain MAS tasks.
Read more7/15/2024
🚀
0
SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning
Tao Fan, Weijing Chen, Guoqiang Ma, Yan Kang, Lixin Fan, Qiang Yang
Gradient boosting decision tree (GBDT) is an ensemble machine learning algorithm, which is widely used in industry, due to its good performance and easy interpretation. Due to the problem of data isolation and the requirement of privacy, many works try to use vertical federated learning to train machine learning models collaboratively with privacy guarantees between different data owners. SecureBoost is one of the most popular vertical federated learning algorithms for GBDT. However, in order to achieve privacy preservation, SecureBoost involves complex training procedures and time-consuming cryptography operations. This causes SecureBoost to be slow to train and does not scale to large scale data. In this work, we propose SecureBoost+, a large-scale and high-performance vertical federated gradient boosting decision tree framework. SecureBoost+ is secure in the semi-honest model, which is the same as SecureBoost. SecureBoost+ can be scaled up to tens of millions of data samples easily. SecureBoost+ achieves high performance through several novel optimizations for SecureBoost, including ciphertext operation optimization, the introduction of new training mechanisms, and multi-classification training optimization. The experimental results show that SecureBoost+ is 6-35x faster than SecureBoost, but with the same accuracy and can be scaled up to tens of millions of data samples and thousands of feature dimensions.
Read more6/21/2024