SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning

0
🚀
Sign in to get full access
Overview
- Gradient boosting decision tree (GBDT) is a widely used ensemble algorithm in the industry.
- Its vertical federated learning version, SecureBoost, is one of the most popular algorithms used in cross-silo privacy-preserving modeling.
- As the area of privacy computation thrives, demands for large-scale and high-performance federated learning have grown dramatically in real-world applications.
- To fulfill these requirements, the researchers propose SecureBoost+, which integrates several ciphertext calculation optimizations and engineering optimizations.
Plain English Explanation
Gradient boosting decision trees (GBDTs) are a widely used machine learning technique in many industries. They work by combining multiple simple decision trees into a more powerful model.
SecureBoost is a version of GBDT designed for privacy-preserving modeling, where data from multiple organizations is combined without revealing sensitive information. It's one of the most popular algorithms used in this "federated learning" setting.
As the need for privacy-preserving modeling has grown, there's been increasing demand for faster and more scalable federated learning algorithms. To address this, the researchers developed SecureBoost+, which builds on the original SecureBoost algorithm with several optimizations.
These optimizations include improvements to the underlying calculations and engineering enhancements. The goal is to make large-scale, high-performance federated learning more feasible in real-world applications.
Technical Explanation
The key innovations in SecureBoost+ compared to the original SecureBoost are:
-
Ciphertext Calculation Optimizations: The researchers developed more efficient methods for performing the necessary cryptographic operations, which are critical for preserving privacy in the federated learning setting.
-
Engineering Optimizations: They also made engineering improvements to the overall system, such as optimizing data structures and parallelizing certain computations.
The experimental results demonstrate that SecureBoost+ has significant performance improvements on large and high-dimensional datasets compared to SecureBoost. This makes effective and efficient large-scale vertical federated learning more practical.
Critical Analysis
The paper does not provide a detailed discussion of the limitations or potential issues with SecureBoost+. While the performance improvements are impressive, it's important to consider factors such as:
- The specific privacy guarantees provided by the optimized cryptographic operations, and whether they meet the needs of real-world applications.
- The scalability of the system as the number of participating organizations or the size of the datasets increases further.
- Potential challenges in bridging data barriers among participants and ensuring privacy during confidential forecasting.
Additionally, it would be interesting to see how SecureBoost+ compares to other federated learning algorithms, both in terms of performance and privacy guarantees.
Conclusion
The proposed SecureBoost+ algorithm represents an important advancement in the field of large-scale, high-performance federated learning. By incorporating various optimizations, the researchers have made significant strides in addressing the growing demand for privacy-preserving modeling in real-world applications.
While the paper demonstrates the improved efficiency of SecureBoost+, further research is needed to fully understand its limitations and potential challenges. Nonetheless, this work contributes to the ongoing efforts to [develop robust and scalable gradient boosted filters for privacy-preserving data analysis and modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning
Tao Fan, Weijing Chen, Guoqiang Ma, Yan Kang, Lixin Fan, Qiang Yang
Gradient boosting decision tree (GBDT) is an ensemble machine learning algorithm, which is widely used in industry, due to its good performance and easy interpretation. Due to the problem of data isolation and the requirement of privacy, many works try to use vertical federated learning to train machine learning models collaboratively with privacy guarantees between different data owners. SecureBoost is one of the most popular vertical federated learning algorithms for GBDT. However, in order to achieve privacy preservation, SecureBoost involves complex training procedures and time-consuming cryptography operations. This causes SecureBoost to be slow to train and does not scale to large scale data. In this work, we propose SecureBoost+, a large-scale and high-performance vertical federated gradient boosting decision tree framework. SecureBoost+ is secure in the semi-honest model, which is the same as SecureBoost. SecureBoost+ can be scaled up to tens of millions of data samples easily. SecureBoost+ achieves high performance through several novel optimizations for SecureBoost, including ciphertext operation optimization, the introduction of new training mechanisms, and multi-classification training optimization. The experimental results show that SecureBoost+ is 6-35x faster than SecureBoost, but with the same accuracy and can be scaled up to tens of millions of data samples and thousands of feature dimensions.
Read more6/21/2024
0
Hyperparameter Optimization for SecureBoost via Constrained Multi-Objective Federated Learning
Yan Kang, Ziyao Ren, Lixin Fan, Linghua Yang, Yongxin Tong, Qiang Yang
SecureBoost is a tree-boosting algorithm that leverages homomorphic encryption (HE) to protect data privacy in vertical federated learning. SecureBoost and its variants have been widely adopted in fields such as finance and healthcare. However, the hyperparameters of SecureBoost are typically configured heuristically for optimizing model performance (i.e., utility) solely, assuming that privacy is secured. Our study found that SecureBoost and some of its variants are still vulnerable to label leakage. This vulnerability may lead the current heuristic hyperparameter configuration of SecureBoost to a suboptimal trade-off between utility, privacy, and efficiency, which are pivotal elements toward a trustworthy federated learning system. To address this issue, we propose the Constrained Multi-Objective SecureBoost (CMOSB) algorithm, which aims to approximate Pareto optimal solutions that each solution is a set of hyperparameters achieving an optimal trade-off between utility loss, training cost, and privacy leakage. We design measurements of the three objectives, including a novel label inference attack named instance clustering attack (ICA) to measure the privacy leakage of SecureBoost. Additionally, we provide two countermeasures against ICA. The experimental results demonstrate that the CMOSB yields superior hyperparameters over those optimized by grid search and Bayesian optimization regarding the trade-off between utility loss, training cost, and privacy leakage.
Read more4/9/2024
🎯
0
S-BDT: Distributed Differentially Private Boosted Decision Trees
Thorsten Peinemann, Moritz Kirschte, Joshua Stock, Carlos Cotrini, Esfandiar Mohammadi
We introduce S-BDT: a novel $(varepsilon,delta)$-differentially private distributed gradient boosted decision tree (GBDT) learner that improves the protection of single training data points (privacy) while achieving meaningful learning goals, such as accuracy or regression error (utility). S-BDT uses less noise by relying on non-spherical multivariate Gaussian noise, for which we show tight subsampling bounds for privacy amplification and incorporate that into a R'enyi filter for individual privacy accounting. We experimentally reach the same utility while saving $50%$ in terms of epsilon for $varepsilon le 0.5$ on the Abalone regression dataset (dataset size $approx 4K$), saving $30%$ in terms of epsilon for $varepsilon le 0.08$ for the Adult classification dataset (dataset size $approx 50K$), and saving $30%$ in terms of epsilon for $varepsilonleq0.03$ for the Spambase classification dataset (dataset size $approx 5K$). Moreover, we show that for situations where a GBDT is learning a stream of data that originates from different subpopulations (non-IID), S-BDT improves the saving of epsilon even further.
Read more8/19/2024
0
Gradient Boosting Reinforcement Learning
Benjamin Fuhrer, Chen Tessler, Gal Dalal
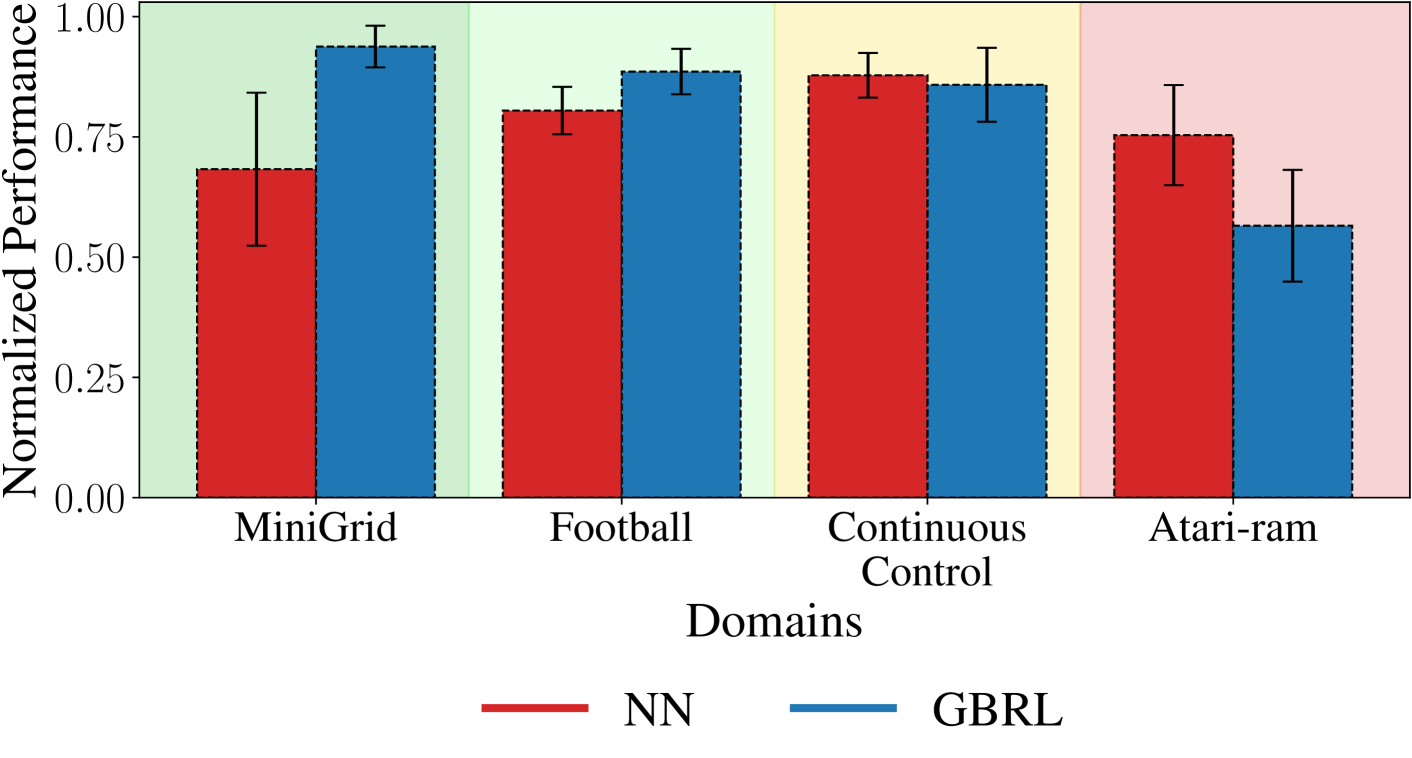
Neural networks (NN) achieve remarkable results in various tasks, but lack key characteristics: interpretability, support for categorical features, and lightweight implementations suitable for edge devices. While ongoing efforts aim to address these challenges, Gradient Boosting Trees (GBT) inherently meet these requirements. As a result, GBTs have become the go-to method for supervised learning tasks in many real-world applications and competitions. However, their application in online learning scenarios, notably in reinforcement learning (RL), has been limited. In this work, we bridge this gap by introducing Gradient-Boosting RL (GBRL), a framework that extends the advantages of GBT to the RL domain. Using the GBRL framework, we implement various actor-critic algorithms and compare their performance with their NN counterparts. Inspired by shared backbones in NN we introduce a tree-sharing approach for policy and value functions with distinct learning rates, enhancing learning efficiency over millions of interactions. GBRL achieves competitive performance across a diverse array of tasks, excelling in domains with structured or categorical features. Additionally, we present a high-performance, GPU-accelerated implementation that integrates seamlessly with widely-used RL libraries (available at https://github.com/NVlabs/gbrl). GBRL expands the toolkit for RL practitioners, demonstrating the viability and promise of GBT within the RL paradigm, particularly in domains characterized by structured or categorical features.
Read more7/12/2024