Gradient Coding with Iterative Block Leverage Score Sampling

0
🔮
Sign in to get full access
Overview
- This paper proposes a new approach to enhance distributed machine learning systems by combining randomized numerical linear algebra with approximate coded computing techniques.
- The key idea is to use leverage score sampling to create an $\ell_2$-subspace embedding, which is then used to derive an approximate gradient coding scheme.
- The approach aims to accelerate linear regression in the presence of "stragglers" (slow or failed nodes) in distributed computational networks, such as in federated learning scenarios.
Plain English Explanation
The paper presents a new technique to improve the performance of distributed machine learning systems, particularly when dealing with slow or failing nodes in the network. The key idea is to combine two powerful concepts:
-
Leverage score sampling: This is a way of selecting a representative subset of data points that captures the important information in the full dataset. It's like choosing a few key examples that summarize the overall characteristics of the data.
-
Gradient coding: This is a method for encoding the computation of gradients (a crucial step in many machine learning algorithms) in a way that makes the overall computation more robust to failures or delays in the network. It's like having a backup plan for when some of the computational nodes don't perform as expected.
By combining these two ideas, the authors create a system that can efficiently solve linear regression problems in a distributed setting, even when some of the computational nodes are slow or fail. This is particularly useful for applications like federated learning, where data is spread across many devices and the network may be unreliable.
The authors show that their approach can provide strong theoretical guarantees on the quality of the approximate solution, while also being computationally efficient. This unification of randomized numerical linear algebra and approximate coded computing is a significant contribution to the field.
Technical Explanation
The paper begins by generalizing the leverage score sampling sketch for $\ell_2$-subspace embeddings, which allows the authors to sample subsets of the transformed data. This makes the sketching approach more suitable for distributed settings, where the data may be spread across multiple nodes.
The authors then use this $\ell_2$-subspace embedding technique to derive an approximate gradient coding approach for first-order optimization methods, such as linear regression. Gradient coding is a technique that can help accelerate these methods in the presence of "stragglers" (slow or failed nodes) in a distributed computational network.
To achieve the desired approximation guarantees, the authors replicate the data across the distributed network. This induces a specific sampling distribution that allows the approach to work effectively.
The paper also explores the use of weighting when sketching takes place through sampling with replacement, which can provide further compression of the data.
Notably, the authors are able to transition to uniform sampling without applying a random projection, as is the case in the subsampled randomized Hadamard transform. This simplifies the overall approach and makes it more practical to implement.
Critical Analysis
The paper presents a compelling and well-designed approach to addressing the challenge of stragglers in distributed machine learning systems. The authors have successfully combined two powerful techniques, leverage score sampling and gradient coding, to create a robust and efficient solution.
One potential limitation of the approach is that it relies on replicating the data across the distributed network. This may not be feasible or desirable in all scenarios, particularly when the dataset is large or when privacy concerns are a factor. The authors acknowledge this and suggest further research into sparse sketching techniques as a potential solution.
Additionally, the theoretical analysis in the paper is quite technical and may be difficult for a general audience to fully appreciate. While the authors provide clear intuitions and explanations, some readers may struggle to grasp the nuances of the mathematical proofs and guarantees.
Overall, this work represents a significant contribution to the field of distributed machine learning, and the authors have done an excellent job of presenting their ideas in a clear and well-structured manner.
Conclusion
This paper proposes a novel approach that combines randomized numerical linear algebra and approximate coded computing techniques to enhance the performance of distributed machine learning systems, particularly in the presence of stragglers. By using leverage score sampling to create an $\ell_2$-subspace embedding and then deriving an approximate gradient coding scheme, the authors have developed a robust and efficient solution for accelerating linear regression in challenging distributed environments, such as those found in federated learning scenarios.
The unification of these two powerful concepts is a significant contribution to the field, and the authors have demonstrated the effectiveness of their approach through both theoretical analysis and empirical evaluation. While the paper presents some limitations, such as the need for data replication, the overall impact of this work has the potential to advance the state of the art in distributed machine learning and help researchers and practitioners build more reliable and efficient systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Gradient Coding with Iterative Block Leverage Score Sampling
Neophytos Charalambides, Mert Pilanci, Alfred Hero
We generalize the leverage score sampling sketch for $ell_2$-subspace embeddings, to accommodate sampling subsets of the transformed data, so that the sketching approach is appropriate for distributed settings. This is then used to derive an approximate coded computing approach for first-order methods; known as gradient coding, to accelerate linear regression in the presence of failures in distributed computational networks, textit{i.e.} stragglers. We replicate the data across the distributed network, to attain the approximation guarantees through the induced sampling distribution. The significance and main contribution of this work, is that it unifies randomized numerical linear algebra with approximate coded computing, while attaining an induced $ell_2$-subspace embedding through uniform sampling. The transition to uniform sampling is done without applying a random projection, as in the case of the subsampled randomized Hadamard transform. Furthermore, by incorporating this technique to coded computing, our scheme is an iterative sketching approach to approximately solving linear regression. We also propose weighting when sketching takes place through sampling with replacement, for further compression.
Read more6/27/2024

0
Improved Active Learning via Dependent Leverage Score Sampling
Atsushi Shimizu, Xiaoou Cheng, Christopher Musco, Jonathan Weare
We show how to obtain improved active learning methods in the agnostic (adversarial noise) setting by combining marginal leverage score sampling with non-independent sampling strategies that promote spatial coverage. In particular, we propose an easily implemented method based on the emph{pivotal sampling algorithm}, which we test on problems motivated by learning-based methods for parametric PDEs and uncertainty quantification. In comparison to independent sampling, our method reduces the number of samples needed to reach a given target accuracy by up to $50%$. We support our findings with two theoretical results. First, we show that any non-independent leverage score sampling method that obeys a weak emph{one-sided $ell_{infty}$ independence condition} (which includes pivotal sampling) can actively learn $d$ dimensional linear functions with $O(dlog d)$ samples, matching independent sampling. This result extends recent work on matrix Chernoff bounds under $ell_{infty}$ independence, and may be of interest for analyzing other sampling strategies beyond pivotal sampling. Second, we show that, for the important case of polynomial regression, our pivotal method obtains an improved bound on $O(d)$ samples.
Read more5/7/2024

0
Approximate Gradient Coding for Privacy-Flexible Federated Learning with Non-IID Data
Okko Makkonen, Sampo Niemela, Camilla Hollanti, Serge Kas Hanna
This work focuses on the challenges of non-IID data and stragglers/dropouts in federated learning. We introduce and explore a privacy-flexible paradigm that models parts of the clients' local data as non-private, offering a more versatile and business-oriented perspective on privacy. Within this framework, we propose a data-driven strategy for mitigating the effects of label heterogeneity and client straggling on federated learning. Our solution combines both offline data sharing and approximate gradient coding techniques. Through numerical simulations using the MNIST dataset, we demonstrate that our approach enables achieving a deliberate trade-off between privacy and utility, leading to improved model convergence and accuracy while using an adaptable portion of non-private data.
Read more4/5/2024
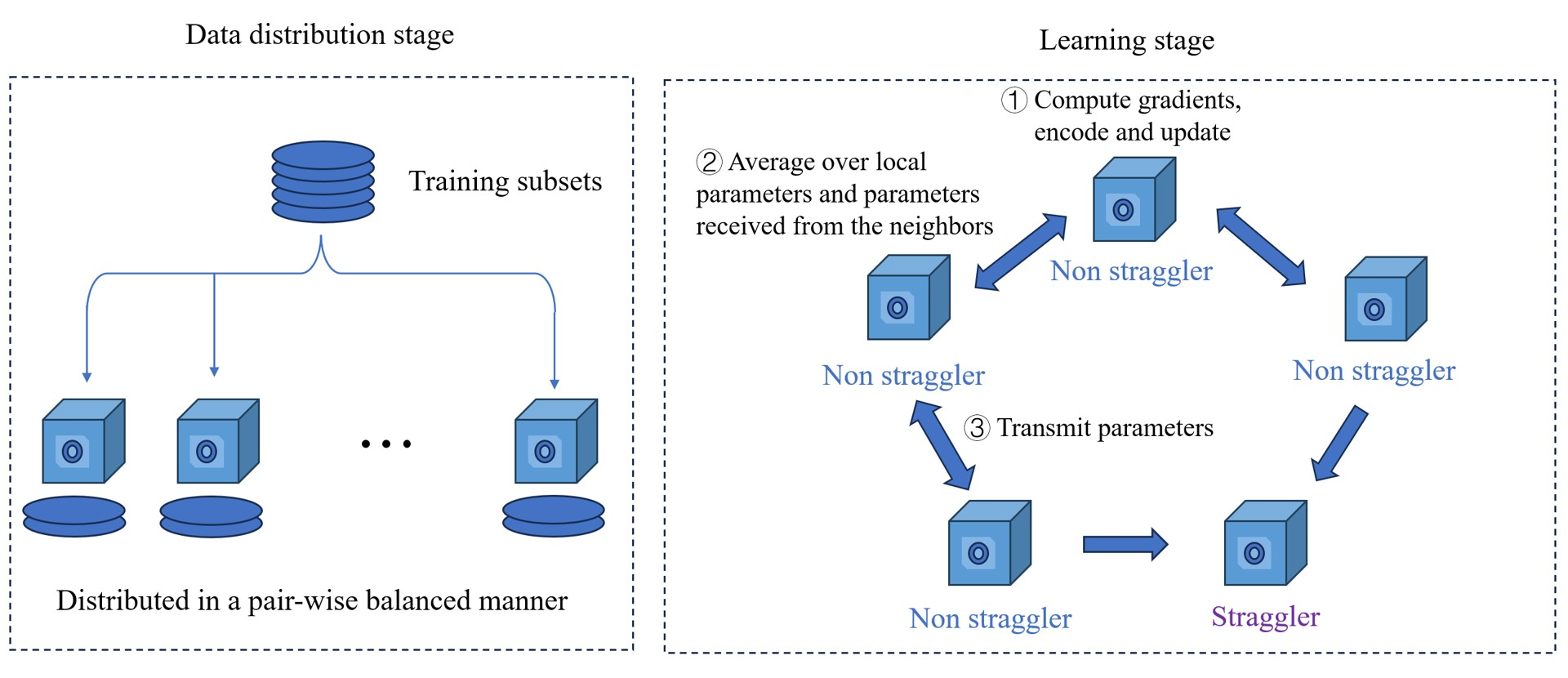
0
Gradient Coding in Decentralized Learning for Evading Stragglers
Chengxi Li, Mikael Skoglund
In this paper, we consider a decentralized learning problem in the presence of stragglers. Although gradient coding techniques have been developed for distributed learning to evade stragglers, where the devices send encoded gradients with redundant training data, it is difficult to apply those techniques directly to decentralized learning scenarios. To deal with this problem, we propose a new gossip-based decentralized learning method with gradient coding (GOCO). In the proposed method, to avoid the negative impact of stragglers, the parameter vectors are updated locally using encoded gradients based on the framework of stochastic gradient coding and then averaged in a gossip-based manner. We analyze the convergence performance of GOCO for strongly convex loss functions. And we also provide simulation results to demonstrate the superiority of the proposed method in terms of learning performance compared with the baseline methods.
Read more6/17/2024