Gradient Harmonization in Unsupervised Domain Adaptation

0

Sign in to get full access
Overview
- Unsupervised Domain Adaptation (UDA) is a machine learning technique that aims to transfer knowledge from a labeled source domain to an unlabeled target domain.
- The paper proposes a novel method called Gradient Harmonization (GH) to address the problem of UDA.
- GH aims to align the gradients of the source and target domains during training, which can lead to improved transfer learning performance.
Plain English Explanation
Imagine you have a machine learning model that's been trained on a certain type of data, like images of dogs. This model works great on that type of data, but what if you want to use it on a different type of data, like images of cats? This is where Unsupervised Domain Adaptation (UDA) comes in.
UDA is a technique that allows you to take a model trained on one type of data (the source domain) and adapt it to work well on a different type of data (the target domain), without having to label the target data. This is useful when you don't have a lot of labeled data for the new domain.
The key idea behind the Gradient Harmonization (GH) method proposed in this paper is to align the gradients of the source and target domains during the training process. Gradients are the mathematical signals that tell the model how to update its internal parameters to improve its performance.
By aligning the gradients of the source and target domains, the model can learn features that are useful for both domains, leading to better transfer learning performance. This can be thought of as a way to "harmonize" the way the model learns from the two different types of data.
Technical Explanation
The paper presents a novel method called Gradient Harmonization (GH) for Unsupervised Domain Adaptation (UDA). The key idea behind GH is to align the gradients of the source and target domains during the training process.
Traditionally, UDA methods try to learn a feature representation that is domain-invariant, meaning the features learned from the source domain can also be applied to the target domain. However, this can be challenging, as the feature distributions between the two domains may differ significantly.
GH aims to address this challenge by directly aligning the gradients of the source and target domains. The authors propose a gradient harmonization loss function that encourages the gradients of the source and target samples to be similar during training. This helps the model learn features that are useful for both domains, leading to improved transfer learning performance.
The authors evaluate GH on several standard UDA benchmarks, including image classification and semantic segmentation tasks. The results show that GH outperforms state-of-the-art UDA methods, demonstrating the effectiveness of their approach.
Critical Analysis
The Gradient Harmonization method proposed in this paper is a novel and promising approach to Unsupervised Domain Adaptation. By directly aligning the gradients of the source and target domains, the model can learn features that are useful for both domains, leading to improved transfer learning performance.
However, the paper does not explore the limitations or potential drawbacks of the GH method. For example, it's unclear how GH would perform on more complex or diverse target domains, where the distribution shift from the source domain may be more significant. Additionally, the paper does not discuss the computational overhead or training time required for the GH method compared to other UDA approaches.
Further research could explore the robustness of GH to different types of domain shifts, as well as its performance on larger-scale or more challenging datasets. Comparing GH to other gradient-based UDA methods could also provide additional insights into the strengths and weaknesses of this approach.
Conclusion
The Gradient Harmonization (GH) method proposed in this paper is a innovative solution to the problem of Unsupervised Domain Adaptation. By aligning the gradients of the source and target domains during training, GH can help the model learn features that are useful for both domains, leading to improved transfer learning performance.
The results on standard UDA benchmarks are promising, and the GH method has the potential to be a valuable tool in the field of transfer learning. However, further research is needed to explore the limitations and broader applicability of this approach.
Overall, this paper presents an interesting and impactful contribution to the field of Unsupervised Domain Adaptation, with the GH method offering a unique and effective solution to a challenging problem in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gradient Harmonization in Unsupervised Domain Adaptation
Fuxiang Huang, Suqi Song, Lei Zhang
Unsupervised domain adaptation (UDA) intends to transfer knowledge from a labeled source domain to an unlabeled target domain. Many current methods focus on learning feature representations that are both discriminative for classification and invariant across domains by simultaneously optimizing domain alignment and classification tasks. However, these methods often overlook a crucial challenge: the inherent conflict between these two tasks during gradient-based optimization. In this paper, we delve into this issue and introduce two effective solutions known as Gradient Harmonization, including GH and GH++, to mitigate the conflict between domain alignment and classification tasks. GH operates by altering the gradient angle between different tasks from an obtuse angle to an acute angle, thus resolving the conflict and trade-offing the two tasks in a coordinated manner. Yet, this would cause both tasks to deviate from their original optimization directions. We thus further propose an improved version, GH++, which adjusts the gradient angle between tasks from an obtuse angle to a vertical angle. This not only eliminates the conflict but also minimizes deviation from the original gradient directions. Finally, for optimization convenience and efficiency, we evolve the gradient harmonization strategies into a dynamically weighted loss function using an integral operator on the harmonized gradient. Notably, GH/GH++ are orthogonal to UDA and can be seamlessly integrated into most existing UDA models. Theoretical insights and experimental analyses demonstrate that the proposed approaches not only enhance popular UDA baselines but also improve recent state-of-the-art models.
Read more8/2/2024

0
Enhancing Domain Adaptation through Prompt Gradient Alignment
Hoang Phan, Lam Tran, Quyen Tran, Trung Le
Prior Unsupervised Domain Adaptation (UDA) methods often aim to train a domain-invariant feature extractor, which may hinder the model from learning sufficiently discriminative features. To tackle this, a line of works based on prompt learning leverages the power of large-scale pre-trained vision-language models to learn both domain-invariant and specific features through a set of domain-agnostic and domain-specific learnable prompts. Those studies typically enforce invariant constraints on representation, output, or prompt space to learn such prompts. Differently, we cast UDA as a multiple-objective optimization problem in which each objective is represented by a domain loss. Under this new framework, we propose aligning per-objective gradients to foster consensus between them. Additionally, to prevent potential overfitting when fine-tuning this deep learning architecture, we penalize the norm of these gradients. To achieve these goals, we devise a practical gradient update procedure that can work under both single-source and multi-source UDA. Empirically, our method consistently surpasses other prompt-based baselines by a large margin on different UDA benchmarks
Read more6/14/2024
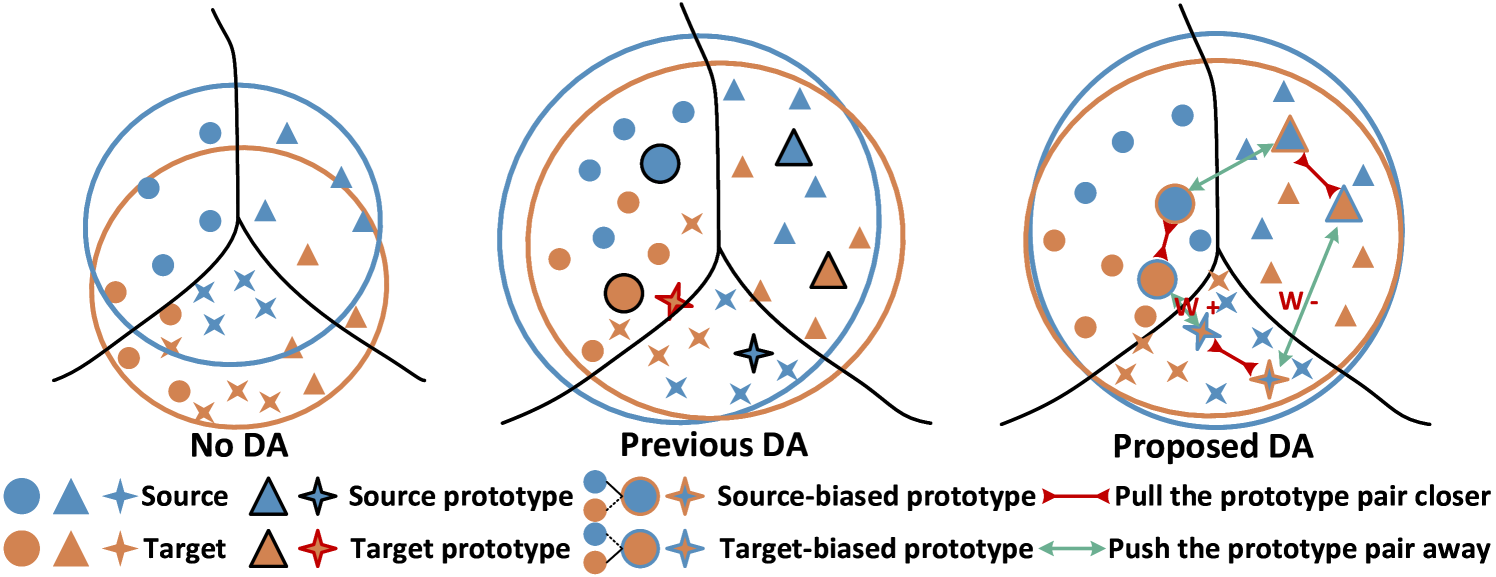
0
Gradually Vanishing Gap in Prototypical Network for Unsupervised Domain Adaptation
Shanshan Wang, Hao Zhou, Xun Yang, Zhenwei He, Mengzhu Wang, Xingyi Zhang, Meng Wang
Unsupervised domain adaptation (UDA) is a critical problem for transfer learning, which aims to transfer the semantic information from labeled source domain to unlabeled target domain. Recent advancements in UDA models have demonstrated significant generalization capabilities on the target domain. However, the generalization boundary of UDA models remains unclear. When the domain discrepancy is too large, the model can not preserve the distribution structure, leading to distribution collapse during the alignment. To address this challenge, we propose an efficient UDA framework named Gradually Vanishing Gap in Prototypical Network (GVG-PN), which achieves transfer learning from both global and local perspectives. From the global alignment standpoint, our model generates a domain-biased intermediate domain that helps preserve the distribution structures. By entangling cross-domain features, our model progressively reduces the risk of distribution collapse. However, only relying on global alignment is insufficient to preserve the distribution structure. To further enhance the inner relationships of features, we introduce the local perspective. We utilize the graph convolutional network (GCN) as an intuitive method to explore the internal relationships between features, ensuring the preservation of manifold structures and generating domain-biased prototypes. Additionally, we consider the discriminability of the inner relationships between features. We propose a pro-contrastive loss to enhance the discriminability at the prototype level by separating hard negative pairs. By incorporating both GCN and the pro-contrastive loss, our model fully explores fine-grained semantic relationships. Experiments on several UDA benchmarks validated that the proposed GVG-PN can clearly outperform the SOTA models.
Read more5/29/2024

0
Revisiting, Benchmarking and Understanding Unsupervised Graph Domain Adaptation
Meihan Liu, Zhen Zhang, Jiachen Tang, Jiajun Bu, Bingsheng He, Sheng Zhou
Unsupervised Graph Domain Adaptation (UGDA) involves the transfer of knowledge from a label-rich source graph to an unlabeled target graph under domain discrepancies. Despite the proliferation of methods designed for this emerging task, the lack of standard experimental settings and fair performance comparisons makes it challenging to understand which and when models perform well across different scenarios. To fill this gap, we present the first comprehensive benchmark for unsupervised graph domain adaptation named GDABench, which encompasses 16 algorithms across 5 datasets with 74 adaptation tasks. Through extensive experiments, we observe that the performance of current UGDA models varies significantly across different datasets and adaptation scenarios. Specifically, we recognize that when the source and target graphs face significant distribution shifts, it is imperative to formulate strategies to effectively address and mitigate graph structural shifts. We also find that with appropriate neighbourhood aggregation mechanisms, simple GNN variants can even surpass state-of-the-art UGDA baselines. To facilitate reproducibility, we have developed an easy-to-use library PyGDA for training and evaluating existing UGDA methods, providing a standardized platform in this community. Our source codes and datasets can be found at: https://github.com/pygda-team/pygda.
Read more7/17/2024