Gradually Vanishing Gap in Prototypical Network for Unsupervised Domain Adaptation

0
Sign in to get full access
Overview
- This paper proposes a new method for unsupervised domain adaptation using prototypical networks.
- The key idea is to gradually reduce the gap between source and target domain prototypes during training, leading to better generalization to the target domain.
- The method uses a pro-contrastive learning objective to encourage the model to learn domain-invariant representations.
Plain English Explanation
In machine learning, there are often situations where a model is trained on data from one domain (e.g., images of dogs) but needs to be applied to a different domain (e.g., images of cats). This is called the problem of unsupervised domain adaptation.
The authors of this paper introduce a new approach to address this challenge. Their key insight is that rather than trying to completely eliminate the differences between the source and target domains, it's better to gradually reduce the gap between them during the training process. This allows the model to learn representations that are more generalizable across domains.
The method they propose is based on prototypical networks, which are a type of neural network that learns to represent each class of data as a "prototype" or average example. The authors introduce a new training objective, called "pro-contrastive learning," which encourages the model to learn prototypes that are both discriminative within each domain and similar across domains.
By gradually reducing the gap between the source and target domain prototypes, the model is able to learn features that are useful for both domains, leading to better performance on the target domain without requiring any labeled data from that domain. This is a powerful approach that could have many applications in areas like computer vision and natural language processing.
Technical Explanation
The key technical contributions of this paper are:
-
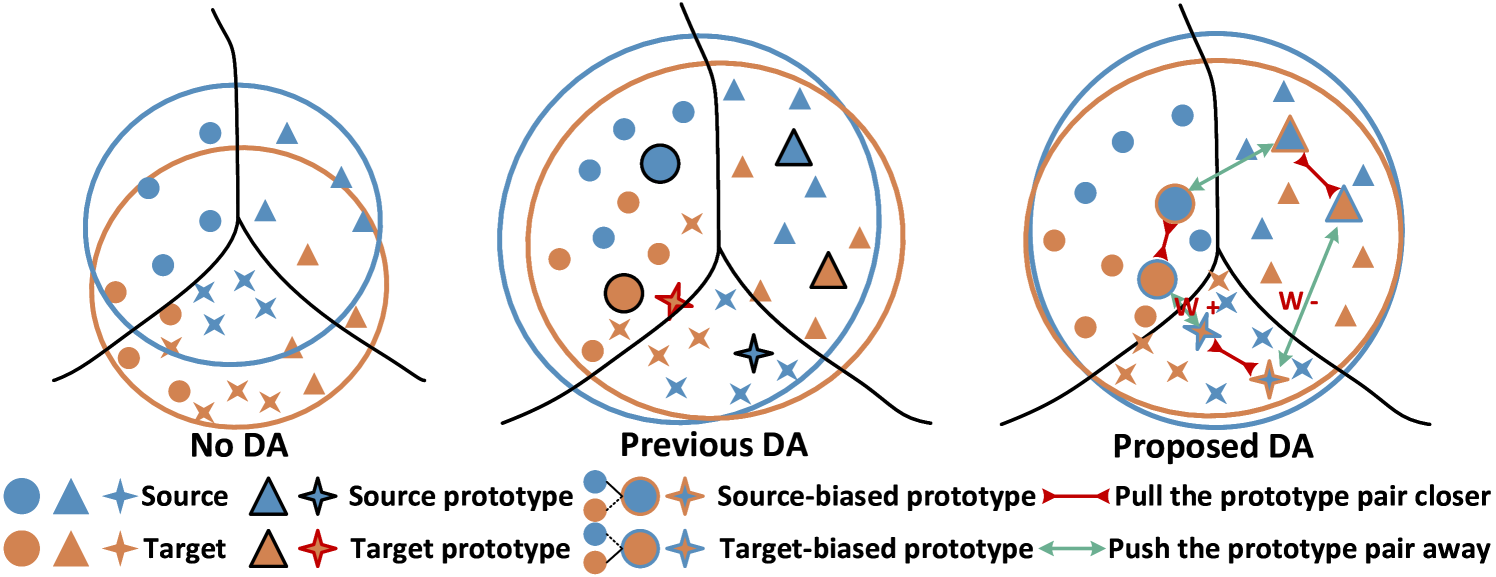
Gradually Vanishing Gap: The authors propose a new training approach where the gap between the source and target domain prototypes is gradually reduced over the course of training. This is in contrast to previous methods that try to completely eliminate the domain gap.
-
Pro-Contrastive Learning: The authors introduce a new training objective called "pro-contrastive learning" that encourages the model to learn prototypes that are both discriminative within each domain and similar across domains. This helps the model learn domain-invariant representations.
-
Theoretical Analysis: The authors provide a theoretical analysis of their method, showing that the gradually vanishing gap leads to better generalization bounds for the target domain.
Experimentally, the authors evaluate their method on several standard unsupervised domain adaptation benchmarks, including image classification and object detection tasks. The results show that their approach outperforms previous state-of-the-art methods by a significant margin.
Critical Analysis
One potential limitation of this work is that it relies on the assumption that there is a meaningful set of shared features between the source and target domains. In cases where the domains are very different, this assumption may not hold, and the gradually vanishing gap approach may not be as effective.
Additionally, the authors' theoretical analysis assumes certain simplifying assumptions about the data distributions, which may not always hold in practice. It would be valuable to see further empirical evaluation of the method's robustness to violations of these assumptions.
That said, the core idea of gradually adapting the model to the target domain, rather than trying to eliminate the domain gap entirely, is a compelling one. This could inspire further research into more flexible and adaptive approaches to domain adaptation, which could have broader impacts on a range of real-world applications.
Conclusion
This paper presents a novel approach to unsupervised domain adaptation using prototypical networks. By gradually reducing the gap between source and target domain prototypes during training, the model is able to learn more generalizable representations that perform well on the target domain without any labeled data.
The authors' pro-contrastive learning objective and theoretical analysis provide a strong foundation for this work, and the empirical results demonstrate the method's effectiveness on standard benchmarks. While there are some potential limitations, the core ideas behind this research could lead to valuable advancements in the field of domain adaptation, with applications in areas like computer vision and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gradually Vanishing Gap in Prototypical Network for Unsupervised Domain Adaptation
Shanshan Wang, Hao Zhou, Xun Yang, Zhenwei He, Mengzhu Wang, Xingyi Zhang, Meng Wang
Unsupervised domain adaptation (UDA) is a critical problem for transfer learning, which aims to transfer the semantic information from labeled source domain to unlabeled target domain. Recent advancements in UDA models have demonstrated significant generalization capabilities on the target domain. However, the generalization boundary of UDA models remains unclear. When the domain discrepancy is too large, the model can not preserve the distribution structure, leading to distribution collapse during the alignment. To address this challenge, we propose an efficient UDA framework named Gradually Vanishing Gap in Prototypical Network (GVG-PN), which achieves transfer learning from both global and local perspectives. From the global alignment standpoint, our model generates a domain-biased intermediate domain that helps preserve the distribution structures. By entangling cross-domain features, our model progressively reduces the risk of distribution collapse. However, only relying on global alignment is insufficient to preserve the distribution structure. To further enhance the inner relationships of features, we introduce the local perspective. We utilize the graph convolutional network (GCN) as an intuitive method to explore the internal relationships between features, ensuring the preservation of manifold structures and generating domain-biased prototypes. Additionally, we consider the discriminability of the inner relationships between features. We propose a pro-contrastive loss to enhance the discriminability at the prototype level by separating hard negative pairs. By incorporating both GCN and the pro-contrastive loss, our model fully explores fine-grained semantic relationships. Experiments on several UDA benchmarks validated that the proposed GVG-PN can clearly outperform the SOTA models.
Read more5/29/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024

0
Revisiting, Benchmarking and Understanding Unsupervised Graph Domain Adaptation
Meihan Liu, Zhen Zhang, Jiachen Tang, Jiajun Bu, Bingsheng He, Sheng Zhou
Unsupervised Graph Domain Adaptation (UGDA) involves the transfer of knowledge from a label-rich source graph to an unlabeled target graph under domain discrepancies. Despite the proliferation of methods designed for this emerging task, the lack of standard experimental settings and fair performance comparisons makes it challenging to understand which and when models perform well across different scenarios. To fill this gap, we present the first comprehensive benchmark for unsupervised graph domain adaptation named GDABench, which encompasses 16 algorithms across 5 datasets with 74 adaptation tasks. Through extensive experiments, we observe that the performance of current UGDA models varies significantly across different datasets and adaptation scenarios. Specifically, we recognize that when the source and target graphs face significant distribution shifts, it is imperative to formulate strategies to effectively address and mitigate graph structural shifts. We also find that with appropriate neighbourhood aggregation mechanisms, simple GNN variants can even surpass state-of-the-art UGDA baselines. To facilitate reproducibility, we have developed an easy-to-use library PyGDA for training and evaluating existing UGDA methods, providing a standardized platform in this community. Our source codes and datasets can be found at: https://github.com/pygda-team/pygda.
Read more7/17/2024

0
Can Modifying Data Address Graph Domain Adaptation?
Renhong Huang, Jiarong Xu, Xin Jiang, Ruichuan An, Yang Yang
Graph neural networks (GNNs) have demonstrated remarkable success in numerous graph analytical tasks. Yet, their effectiveness is often compromised in real-world scenarios due to distribution shifts, limiting their capacity for knowledge transfer across changing environments or domains. Recently, Unsupervised Graph Domain Adaptation (UGDA) has been introduced to resolve this issue. UGDA aims to facilitate knowledge transfer from a labeled source graph to an unlabeled target graph. Current UGDA efforts primarily focus on model-centric methods, such as employing domain invariant learning strategies and designing model architectures. However, our critical examination reveals the limitations inherent to these model-centric methods, while a data-centric method allowed to modify the source graph provably demonstrates considerable potential. This insight motivates us to explore UGDA from a data-centric perspective. By revisiting the theoretical generalization bound for UGDA, we identify two data-centric principles for UGDA: alignment principle and rescaling principle. Guided by these principles, we propose GraphAlign, a novel UGDA method that generates a small yet transferable graph. By exclusively training a GNN on this new graph with classic Empirical Risk Minimization (ERM), GraphAlign attains exceptional performance on the target graph. Extensive experiments under various transfer scenarios demonstrate the GraphAlign outperforms the best baselines by an average of 2.16%, training on the generated graph as small as 0.25~1% of the original training graph.
Read more7/30/2024