Learning Network Representations with Disentangled Graph Auto-Encoder

0

Sign in to get full access
Overview
- This paper presents a novel approach for learning disentangled representations using a Causal Flow-based Variational Auto-Encoder (CF-VAE).
- The proposed model aims to disentangle the latent representation by incorporating causal information into the variational auto-encoder framework.
- The authors demonstrate the effectiveness of their method on several benchmark datasets, showing improved disentanglement and reconstruction performance compared to previous approaches.
Plain English Explanation
The paper discusses a new way to extract meaningful and independent features from complex data, such as images or text. This is called "disentangled representation learning," and it's useful for tasks like image generation, data compression, and understanding the underlying factors that influence the data.
The key idea is to use a special type of neural network called a "Causal Flow-based Variational Auto-Encoder" (CF-VAE). This model tries to identify the causal relationships between the different features in the data, and then uses that information to learn a more disentangled representation.
For example, imagine you have an image of a person's face. The CF-VAE would try to identify the independent factors that influence the face, such as the person's identity, expression, and lighting conditions. By learning a disentangled representation, the model can better understand and manipulate these individual factors, which could be useful for tasks like generating new faces or enhancing the interpretability of autonomous driving systems.
The authors demonstrate that their CF-VAE model outperforms previous methods on several benchmark datasets, showing improved disentanglement and reconstruction performance. This suggests that incorporating causal information can be a powerful approach for learning more meaningful and useful representations of complex data.
Technical Explanation
The paper introduces a novel model called the Causal Flow-based Variational Auto-Encoder (CF-VAE), which aims to learn disentangled representations of data by incorporating causal information into the variational auto-encoder (VAE) framework.
The key components of the CF-VAE model are:
- A causal flow module, which learns a invertible transformation between the observed data and the latent representation, while capturing the causal relationships between the latent factors.
- A disentanglement module, which encourages the latent representation to be factorized and independent.
- A reconstruction module, which generates the observed data from the disentangled latent representation.
The authors show that by jointly optimizing these three modules, the CF-VAE is able to learn a more disentangled latent representation compared to previous variational auto-encoder and graph auto-encoder based methods.
The authors evaluate the CF-VAE on several benchmark datasets, including dSprites, Cars3D, and MPI3D, and demonstrate improved disentanglement and reconstruction performance compared to state-of-the-art approaches, such as VCCA.
Critical Analysis
The paper presents a compelling approach for learning disentangled representations by incorporating causal information into the VAE framework. The authors provide a thorough evaluation of their method and demonstrate its advantages over previous techniques.
However, the paper does not discuss the potential limitations or challenges of the CF-VAE model. For example, the authors do not address the computational complexity of the causal flow module, which may limit the scalability of the approach to larger-scale datasets or more complex data distributions.
Additionally, the paper does not explore the robustness of the CF-VAE to noisy or incomplete data, which is an important consideration for real-world applications. It would be interesting to see how the model performs in the presence of missing or corrupted observations, and whether the causal information can help the model overcome these challenges.
Furthermore, the paper does not delve into the interpretability of the learned disentangled representations. While the authors claim that the CF-VAE can learn more meaningful and independent factors, they do not provide a detailed analysis of the semantics or the interpretability of the latent dimensions.
Overall, the paper presents a novel and promising approach for disentangled representation learning, but there are opportunities for further research to address the potential limitations and explore the practical applications of the CF-VAE model.
Conclusion
The Causal Flow-based Variational Auto-Encoder (CF-VAE) introduced in this paper represents a significant advancement in the field of disentangled representation learning. By incorporating causal information into the VAE framework, the CF-VAE is able to learn more meaningful and independent latent factors from complex data, which could have important implications for a wide range of applications, such as image generation, data compression, and autonomous driving.
The authors have demonstrated the effectiveness of their approach on several benchmark datasets, and the results suggest that the CF-VAE outperforms previous disentanglement methods in terms of both reconstruction quality and the degree of disentanglement achieved. While the paper does not address all the potential limitations of the model, it represents an important step forward in the quest to develop more interpretable and controllable representations of complex data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Network Representations with Disentangled Graph Auto-Encoder
Di Fan, Chuanhou Gao
The (variational) graph auto-encoder is widely used to learn representations for graph-structured data. However, the formation of real-world graphs is a complicated and heterogeneous process influenced by latent factors. Existing encoders are fundamentally holistic, neglecting the entanglement of latent factors. This reduces the effectiveness of graph analysis tasks, while also making it more difficult to explain the learned representations. As a result, learning disentangled graph representations with the (variational) graph auto-encoder poses significant challenges and remains largely unexplored in the current research. In this paper, we introduce the Disentangled Graph Auto-Encoder (DGA) and the Disentangled Variational Graph Auto-Encoder (DVGA) to learn disentangled representations. Specifically, we first design a disentangled graph convolutional network with multi-channel message-passing layers to serve as the encoder. This allows each channel to aggregate information about each latent factor. The disentangled variational graph auto-encoder's expressive capability is then enhanced by applying a component-wise flow to each channel. In addition, we construct a factor-wise decoder that takes into account the characteristics of disentangled representations. We improve the independence of representations by imposing independence constraints on the mapping channels for distinct latent factors. Empirical experiments on both synthetic and real-world datasets demonstrate the superiority of our proposed method compared to several state-of-the-art baselines.
Read more7/17/2024
🚀
0
Causal Flow-based Variational Auto-Encoder for Disentangled Causal Representation Learning
Di Fan, Yannian Kou, Chuanhou Gao
Disentangled representation learning aims to learn low-dimensional representations of data, where each dimension corresponds to an underlying generative factor. Currently, Variational Auto-Encoder (VAE) are widely used for disentangled representation learning, with the majority of methods assuming independence among generative factors. However, in real-world scenarios, generative factors typically exhibit complex causal relationships. We thus design a new VAE-based framework named Disentangled Causal Variational Auto-Encoder (DCVAE), which includes a variant of autoregressive flows known as causal flows, capable of learning effective causal disentangled representations. We provide a theoretical analysis of the disentanglement identifiability of DCVAE, ensuring that our model can effectively learn causal disentangled representations. The performance of DCVAE is evaluated on both synthetic and real-world datasets, demonstrating its outstanding capability in achieving causal disentanglement and performing intervention experiments. Moreover, DCVAE exhibits remarkable performance on downstream tasks and has the potential to learn the true causal structure among factors.
Read more5/9/2024

0
Disentangled Generative Graph Representation Learning
Xinyue Hu, Zhibin Duan, Xinyang Liu, Yuxin Li, Bo Chen, Mingyuan Zhou
Recently, generative graph models have shown promising results in learning graph representations through self-supervised methods. However, most existing generative graph representation learning (GRL) approaches rely on random masking across the entire graph, which overlooks the entanglement of learned representations. This oversight results in non-robustness and a lack of explainability. Furthermore, disentangling the learned representations remains a significant challenge and has not been sufficiently explored in GRL research. Based on these insights, this paper introduces DiGGR (Disentangled Generative Graph Representation Learning), a self-supervised learning framework. DiGGR aims to learn latent disentangled factors and utilizes them to guide graph mask modeling, thereby enhancing the disentanglement of learned representations and enabling end-to-end joint learning. Extensive experiments on 11 public datasets for two different graph learning tasks demonstrate that DiGGR consistently outperforms many previous self-supervised methods, verifying the effectiveness of the proposed approach.
Read more8/27/2024
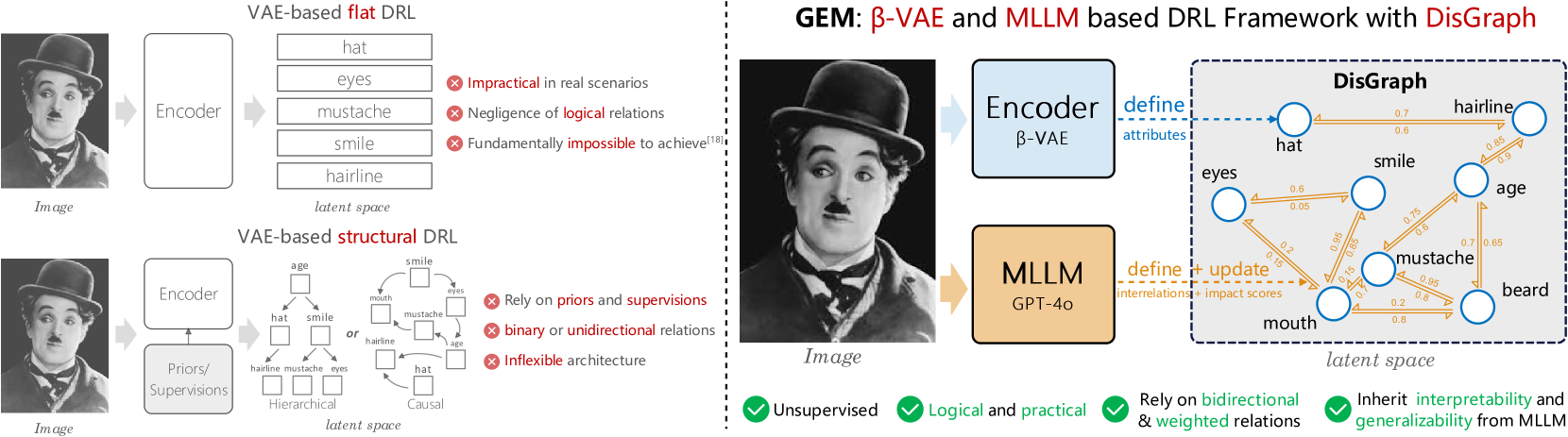
0
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
Baao Xie, Qiuyu Chen, Yunnan Wang, Zequn Zhang, Xin Jin, Wenjun Zeng
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
Read more7/30/2024