Graph is all you need? Lightweight data-agnostic neural architecture search without training
2405.01306
0
0
Abstract
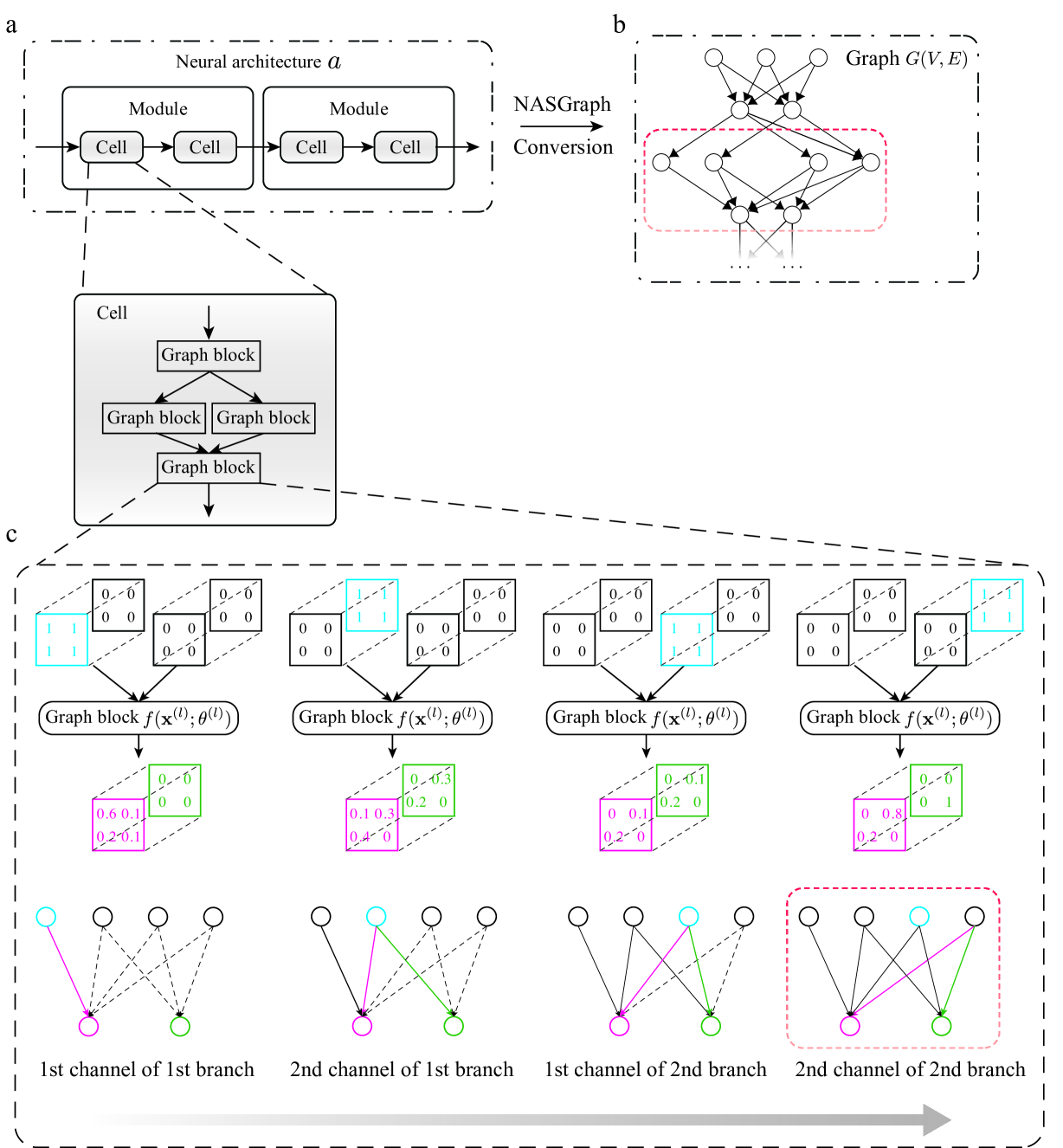
Neural architecture search (NAS) enables the automatic design of neural network models. However, training the candidates generated by the search algorithm for performance evaluation incurs considerable computational overhead. Our method, dubbed nasgraph, remarkably reduces the computational costs by converting neural architectures to graphs and using the average degree, a graph measure, as the proxy in lieu of the evaluation metric. Our training-free NAS method is data-agnostic and light-weight. It can find the best architecture among 200 randomly sampled architectures from NAS-Bench201 in 217 CPU seconds. Besides, our method is able to achieve competitive performance on various datasets including NASBench-101, NASBench-201, and NDS search spaces. We also demonstrate that nasgraph generalizes to more challenging tasks on Micro TransNAS-Bench-101.
Create account to get full access
Overview
- This paper introduces a new neural architecture search (NAS) method that does not require training the candidate models.
- The proposed approach, called Graph is All You Need (GAYN), leverages graph neural networks to predict the performance of neural architectures without actually training them.
- GAYN is designed to be lightweight, data-agnostic, and efficient, addressing limitations of existing NAS techniques that are computationally intensive and rely on task-specific training.
Plain English Explanation
The paper presents a new way to search for the best neural network architecture, without actually having to train the full models. This is an important problem because training neural networks can be very computationally expensive and time-consuming. The GAYN method uses graph neural networks to analyze the structure of the neural network itself and predict how well it will perform, rather than training it from scratch. This makes the search process much faster and more efficient.
The key insight is that the structure of the neural network, represented as a graph, contains a lot of useful information that can be used to estimate its performance. By analyzing this graph structure, GAYN can identify promising architectures without having to train them. This data-agnostic approach means the method can be applied to a wide range of tasks, without needing task-specific training data.
The authors show that GAYN is able to find high-performing neural network architectures quickly, and that the predicted performance closely matches the actual performance when the models are trained. This represents an important advance in the field of neural architecture search, potentially enabling the development of more efficient and capable AI models with less computational overhead.
Technical Explanation
The GAYN method represents the neural network architecture as a graph, with nodes corresponding to the individual layers and edges representing the connections between them. A graph neural network is then used to analyze the structure of this graph and predict the performance of the architecture, without having to train the model.
The key components of the GAYN approach are:
- Architecture Encoding: The neural network is converted into a graph representation, where each layer is a node and the connections between layers are edges.
- Graph Neural Network: A specialized graph neural network is used to analyze the structure of the architecture graph and predict the model's performance.
- Performance Prediction: The graph neural network outputs a predicted performance metric (e.g. accuracy) for the input architecture, without requiring any training of the actual model.
The authors demonstrate the effectiveness of GAYN on several benchmark tasks, including computer vision and language modeling. They show that GAYN can accurately predict the performance of neural architectures, and that the identified high-performing models achieve competitive results when trained from scratch.
Importantly, GAYN is data-agnostic, meaning it does not require any task-specific training data. This makes it a flexible and lightweight approach to neural architecture search, addressing limitations of existing techniques that are computationally intensive and task-dependent.
Critical Analysis
The GAYN approach represents an interesting and promising development in the field of neural architecture search. By leveraging graph neural networks to predict model performance without training, the method addresses key limitations of existing NAS techniques.
However, the paper does not fully explore the limitations and potential issues with the GAYN approach. For example, the authors do not discuss how the graph representation of the neural network might impact the performance prediction, or how sensitive the method is to changes in the graph neural network architecture.
Additionally, while the authors demonstrate the effectiveness of GAYN on several benchmark tasks, it is unclear how well the method would scale to larger and more complex neural networks, or how it would perform on real-world, high-stakes applications.
Further research is needed to better understand the strengths, weaknesses, and broader applicability of the GAYN approach. Rigorous comparisons to other NAS methods, as well as more extensive testing on diverse datasets and architectures, would help strengthen the claims made in the paper.
Conclusion
The GAYN method represents an innovative approach to neural architecture search that avoids the need for computationally intensive model training. By leveraging graph neural networks to predict the performance of candidate architectures, the method can efficiently identify high-performing models without the overhead of full training.
This work addresses important limitations of existing NAS techniques and has the potential to enable the development of more efficient and capable AI systems. While the paper highlights the promise of the GAYN approach, further research is needed to fully understand its strengths, weaknesses, and broader applicability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
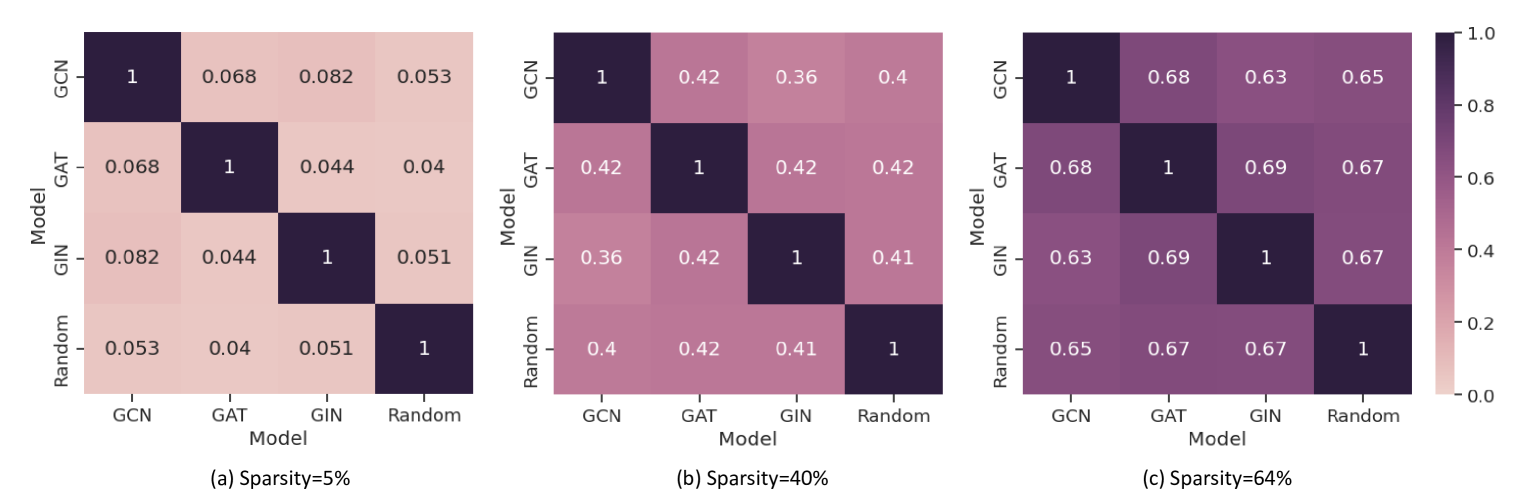
Towards Lightweight Graph Neural Network Search with Curriculum Graph Sparsification
Beini Xie, Heng Chang, Ziwei Zhang, Zeyang Zhang, Simin Wu, Xin Wang, Yuan Meng, Wenwu Zhu
0
0
Graph Neural Architecture Search (GNAS) has achieved superior performance on various graph-structured tasks. However, existing GNAS studies overlook the applications of GNAS in resource-constraint scenarios. This paper proposes to design a joint graph data and architecture mechanism, which identifies important sub-architectures via the valuable graph data. To search for optimal lightweight Graph Neural Networks (GNNs), we propose a Lightweight Graph Neural Architecture Search with Graph SparsIfication and Network Pruning (GASSIP) method. In particular, GASSIP comprises an operation-pruned architecture search module to enable efficient lightweight GNN search. Meanwhile, we design a novel curriculum graph data sparsification module with an architecture-aware edge-removing difficulty measurement to help select optimal sub-architectures. With the aid of two differentiable masks, we iteratively optimize these two modules to efficiently search for the optimal lightweight architecture. Extensive experiments on five benchmarks demonstrate the effectiveness of GASSIP. Particularly, our method achieves on-par or even higher node classification performance with half or fewer model parameters of searched GNNs and a sparser graph.
6/26/2024
🧠
A Lightweight Neural Architecture Search Model for Medical Image Classification
Lunchen Xie, Eugenio Lomurno, Matteo Gambella, Danilo Ardagna, Manuel Roveri, Matteo Matteucci, Qingjiang Shi
0
0
Accurate classification of medical images is essential for modern diagnostics. Deep learning advancements led clinicians to increasingly use sophisticated models to make faster and more accurate decisions, sometimes replacing human judgment. However, model development is costly and repetitive. Neural Architecture Search (NAS) provides solutions by automating the design of deep learning architectures. This paper presents ZO-DARTS+, a differentiable NAS algorithm that improves search efficiency through a novel method of generating sparse probabilities by bi-level optimization. Experiments on five public medical datasets show that ZO-DARTS+ matches the accuracy of state-of-the-art solutions while reducing search times by up to three times.
5/7/2024
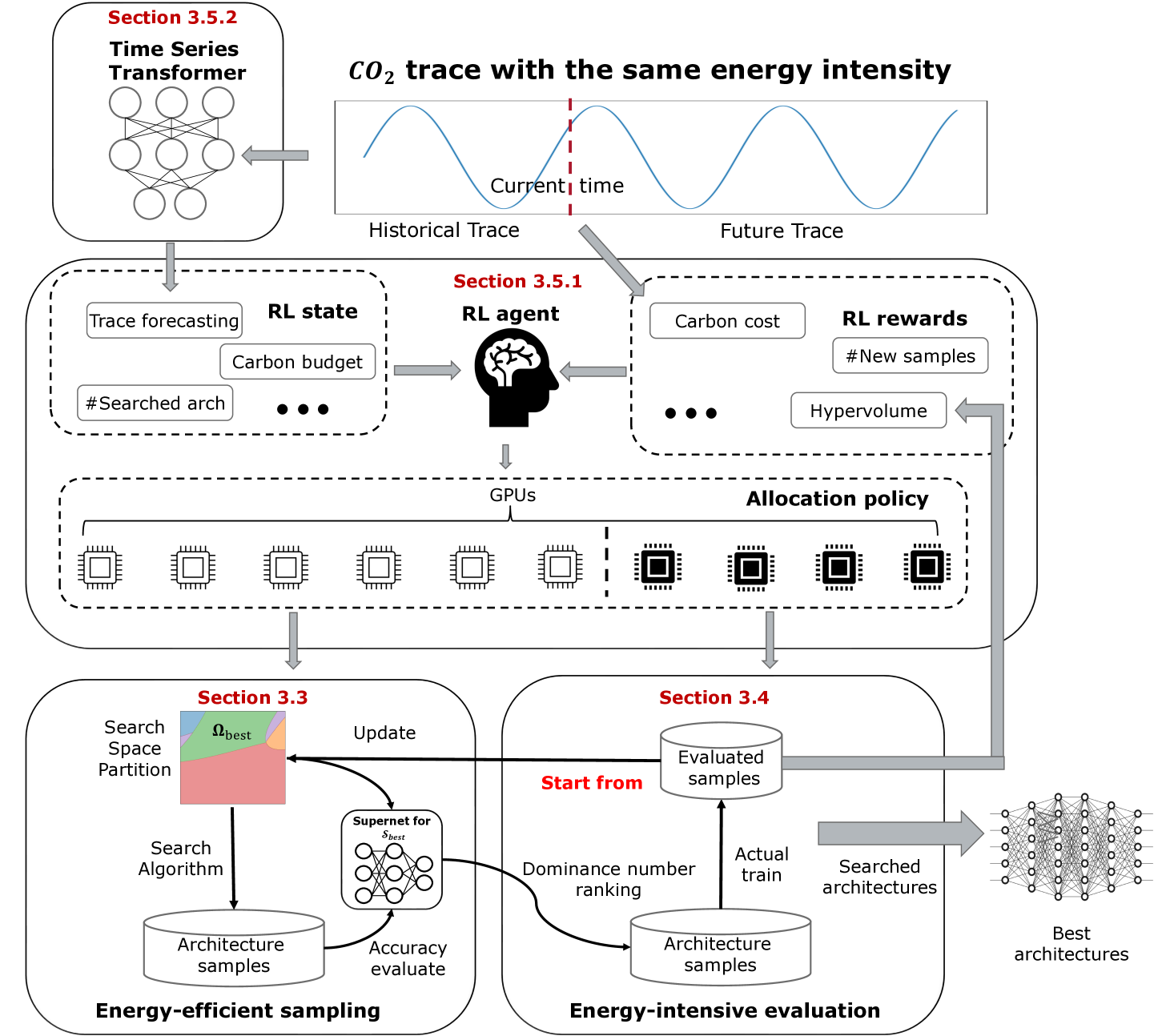
CE-NAS: An End-to-End Carbon-Efficient Neural Architecture Search Framework
Yiyang Zhao, Yunzhuo Liu, Bo Jiang, Tian Guo
0
0
This work presents a novel approach to neural architecture search (NAS) that aims to increase carbon efficiency for the model design process. The proposed framework CE-NAS addresses the key challenge of high carbon cost associated with NAS by exploring the carbon emission variations of energy and energy differences of different NAS algorithms. At the high level, CE-NAS leverages a reinforcement-learning agent to dynamically adjust GPU resources based on carbon intensity, predicted by a time-series transformer, to balance energy-efficient sampling and energy-intensive evaluation tasks. Furthermore, CE-NAS leverages a recently proposed multi-objective optimizer to effectively reduce the NAS search space. We demonstrate the efficacy of CE-NAS in lowering carbon emissions while achieving SOTA results for both NAS datasets and open-domain NAS tasks. For example, on the HW-NasBench dataset, CE-NAS reduces carbon emissions by up to 7.22X while maintaining a search efficiency comparable to vanilla NAS. For open-domain NAS tasks, CE-NAS achieves SOTA results with 97.35% top-1 accuracy on CIFAR-10 with only 1.68M parameters and a carbon consumption of 38.53 lbs of CO2. On ImageNet, our searched model achieves 80.6% top-1 accuracy with a 0.78 ms TensorRT latency using FP16 on NVIDIA V100, consuming only 909.86 lbs of CO2, making it comparable to other one-shot-based NAS baselines.
6/4/2024

LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
Anthony Sarah, Sharath Nittur Sridhar, Maciej Szankin, Sairam Sundaresan
0
0
The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
5/29/2024