Accel-NASBench: Sustainable Benchmarking for Accelerator-Aware NAS

0

Sign in to get full access
Overview
- This paper introduces Accel-NASBench, a new benchmark for evaluating Neural Architecture Search (NAS) methods that consider hardware acceleration.
- Accel-NASBench aims to enable sustainable and fair benchmarking of NAS approaches by accounting for the performance of candidate architectures on specific hardware accelerators.
- The benchmark provides a comprehensive search space of neural network architectures and their corresponding hardware performance measurements on various accelerators.
Plain English Explanation
Designing the best neural network architecture for a given task can be a complex challenge. Neural Architecture Search (NAS) is a technique that automates this process by exploring different network designs and evaluating their performance.
However, traditional NAS methods often focus solely on the model's accuracy, ignoring the practical considerations of deploying the model on specific hardware platforms. The Accel-NASBench benchmark addresses this by providing a comprehensive dataset of neural network architectures and their performance on different hardware accelerators, such as GPUs and specialized AI chips.
By incorporating hardware-aware metrics into the NAS process, researchers and engineers can develop neural network designs that not only perform well but also run efficiently on the target deployment hardware. This is crucial for real-world applications, where factors like power consumption, latency, and throughput are just as important as accuracy.
The Accel-NASBench dataset allows researchers to explore the tradeoffs between model performance and hardware efficiency, helping them create neural networks that are both effective and practical for deployment.
Technical Explanation
The Accel-NASBench benchmark builds upon the popular NASBench dataset, which provides a predefined search space of neural network architectures and their corresponding accuracy on various tasks. Accel-NASBench extends this by including hardware performance measurements, such as inference latency and energy consumption, for each architecture on different accelerator platforms.
The researchers curated a diverse set of 30,000 neural network architectures and evaluated their performance on four hardware accelerators: NVIDIA Jetson Nano, NVIDIA Jetson Xavier NX, Google Edge TPU, and Intel Neural Compute Stick 2. This comprehensive dataset allows NAS algorithms to consider both model accuracy and hardware-specific metrics during the architecture search process.
To demonstrate the value of the Accel-NASBench benchmark, the authors conducted several experiments comparing the performance of NAS methods that optimize for accuracy alone versus those that also consider hardware efficiency. The results showed that hardware-aware NAS approaches can identify architectures that are both accurate and efficient on the target hardware, highlighting the importance of incorporating such considerations into the search process.
Critical Analysis
The Accel-NASBench benchmark is a valuable contribution to the field of neural architecture search, as it addresses a critical gap in existing NAS frameworks. By incorporating hardware performance data, the benchmark enables researchers to develop NAS methods that are more aligned with real-world deployment scenarios.
One potential limitation of the benchmark is the scope of the hardware platforms included. While the four accelerators selected cover a range of device categories, the performance characteristics of other hardware, such as high-end GPUs or specialized AI chips, are not represented. Expanding the benchmark to include a more diverse set of accelerators would further enhance its utility.
Additionally, the benchmark focuses on static neural network architectures and does not consider dynamic models or those with more complex control flow. Extending the benchmark to support a wider range of network structures and architectures could broaden its applicability.
Overall, the Accel-NASBench benchmark is a significant step forward in the pursuit of sustainable and practical neural architecture search. By bridging the gap between model performance and hardware efficiency, it paves the way for the development of more impactful and deployable AI systems.
Conclusion
The Accel-NASBench benchmark introduced in this paper represents a significant advancement in the field of neural architecture search. By incorporating hardware performance data into the search process, the benchmark enables the development of neural network architectures that are not only accurate but also efficient on target deployment platforms.
The comprehensive dataset and evaluation framework provided by Accel-NASBench can help researchers and engineers make more informed decisions about the trade-offs between model performance and hardware efficiency, ultimately leading to the creation of more practical and impactful AI systems. As the field of NAS continues to evolve, benchmarks like Accel-NASBench will play a crucial role in ensuring the sustainability and real-world applicability of the resulting architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Accel-NASBench: Sustainable Benchmarking for Accelerator-Aware NAS
Afzal Ahmad, Linfeng Du, Zhiyao Xie, Wei Zhang
One of the primary challenges impeding the progress of Neural Architecture Search (NAS) is its extensive reliance on exorbitant computational resources. NAS benchmarks aim to simulate runs of NAS experiments at zero cost, remediating the need for extensive compute. However, existing NAS benchmarks use synthetic datasets and model proxies that make simplified assumptions about the characteristics of these datasets and models, leading to unrealistic evaluations. We present a technique that allows searching for training proxies that reduce the cost of benchmark construction by significant margins, making it possible to construct realistic NAS benchmarks for large-scale datasets. Using this technique, we construct an open-source bi-objective NAS benchmark for the ImageNet2012 dataset combined with the on-device performance of accelerators, including GPUs, TPUs, and FPGAs. Through extensive experimentation with various NAS optimizers and hardware platforms, we show that the benchmark is accurate and allows searching for state-of-the-art hardware-aware models at zero cost.
Read more6/19/2024
0
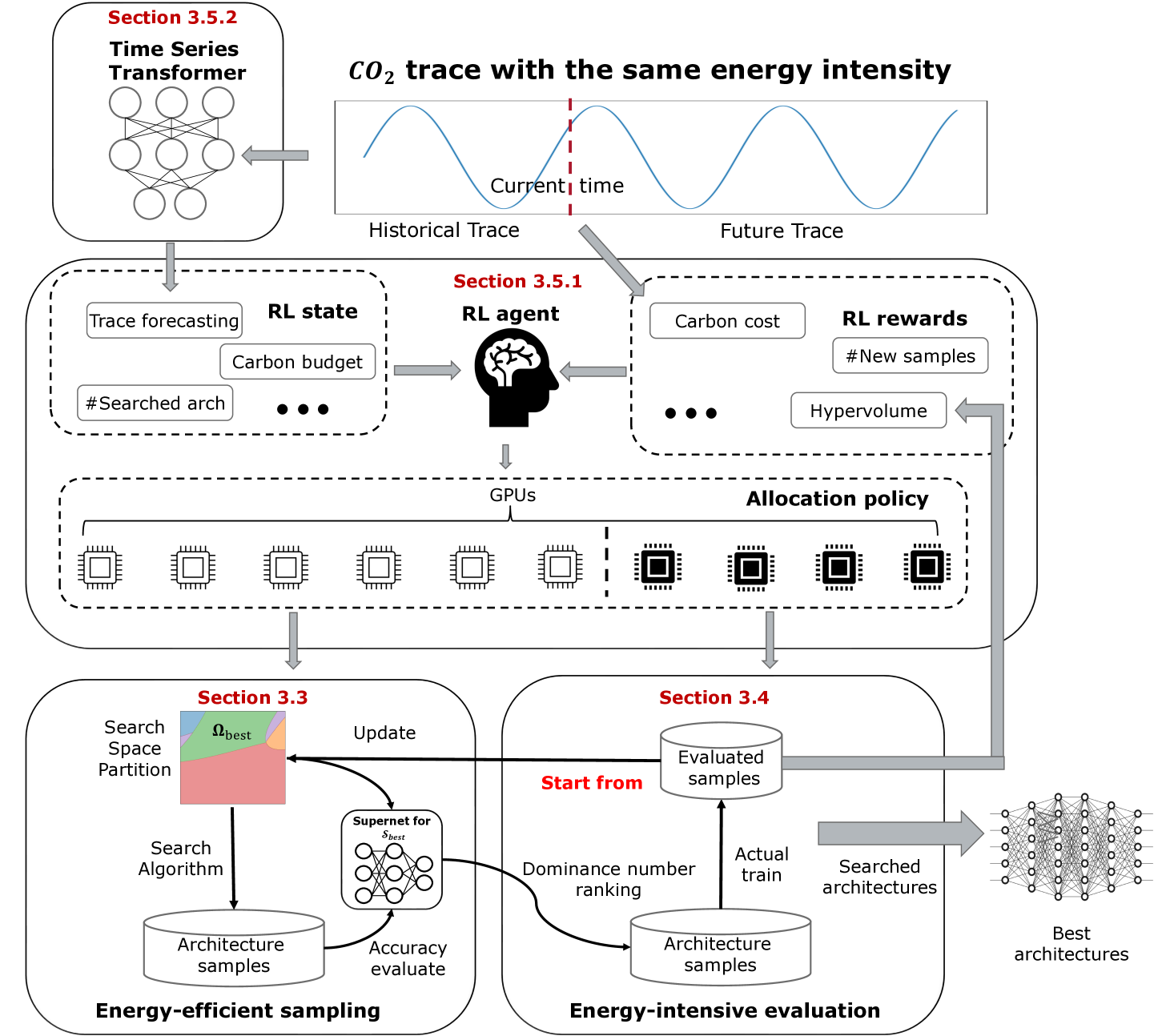
CE-NAS: An End-to-End Carbon-Efficient Neural Architecture Search Framework
Yiyang Zhao, Yunzhuo Liu, Bo Jiang, Tian Guo
This work presents a novel approach to neural architecture search (NAS) that aims to increase carbon efficiency for the model design process. The proposed framework CE-NAS addresses the key challenge of high carbon cost associated with NAS by exploring the carbon emission variations of energy and energy differences of different NAS algorithms. At the high level, CE-NAS leverages a reinforcement-learning agent to dynamically adjust GPU resources based on carbon intensity, predicted by a time-series transformer, to balance energy-efficient sampling and energy-intensive evaluation tasks. Furthermore, CE-NAS leverages a recently proposed multi-objective optimizer to effectively reduce the NAS search space. We demonstrate the efficacy of CE-NAS in lowering carbon emissions while achieving SOTA results for both NAS datasets and open-domain NAS tasks. For example, on the HW-NasBench dataset, CE-NAS reduces carbon emissions by up to 7.22X while maintaining a search efficiency comparable to vanilla NAS. For open-domain NAS tasks, CE-NAS achieves SOTA results with 97.35% top-1 accuracy on CIFAR-10 with only 1.68M parameters and a carbon consumption of 38.53 lbs of CO2. On ImageNet, our searched model achieves 80.6% top-1 accuracy with a 0.78 ms TensorRT latency using FP16 on NVIDIA V100, consuming only 909.86 lbs of CO2, making it comparable to other one-shot-based NAS baselines.
Read more7/19/2024
0
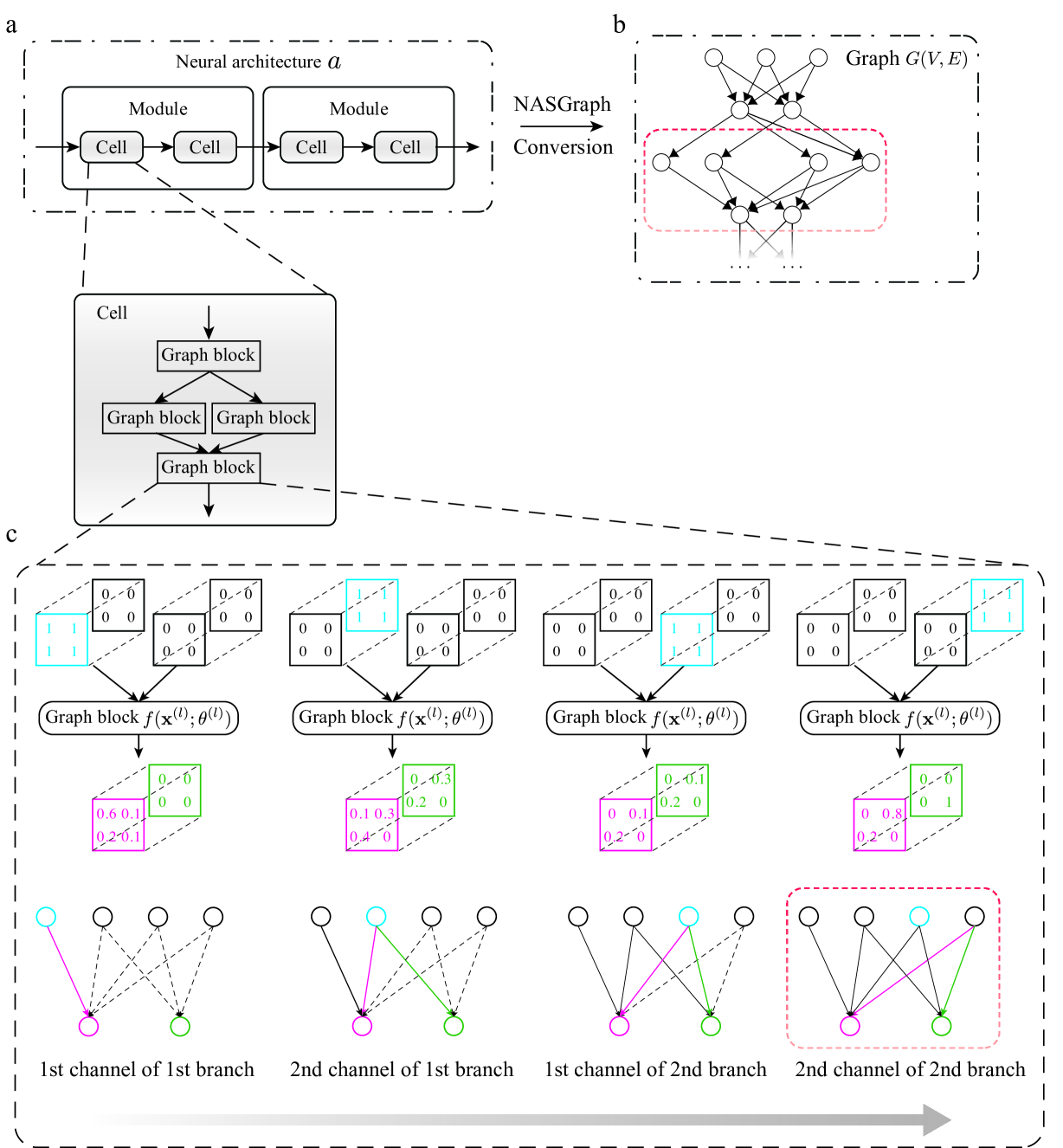
Graph is all you need? Lightweight data-agnostic neural architecture search without training
Zhenhan Huang, Tejaswini Pedapati, Pin-Yu Chen, Chunhen Jiang, Jianxi Gao
Neural architecture search (NAS) enables the automatic design of neural network models. However, training the candidates generated by the search algorithm for performance evaluation incurs considerable computational overhead. Our method, dubbed nasgraph, remarkably reduces the computational costs by converting neural architectures to graphs and using the average degree, a graph measure, as the proxy in lieu of the evaluation metric. Our training-free NAS method is data-agnostic and light-weight. It can find the best architecture among 200 randomly sampled architectures from NAS-Bench201 in 217 CPU seconds. Besides, our method is able to achieve competitive performance on various datasets including NASBench-101, NASBench-201, and NDS search spaces. We also demonstrate that nasgraph generalizes to more challenging tasks on Micro TransNAS-Bench-101.
Read more5/3/2024
0
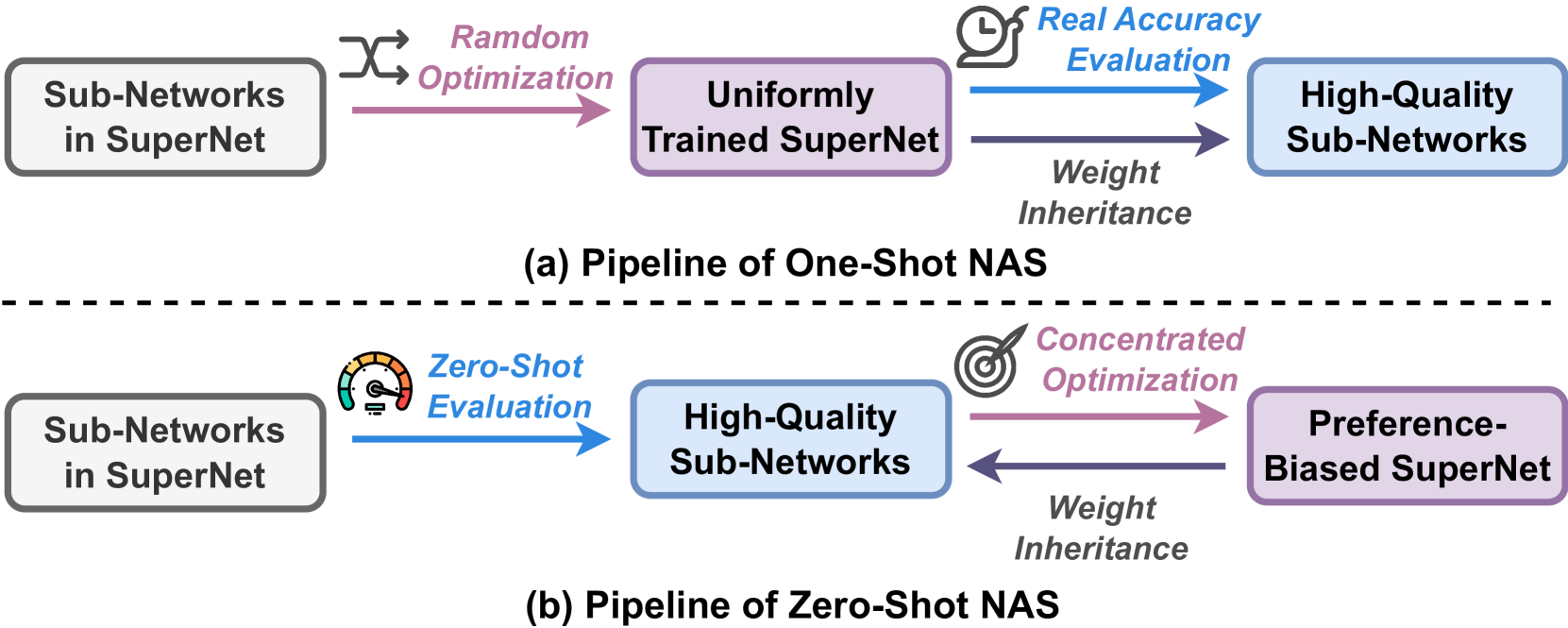
NASH: Neural Architecture and Accelerator Search for Multiplication-Reduced Hybrid Models
Yang Xu, Huihong Shi, Zhongfeng Wang
The significant computational cost of multiplications hinders the deployment of deep neural networks (DNNs) on edge devices. While multiplication-free models offer enhanced hardware efficiency, they typically sacrifice accuracy. As a solution, multiplication-reduced hybrid models have emerged to combine the benefits of both approaches. Particularly, prior works, i.e., NASA and NASA-F, leverage Neural Architecture Search (NAS) to construct such hybrid models, enhancing hardware efficiency while maintaining accuracy. However, they either entail costly retraining or encounter gradient conflicts, limiting both search efficiency and accuracy. Additionally, they overlook the acceleration opportunity introduced by accelerator search, yielding sub-optimal hardware performance. To overcome these limitations, we propose NASH, a Neural architecture and Accelerator Search framework for multiplication-reduced Hybrid models. Specifically, as for NAS, we propose a tailored zero-shot metric to pre-identify promising hybrid models before training, enhancing search efficiency while alleviating gradient conflicts. Regarding accelerator search, we innovatively introduce coarse-to-fine search to streamline the search process. Furthermore, we seamlessly integrate these two levels of searches to unveil NASH, obtaining the optimal model and accelerator pairing. Experiments validate our effectiveness, e.g., when compared with the state-of-the-art multiplication-based system, we can achieve $uparrow$$2.14times$ throughput and $uparrow$$2.01times$ FPS with $uparrow$$0.25%$ accuracy on CIFAR-100, and $uparrow$$1.40times$ throughput and $uparrow$$1.19times$ FPS with $uparrow$$0.56%$ accuracy on Tiny-ImageNet. Codes are available at url{https://github.com/xuyang527/NASH.}
Read more9/10/2024