LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
2405.18377
0
0

Abstract
The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
Create account to get full access
Overview
- This paper presents LLaMA-NAS, an efficient neural architecture search (NAS) method for large language models (LLMs) like LLaMA.
- The authors show that LLaMA-NAS can discover high-performance architectures for LLMs that are 2-4x smaller and faster than baseline models, without sacrificing quality.
- LLaMA-NAS leverages techniques like structural pruning and graph-based modeling to enable efficient architecture search for LLMs.
Plain English Explanation
The paper describes a new method called LLaMA-NAS that can automatically design efficient neural network architectures for large language models (LLMs) like LLaMA. LLMs are powerful AI systems that can understand and generate human language, but they are often very large and computationally intensive.
LLaMA-NAS uses a technique called neural architecture search (NAS) to explore different possible network designs and find ones that are much smaller and faster, but still perform well on language tasks. The key ideas are to use structural pruning to remove unnecessary parts of the network, and to model the network as a graph to make the search more efficient.
By using LLaMA-NAS, the authors were able to create LLM architectures that are 2-4 times smaller and faster than baseline models, without losing much performance. This could enable the deployment of powerful language models on a wider range of devices and applications, including edge devices and mobile networks.
Technical Explanation
The core of the LLaMA-NAS method is a neural architecture search (NAS) process that explores different network designs for large language models (LLMs) like LLaMA. The authors use a two-stage approach:
- Supernet Training: They first train a large "supernet" that contains many possible sub-architectures. This allows the model to learn general features that are useful across a wide range of designs.
- Architecture Search: They then use an efficient graph-based NAS algorithm to search over the supernet and find high-performing sub-architectures that are smaller and faster than the original model.
Key innovations in LLaMA-NAS include:
- Structural Pruning: The authors use structured pruning techniques to remove entire layers or attention heads from the supernet, reducing its size and complexity.
- Graph-based Modeling: The supernet is represented as a graph, with nodes corresponding to network layers and edges representing the connections between them. This allows for more efficient exploration of the search space.
- Progressive Shrinking: The search process starts with a large supernet and gradually shrinks it down to find smaller, more efficient architectures.
Through extensive experiments, the authors show that LLaMA-NAS can discover LLM architectures that are 2-4x smaller and faster than baseline models, while maintaining comparable performance on language tasks.
Critical Analysis
The LLaMA-NAS method represents an important advance in the field of efficient neural architecture design for large language models. By leveraging techniques like structural pruning and graph-based modeling, the authors are able to significantly reduce the size and computational requirements of LLMs without sacrificing much in terms of performance.
However, there are a few potential limitations and areas for further research that could be explored:
- Generalization to Other LLMs: The experiments in the paper focus on the LLaMA model, and it's unclear how well the LLaMA-NAS approach would generalize to other large language models. Further testing on a wider range of LLMs would be helpful.
- Hardware-Aware Optimization: The current version of LLaMA-NAS does not explicitly consider hardware-specific constraints, such as memory usage or inference latency. Incorporating these factors into the architecture search process could lead to even more practical and deployable models.
- Interpretability and Explainability: The paper does not provide much insight into the architectural decisions made by LLaMA-NAS or why certain sub-architectures were selected. Improving the interpretability of the method could make it more transparent and trustworthy.
Overall, the LLaMA-NAS approach is a promising step towards more efficient and accessible large language models, with potential applications in areas like edge computing and mobile networking. With further refinement and exploration, it could have a significant impact on the deployment and real-world use of powerful language AI systems.
Conclusion
The LLaMA-NAS method presented in this paper is a significant advancement in the field of efficient neural architecture design for large language models (LLMs). By leveraging techniques like structural pruning and graph-based modeling, the authors were able to discover LLM architectures that are 2-4 times smaller and faster than baseline models, without sacrificing much performance.
This could enable the deployment of powerful language AI systems on a wider range of devices and applications, including edge computing and mobile networks. While there are some limitations and areas for further research, the LLaMA-NAS method represents an important step towards more efficient and accessible large language models, with potentially far-reaching implications for the field of natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Structural Pruning of Pre-trained Language Models via Neural Architecture Search
Aaron Klein, Jacek Golebiowski, Xingchen Ma, Valerio Perrone, Cedric Archambeau
0
0
Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.
5/6/2024
Large Language Model Assisted Adversarial Robustness Neural Architecture Search
Rui Zhong, Yang Cao, Jun Yu, Masaharu Munetomo
0
0
Motivated by the potential of large language models (LLMs) as optimizers for solving combinatorial optimization problems, this paper proposes a novel LLM-assisted optimizer (LLMO) to address adversarial robustness neural architecture search (ARNAS), a specific application of combinatorial optimization. We design the prompt using the standard CRISPE framework (i.e., Capacity and Role, Insight, Statement, Personality, and Experiment). In this study, we employ Gemini, a powerful LLM developed by Google. We iteratively refine the prompt, and the responses from Gemini are adapted as solutions to ARNAS instances. Numerical experiments are conducted on NAS-Bench-201-based ARNAS tasks with CIFAR-10 and CIFAR-100 datasets. Six well-known meta-heuristic algorithms (MHAs) including genetic algorithm (GA), particle swarm optimization (PSO), differential evolution (DE), and its variants serve as baselines. The experimental results confirm the competitiveness of the proposed LLMO and highlight the potential of LLMs as effective combinatorial optimizers. The source code of this research can be downloaded from url{https://github.com/RuiZhong961230/LLMO}.
6/11/2024
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024
Graph is all you need? Lightweight data-agnostic neural architecture search without training
Zhenhan Huang, Tejaswini Pedapati, Pin-Yu Chen, Chunhen Jiang, Jianxi Gao
0
0
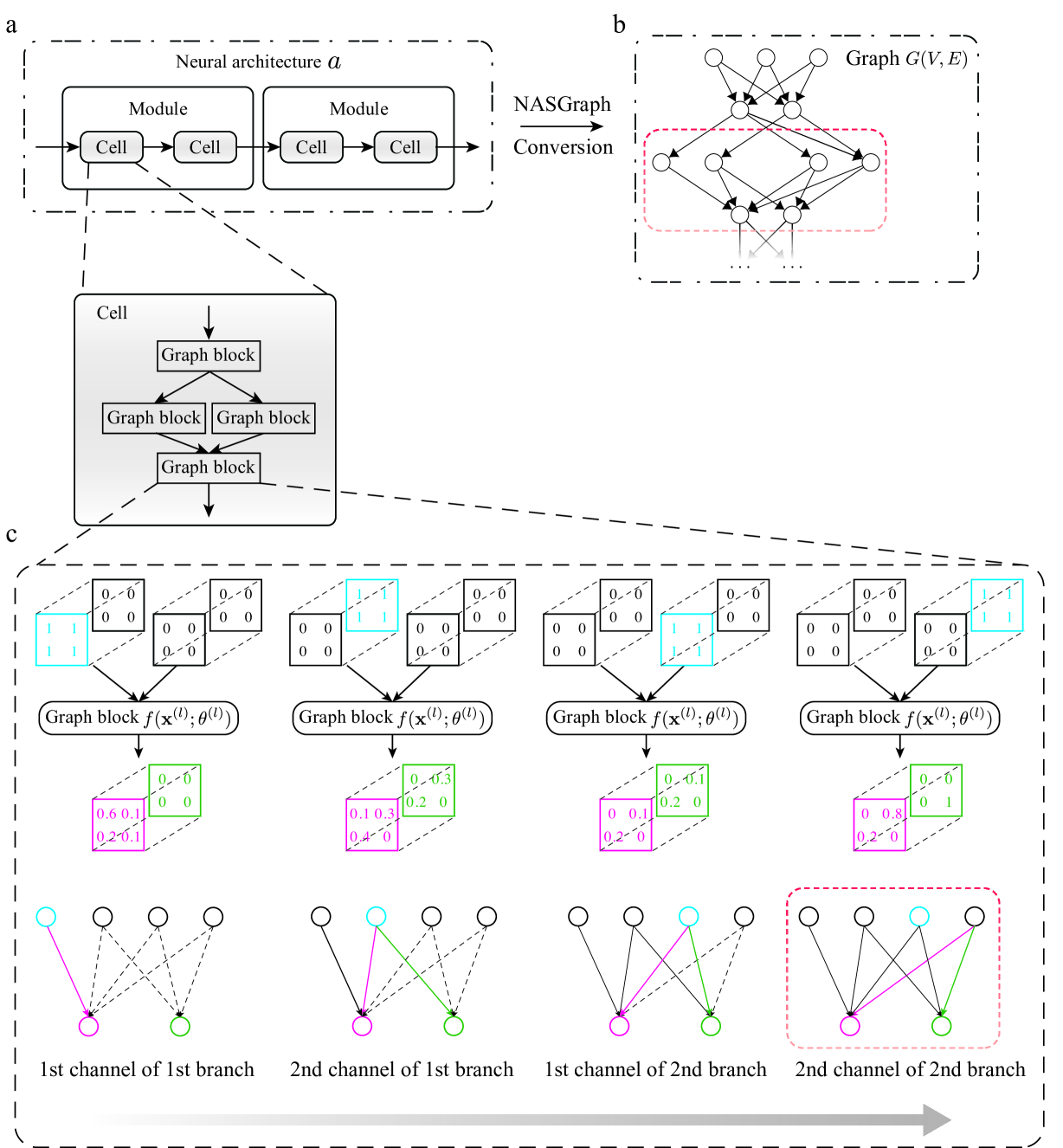
Neural architecture search (NAS) enables the automatic design of neural network models. However, training the candidates generated by the search algorithm for performance evaluation incurs considerable computational overhead. Our method, dubbed nasgraph, remarkably reduces the computational costs by converting neural architectures to graphs and using the average degree, a graph measure, as the proxy in lieu of the evaluation metric. Our training-free NAS method is data-agnostic and light-weight. It can find the best architecture among 200 randomly sampled architectures from NAS-Bench201 in 217 CPU seconds. Besides, our method is able to achieve competitive performance on various datasets including NASBench-101, NASBench-201, and NDS search spaces. We also demonstrate that nasgraph generalizes to more challenging tasks on Micro TransNAS-Bench-101.
5/3/2024