Neural Architecture Search via Two Constant Shared Weights Initialisations

0
🧠
Sign in to get full access
Overview
- In recent years, zero-cost metrics have gained traction in neural architecture search (NAS)
- These metrics allow finding optimal neural networks faster and with less computational load than traditional NAS methods
- They also provide insights into the internal workings of neural architectures
- This paper presents a zero-cost metric that is highly correlated with train set accuracy across multiple NAS benchmarks
Plain English Explanation
Designing the optimal neural network architecture for a given task can be a time-consuming and computationally-intensive process. Zero-cost metrics offer a potential solution by allowing researchers to quickly evaluate the potential of a neural architecture without fully training it.
The key idea behind this paper is to assess a neural network's performance based on the statistics of the outputs after two constant weight initializations. The researchers found that the dispersion of the outputs between these two initializations positively correlates with the eventual trained accuracy of the network. Normalizing this dispersion by the average output magnitude further improves the correlation.
This resulting metric, called epsilon, does not require gradient computations or human-labeled data. It can be quickly evaluated and easily integrated into existing NAS algorithms. By bypassing the need for training, epsilon helps accelerate the NAS process and provides insights into the inner workings of neural architectures without the overhead of full training.
Technical Explanation
The key contribution of this paper is a zero-cost metric, called epsilon, that is highly correlated with the train set accuracy of neural architectures across multiple NAS benchmark datasets (NAS-Bench-101, NAS-Bench-201, and NAS-Bench-NLP).
To compute epsilon, the researchers evaluate a neural network's potential based on the outputs' statistics after two constant shared weight initializations. Specifically, they use an unlabeled mini-batch of data to observe the dispersion of the network's outputs between the two initializations. They find that this dispersion positively correlates with the eventual trained accuracy of the network.
Further improvements are made by normalizing the dispersion by the average output magnitude. This normalized dispersion metric does not require gradient computations or human-labeled data, allowing it to be quickly evaluated.
The researchers demonstrate that epsilon can be easily integrated into existing NAS algorithms and takes only a fraction of a second to evaluate a single network. This makes it a promising tool for accelerating the NAS process and providing insights into the internal representations of neural architectures without the computational overhead of full training.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the correlation between epsilon and trained accuracy, while strong, is not perfect. This means that epsilon cannot fully replace traditional NAS methods but rather serves as a useful complement to quickly identify promising architectures.
Additionally, the researchers only evaluate epsilon on image classification and language modeling tasks. Its performance on other domains, such as reinforcement learning or generative modeling, remains to be seen.
Another potential concern is the reliance on constant weight initializations. While this allows for a fast evaluation, it may not fully capture the impact of more complex weight initialization schemes used in practice.
Despite these limitations, the epsilon metric represents a valuable contribution to the field of NAS. By providing a computationally-efficient way to evaluate neural architectures, it has the potential to accelerate research and development in areas that rely on neural networks.
Conclusion
This paper introduces a zero-cost metric, called epsilon, that is highly correlated with the train set accuracy of neural architectures. By evaluating the dispersion of a network's outputs after two constant weight initializations, epsilon provides a fast and computationally-efficient way to assess the potential of a neural architecture without the need for full training or human-labeled data.
While epsilon has limitations and cannot fully replace traditional NAS methods, it represents a promising step towards more efficient and insightful neural architecture search. By providing insights into the internal workings of neural networks and accelerating the NAS process, epsilon has the potential to drive significant advances in the field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Neural Architecture Search via Two Constant Shared Weights Initialisations
Ekaterina Gracheva
In recent years, zero-cost metrics are gaining ground in neural architecture search (NAS). There metrics allow finding the optimal neural network for a given task faster and with a lesser computational load than conventional NAS methods. Equally important is that they also shed some light on the internal workings of neural architectures. This paper presents a zero-cost metric that highly correlated with the train set accuracy across the NAS-Bench-101, NAS-Bench-201 and NAS-Bench-NLP benchmark datasets. We evaluate a neural achitecture's potential based on the outputs' statistics after two constant shared weights initialisations. For this, we only use an unlabelled mini-batch of data. We observe that the dispersion of the outputs between two initialisations positively correlates with trained accuracy. The correlation further improves when we normalise dispersion by average output magnitude. The resulting metric, epsilon, does not require gradients computation and unbinds the NAS procedure from training hyperparameters, loss metrics and human-labelled data. Our method is easy to integrate within existing NAS algorithms and takes a fraction of a second to evaluate a single network. The code supporting this study can be found on GitHub at https://github.com/egracheva/epsinas.
Read more4/11/2024
0
Graph is all you need? Lightweight data-agnostic neural architecture search without training
Zhenhan Huang, Tejaswini Pedapati, Pin-Yu Chen, Chunhen Jiang, Jianxi Gao
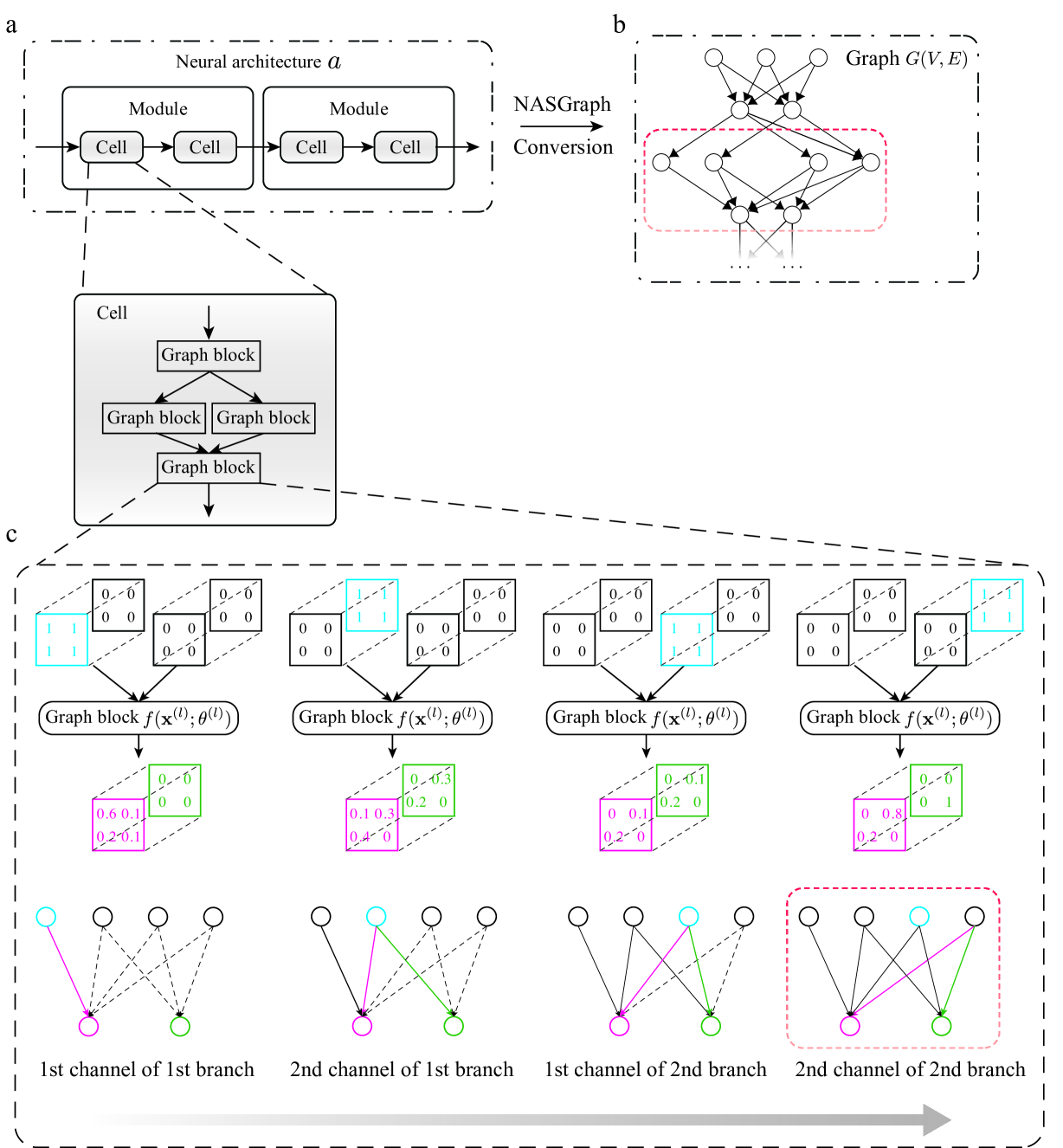
Neural architecture search (NAS) enables the automatic design of neural network models. However, training the candidates generated by the search algorithm for performance evaluation incurs considerable computational overhead. Our method, dubbed nasgraph, remarkably reduces the computational costs by converting neural architectures to graphs and using the average degree, a graph measure, as the proxy in lieu of the evaluation metric. Our training-free NAS method is data-agnostic and light-weight. It can find the best architecture among 200 randomly sampled architectures from NAS-Bench201 in 217 CPU seconds. Besides, our method is able to achieve competitive performance on various datasets including NASBench-101, NASBench-201, and NDS search spaces. We also demonstrate that nasgraph generalizes to more challenging tasks on Micro TransNAS-Bench-101.
Read more5/3/2024
0
Zero-Shot Neural Architecture Search: Challenges, Solutions, and Opportunities
Guihong Li, Duc Hoang, Kartikeya Bhardwaj, Ming Lin, Zhangyang Wang, Radu Marculescu
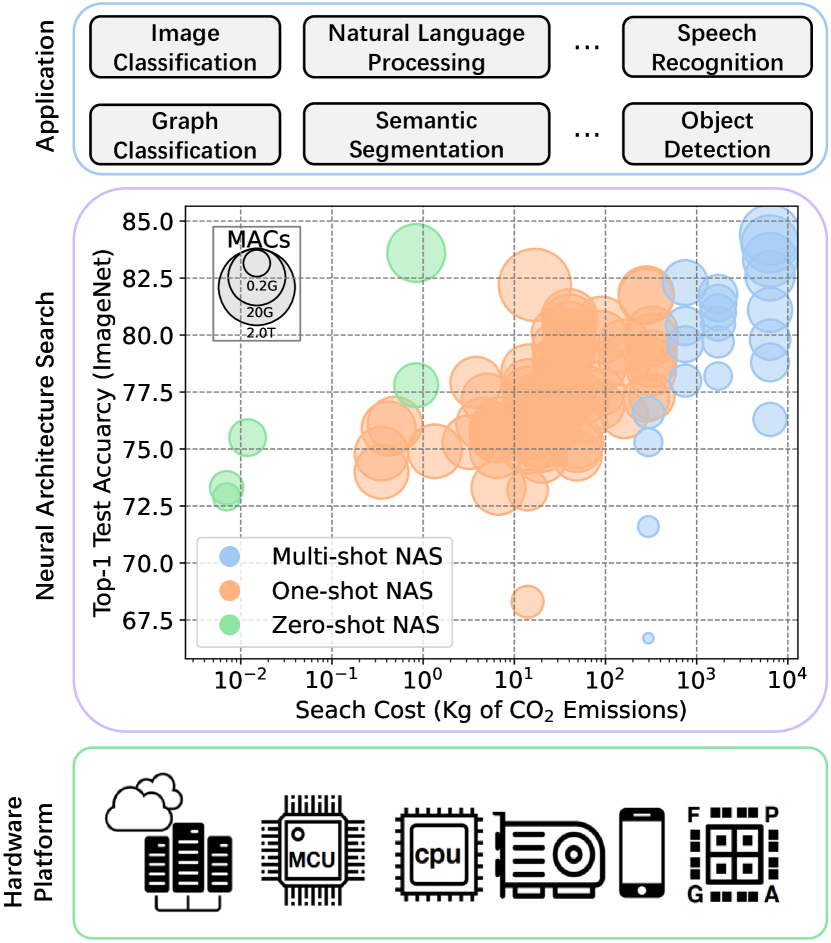
Recently, zero-shot (or training-free) Neural Architecture Search (NAS) approaches have been proposed to liberate NAS from the expensive training process. The key idea behind zero-shot NAS approaches is to design proxies that can predict the accuracy of some given networks without training the network parameters. The proxies proposed so far are usually inspired by recent progress in theoretical understanding of deep learning and have shown great potential on several datasets and NAS benchmarks. This paper aims to comprehensively review and compare the state-of-the-art (SOTA) zero-shot NAS approaches, with an emphasis on their hardware awareness. To this end, we first review the mainstream zero-shot proxies and discuss their theoretical underpinnings. We then compare these zero-shot proxies through large-scale experiments and demonstrate their effectiveness in both hardware-aware and hardware-oblivious NAS scenarios. Finally, we point out several promising ideas to design better proxies. Our source code and the list of related papers are available on https://github.com/SLDGroup/survey-zero-shot-nas.
Read more6/19/2024

0
Accel-NASBench: Sustainable Benchmarking for Accelerator-Aware NAS
Afzal Ahmad, Linfeng Du, Zhiyao Xie, Wei Zhang
One of the primary challenges impeding the progress of Neural Architecture Search (NAS) is its extensive reliance on exorbitant computational resources. NAS benchmarks aim to simulate runs of NAS experiments at zero cost, remediating the need for extensive compute. However, existing NAS benchmarks use synthetic datasets and model proxies that make simplified assumptions about the characteristics of these datasets and models, leading to unrealistic evaluations. We present a technique that allows searching for training proxies that reduce the cost of benchmark construction by significant margins, making it possible to construct realistic NAS benchmarks for large-scale datasets. Using this technique, we construct an open-source bi-objective NAS benchmark for the ImageNet2012 dataset combined with the on-device performance of accelerators, including GPUs, TPUs, and FPGAs. Through extensive experimentation with various NAS optimizers and hardware platforms, we show that the benchmark is accurate and allows searching for state-of-the-art hardware-aware models at zero cost.
Read more6/19/2024