Graph Retrieval-Augmented Generation: A Survey

0

Sign in to get full access
Overview
- Survey paper on graph retrieval-augmented generation, which combines large language models with knowledge graphs to generate more informative and factual content.
- Covers key concepts, architectures, applications, and evaluation of this emerging technique in natural language processing.
- Highlights the potential of this approach to improve the quality and reliability of AI-generated content.
Plain English Explanation
Graph retrieval-augmented generation is a technique that combines the power of large language models with the structured knowledge stored in knowledge graphs. Large language models are AI systems trained on massive amounts of text data that can generate human-like language. Knowledge graphs are databases that represent information as a network of interconnected entities and their relationships.
By integrating these two technologies, graph retrieval-augmented generation aims to produce more informative and factual content. The language model can draw upon the knowledge encoded in the graph to ground its outputs in real-world facts and relationships, rather than relying solely on patterns in the training data. This can help address issues like factual inaccuracy, inconsistency, and lack of grounding that can arise in pure language model generation.
The survey covers the key components of this approach, such as graph retrieval techniques to identify relevant information in the knowledge graph, and architectures that seamlessly integrate the language model and graph reasoning. It also discusses various applications of this technology, such as generating informative summaries, answering questions, and producing high-quality content.
Importantly, the survey also covers evaluation approaches to assess the performance and quality of graph retrieval-augmented generation systems. Measuring factors like factual accuracy, consistency, and relevance is crucial to ensuring these systems are reliable and beneficial.
Technical Explanation
The survey first provides an overview of the key concepts and motivation behind graph retrieval-augmented generation. It explains how large language models, while powerful at generating fluent text, can sometimes produce outputs that are factually inaccurate or inconsistent with real-world knowledge. Integrating knowledge graphs into the generation process can help address these limitations by grounding the outputs in structured data.
The paper then delves into the core technical components of this approach. It discusses graph retrieval techniques, such as using dense vector representations or graph neural networks to identify the most relevant subgraphs given the current generation context. It also covers architecture designs that seamlessly combine the language model and graph reasoning, such as retrieval-augmented generation models and end-to-end systems.
The survey also explores various applications of graph retrieval-augmented generation, including generating informative summaries, answering questions, and producing high-quality content. It highlights how this approach can improve the factual accuracy, consistency, and relevance of the generated outputs.
Importantly, the paper also delves into evaluation methods for these systems. It discusses metrics that assess the factual accuracy, coherence, and relevance of the generated text, as well as human evaluation approaches. Careful evaluation is crucial to ensuring these systems are reliable and beneficial.
Critical Analysis
The survey provides a comprehensive overview of the current state of graph retrieval-augmented generation research. However, it acknowledges several caveats and areas for further work:
-
Scalability and Efficiency: Retrieving and reasoning over large knowledge graphs can be computationally expensive, which may limit the scalability of these approaches. Developing more efficient retrieval and integration techniques is an important area for future research.
-
Knowledge Graph Quality and Coverage: The performance of these systems is heavily dependent on the quality and coverage of the underlying knowledge graphs. Improving knowledge graph construction and maintenance is an ongoing challenge.
-
Generalization and Domain Adaptation: Current approaches may perform well on specific tasks or domains, but generalizing to new contexts or adapting to different knowledge graphs remains an open problem.
-
Transparency and Interpretability: As with many AI systems, it can be difficult to understand the reasoning behind the generated outputs. Improving the interpretability of these models is crucial for building trust and accountability.
-
Ethical Considerations: The use of large language models and knowledge graphs raises ethical concerns around bias, privacy, and the potential misuse of AI-generated content. Careful consideration of these issues is needed as the technology matures.
Despite these limitations, the survey highlights the significant potential of graph retrieval-augmented generation to improve the quality and reliability of AI-generated content. As the field continues to evolve, addressing these challenges will be key to realizing the full benefits of this approach.
Conclusion
This survey provides a comprehensive overview of the emerging field of graph retrieval-augmented generation, which combines large language models with structured knowledge graphs to generate more informative and factual content. By grounding the generation process in real-world knowledge, this approach aims to address the limitations of pure language model generation, such as factual inaccuracy and lack of consistency.
The survey covers the key technical components of this approach, including graph retrieval techniques, architecture designs, and various applications. It also emphasizes the importance of rigorous evaluation to ensure the reliability and trustworthiness of these systems.
While the survey highlights several caveats and areas for further research, it underscores the significant potential of graph retrieval-augmented generation to improve the quality and usefulness of AI-generated content. As the field continues to evolve, addressing challenges around scalability, knowledge graph quality, and ethical considerations will be crucial to realizing the full benefits of this promising approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Graph Retrieval-Augmented Generation: A Survey
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, Siliang Tang
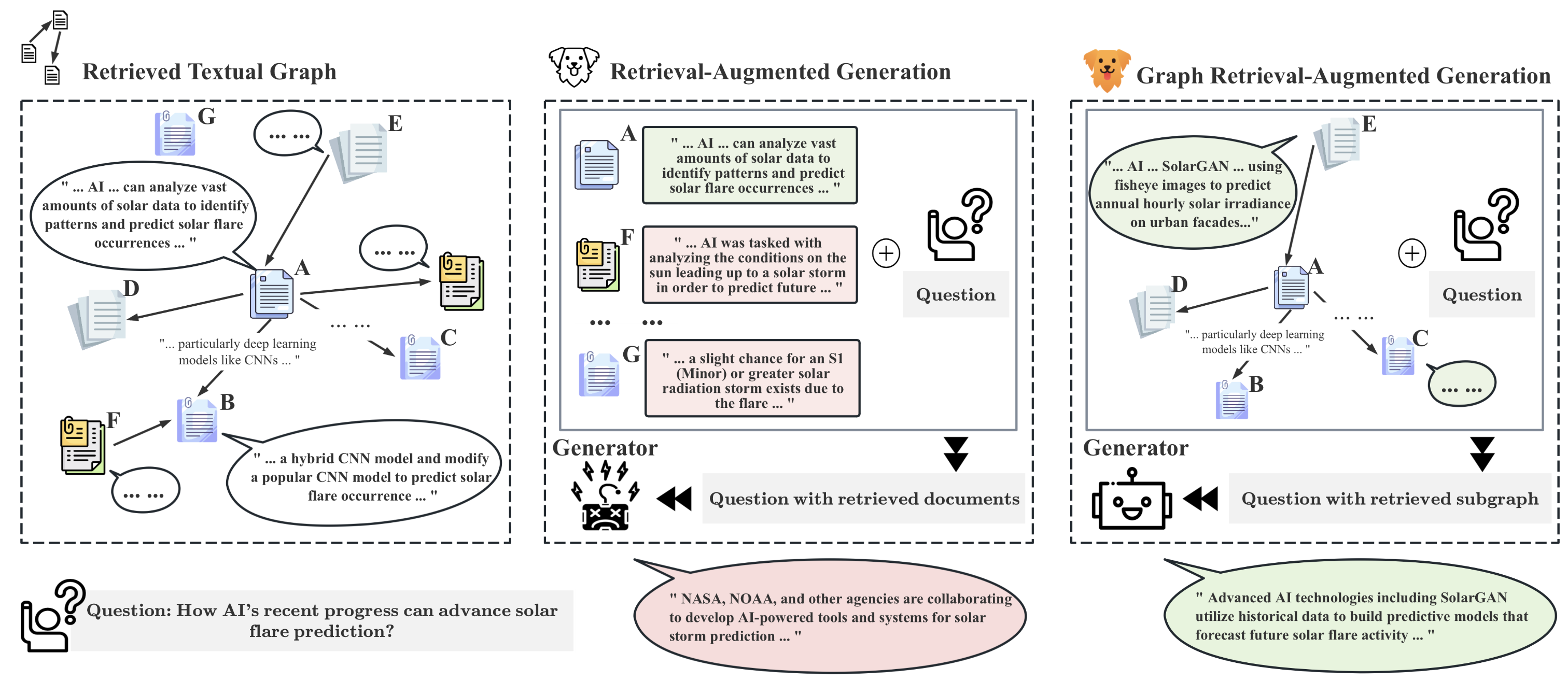
Recently, Retrieval-Augmented Generation (RAG) has achieved remarkable success in addressing the challenges of Large Language Models (LLMs) without necessitating retraining. By referencing an external knowledge base, RAG refines LLM outputs, effectively mitigating issues such as ``hallucination'', lack of domain-specific knowledge, and outdated information. However, the complex structure of relationships among different entities in databases presents challenges for RAG systems. In response, GraphRAG leverages structural information across entities to enable more precise and comprehensive retrieval, capturing relational knowledge and facilitating more accurate, context-aware responses. Given the novelty and potential of GraphRAG, a systematic review of current technologies is imperative. This paper provides the first comprehensive overview of GraphRAG methodologies. We formalize the GraphRAG workflow, encompassing Graph-Based Indexing, Graph-Guided Retrieval, and Graph-Enhanced Generation. We then outline the core technologies and training methods at each stage. Additionally, we examine downstream tasks, application domains, evaluation methodologies, and industrial use cases of GraphRAG. Finally, we explore future research directions to inspire further inquiries and advance progress in the field. In order to track recent progress in this field, we set up a repository at url{https://github.com/pengboci/GraphRAG-Survey}.
Read more9/11/2024
0
GRAG: Graph Retrieval-Augmented Generation
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, Liang Zhao
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.
Read more5/28/2024
⛏️
0
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
Retrieval-Augmented Generation (RAG) has recently gained traction in natural language processing. Numerous studies and real-world applications are leveraging its ability to enhance generative models through external information retrieval. Evaluating these RAG systems, however, poses unique challenges due to their hybrid structure and reliance on dynamic knowledge sources. To better understand these challenges, we conduct A Unified Evaluation Process of RAG (Auepora) and aim to provide a comprehensive overview of the evaluation and benchmarks of RAG systems. Specifically, we examine and compare several quantifiable metrics of the Retrieval and Generation components, such as relevance, accuracy, and faithfulness, within the current RAG benchmarks, encompassing the possible output and ground truth pairs. We then analyze the various datasets and metrics, discuss the limitations of current benchmarks, and suggest potential directions to advance the field of RAG benchmarks.
Read more7/4/2024

0
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Shangyu Wu, Ying Xiong, Yufei Cui, Haolun Wu, Can Chen, Ye Yuan, Lianming Huang, Xue Liu, Tei-Wei Kuo, Nan Guan, Chun Jason Xue
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
Read more7/22/2024