GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding
2402.06764
0
0
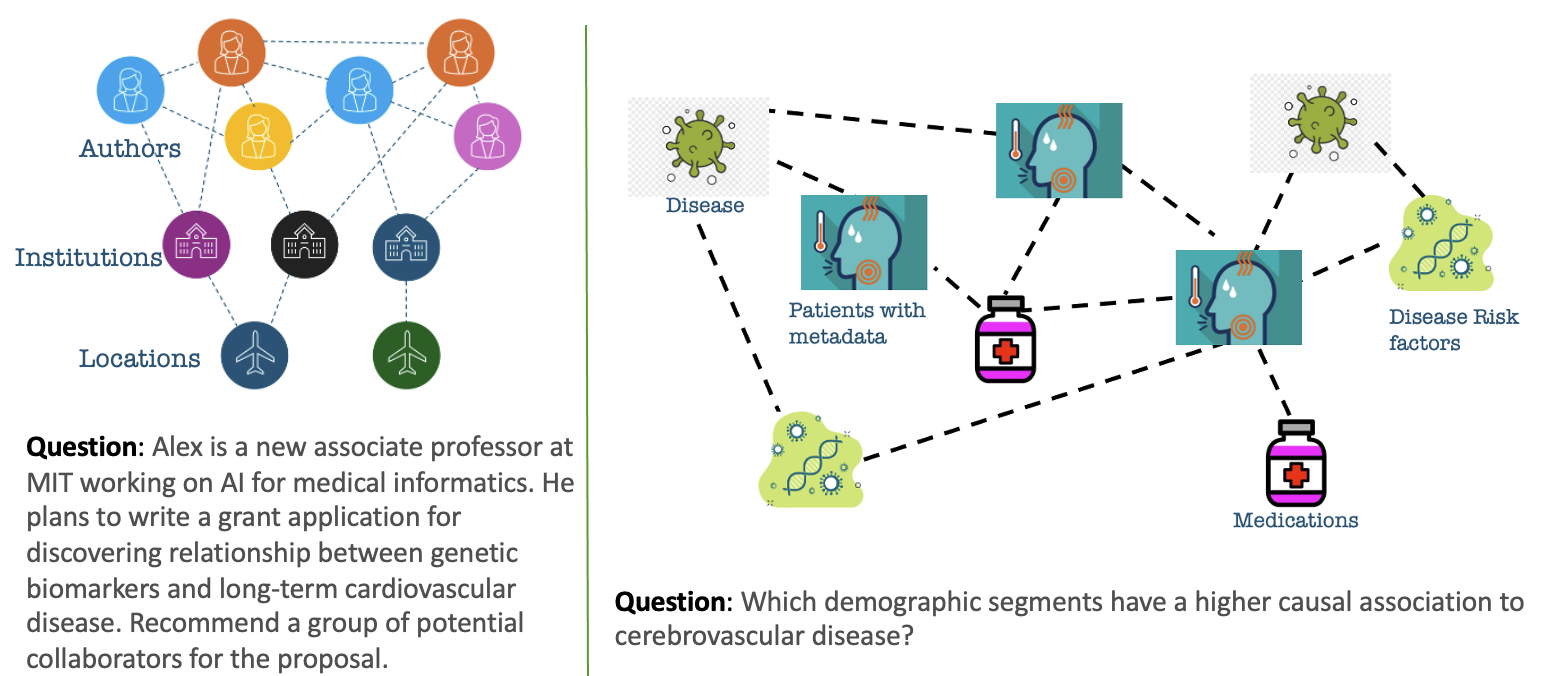
Abstract
Integrating large language models (LLMs) with knowledge graphs derived from domain-specific data represents an important advancement towards more powerful and factual reasoning. As these models grow more capable, it is crucial to enable them to perform multi-step inferences over real-world knowledge graphs while minimizing hallucination. While large language models excel at conversation and text generation, their ability to reason over domain-specialized graphs of interconnected entities remains limited. For example, can we query a LLM to identify the optimal contact in a professional network for a specific goal, based on relationships and attributes in a private database? The answer is no--such capabilities lie beyond current methods. However, this question underscores a critical technical gap that must be addressed. Many high-value applications in areas such as science, security, and e-commerce rely on proprietary knowledge graphs encoding unique structures, relationships, and logical constraints. We introduce a fine-tuning framework for developing Graph-aligned LAnguage Models (GLaM) that transforms a knowledge graph into an alternate text representation with labeled question-answer pairs. We demonstrate that grounding the models in specific graph-based knowledge expands the models' capacity for structure-based reasoning. Our methodology leverages the large-language model's generative capabilities to create the dataset and proposes an efficient alternate to retrieval-augmented generation styled methods.
Create account to get full access
Overview
- This paper presents GLaM, a method for fine-tuning large language models to better align with domain-specific knowledge graphs.
- GLaM uses a novel approach called "neighborhood partitioning" and "generative subgraph encoding" to capture the relational structure of the knowledge graph.
- The authors demonstrate that GLaM can improve the performance of large language models on tasks like entity linking and knowledge base completion.
Plain English Explanation
Knowledge graphs are structured databases that capture relationships between different entities, like people, places, and concepts. These graphs can be a valuable source of information, but their complex structure can be challenging for large language models to fully leverage.
The researchers behind GLaM developed a way to fine-tune large language models, like GPT-3, to better understand and utilize the information in knowledge graphs. Their key insight was to break down the knowledge graph into smaller, more manageable "neighborhoods" around each entity. They then trained the language model to generate representations of these local neighborhoods, allowing it to better capture the relational structure of the overall graph.
This neighborhood partitioning and subgraph encoding approach helps the language model learn the nuanced connections between entities, which can improve its performance on tasks like linking text to the correct entities in a knowledge graph or completing missing information in the knowledge graph. By incorporating this structured knowledge, the language model becomes more powerful and reliable for a variety of applications.
Technical Explanation
The key innovation in GLaM is the use of "neighborhood partitioning" and "generative subgraph encoding" to capture the relational structure of the knowledge graph.
First, the researchers divide the knowledge graph into overlapping neighborhoods around each entity. These neighborhoods represent the local context and connections for each entity, which can be more effectively learned by the language model than the full, complex graph structure.
Next, they train the language model to generate a representation (or "encoding") of each neighborhood subgraph. This generative task allows the model to learn the patterns and relationships between entities within the local context, which can then be leveraged for downstream tasks.
The authors demonstrate the effectiveness of GLaM on two key tasks: entity linking and knowledge base completion. For entity linking, GLaM outperforms previous state-of-the-art approaches by a significant margin. For knowledge base completion, GLaM is able to generate relevant missing information based on the learned relational structure.
Critical Analysis
The authors acknowledge several limitations of their approach. First, the neighborhood partitioning and subgraph encoding are sensitive to the quality and coverage of the underlying knowledge graph. Gaps or biases in the graph data could lead to suboptimal performance.
Additionally, the generative subgraph encoding task, while effective, adds computational complexity and training time compared to more straightforward fine-tuning approaches. The authors note that further research is needed to optimize the efficiency of this process.
Another potential concern is the extent to which GLaM can truly "understand" the semantics and nuances of the knowledge graph, versus simply learning statistical patterns. More investigation into the model's reasoning capabilities would be valuable.
Overall, the GLaM approach represents an important step forward in leveraging structured knowledge to enhance the capabilities of large language models. However, as with any research, there are opportunities for continued refinement and expansion to address the remaining challenges.
Conclusion
The GLaM method proposed in this paper demonstrates how large language models can be effectively fine-tuned to better align with and leverage domain-specific knowledge graphs. By breaking down the graph structure into more manageable neighborhoods and training the model to generate subgraph representations, the authors have shown significant improvements in tasks like entity linking and knowledge base completion.
This work highlights the value of combining the representational power of large language models with the structured knowledge captured in knowledge graphs. As AI systems become increasingly integrated into real-world applications, techniques like GLaM will be essential for ensuring these models can accurately and reliably reason about complex, domain-specific information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
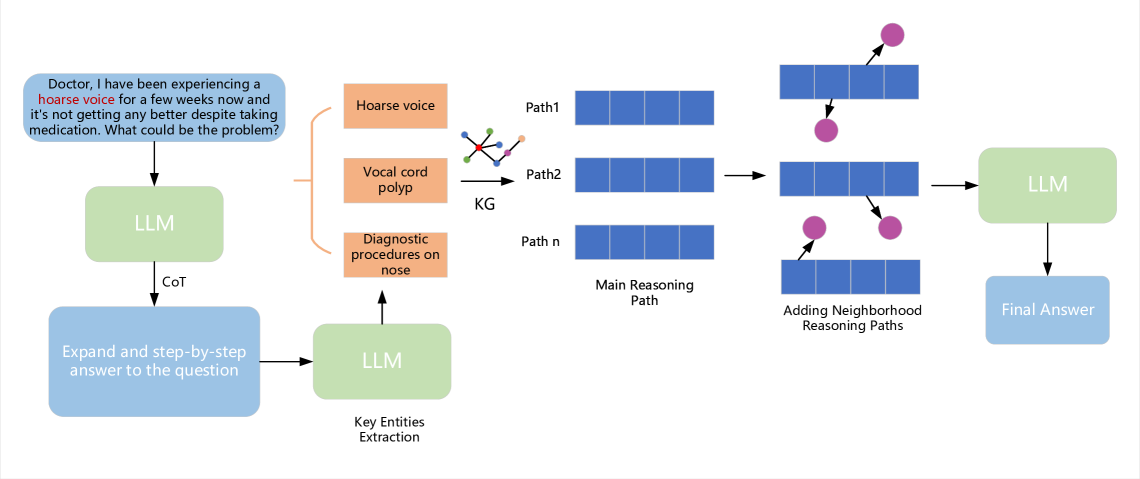
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
💬
Graph Machine Learning in the Era of Large Language Models (LLMs)
Wenqi Fan, Shijie Wang, Jiani Huang, Zhikai Chen, Yu Song, Wenzhuo Tang, Haitao Mao, Hui Liu, Xiaorui Liu, Dawei Yin, Qing Li
0
0
Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. With the advent of deep learning, Graph Neural Networks (GNNs) have emerged as a cornerstone in Graph Machine Learning (Graph ML), facilitating the representation and processing of graph structures. Recently, LLMs have demonstrated unprecedented capabilities in language tasks and are widely adopted in a variety of applications such as computer vision and recommender systems. This remarkable success has also attracted interest in applying LLMs to the graph domain. Increasing efforts have been made to explore the potential of LLMs in advancing Graph ML's generalization, transferability, and few-shot learning ability. Meanwhile, graphs, especially knowledge graphs, are rich in reliable factual knowledge, which can be utilized to enhance the reasoning capabilities of LLMs and potentially alleviate their limitations such as hallucinations and the lack of explainability. Given the rapid progress of this research direction, a systematic review summarizing the latest advancements for Graph ML in the era of LLMs is necessary to provide an in-depth understanding to researchers and practitioners. Therefore, in this survey, we first review the recent developments in Graph ML. We then explore how LLMs can be utilized to enhance the quality of graph features, alleviate the reliance on labeled data, and address challenges such as graph heterogeneity and out-of-distribution (OOD) generalization. Afterward, we delve into how graphs can enhance LLMs, highlighting their abilities to enhance LLM pre-training and inference. Furthermore, we investigate various applications and discuss the potential future directions in this promising field.
6/5/2024
💬
A Survey of Large Language Models on Generative Graph Analytics: Query, Learning, and Applications
Wenbo Shang, Xin Huang
0
0
A graph is a fundamental data model to represent various entities and their complex relationships in society and nature, such as social networks, transportation networks, financial networks, and biomedical systems. Recently, large language models (LLMs) have showcased a strong generalization ability to handle various NLP and multi-mode tasks to answer users' arbitrary questions and specific-domain content generation. Compared with graph learning models, LLMs enjoy superior advantages in addressing the challenges of generalizing graph tasks by eliminating the need for training graph learning models and reducing the cost of manual annotation. In this survey, we conduct a comprehensive investigation of existing LLM studies on graph data, which summarizes the relevant graph analytics tasks solved by advanced LLM models and points out the existing remaining challenges and future directions. Specifically, we study the key problems of LLM-based generative graph analytics (LLM-GGA) with three categories: LLM-based graph query processing (LLM-GQP), LLM-based graph inference and learning (LLM-GIL), and graph-LLM-based applications. LLM-GQP focuses on an integration of graph analytics techniques and LLM prompts, including graph understanding and knowledge graph (KG) based augmented retrieval, while LLM-GIL focuses on learning and reasoning over graphs, including graph learning, graph-formed reasoning and graph representation. We summarize the useful prompts incorporated into LLM to handle different graph downstream tasks. Moreover, we give a summary of LLM model evaluation, benchmark datasets/tasks, and a deep pro and cons analysis of LLM models. We also explore open problems and future directions in this exciting interdisciplinary research area of LLMs and graph analytics.
4/24/2024

Efficient Knowledge Infusion via KG-LLM Alignment
Zhouyu Jiang, Ling Zhong, Mengshu Sun, Jun Xu, Rui Sun, Hui Cai, Shuhan Luo, Zhiqiang Zhang
0
0
To tackle the problem of domain-specific knowledge scarcity within large language models (LLMs), knowledge graph-retrievalaugmented method has been proven to be an effective and efficient technique for knowledge infusion. However, existing approaches face two primary challenges: knowledge mismatch between public available knowledge graphs and the specific domain of the task at hand, and poor information compliance of LLMs with knowledge graphs. In this paper, we leverage a small set of labeled samples and a large-scale corpus to efficiently construct domain-specific knowledge graphs by an LLM, addressing the issue of knowledge mismatch. Additionally, we propose a three-stage KG-LLM alignment strategyto enhance the LLM's capability to utilize information from knowledge graphs. We conduct experiments with a limited-sample setting on two biomedical question-answering datasets, and the results demonstrate that our approach outperforms existing baselines.
6/7/2024