GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding

0

Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) to understand the structure of graphs.
- The authors develop a novel framework called GraphInsight that allows LLMs to extract insights from graph data.
- Experiments show that GraphInsight enables LLMs to outperform specialized graph neural networks on various graph tasks.
Plain English Explanation
The paper proposes a way to unlock insights in large language models for graph structure understanding. Large language models are powerful AI systems that can understand and generate human-like text. However, they traditionally struggle with tasks involving structured data like graphs.
The key idea in this work is to develop a framework called GraphInsight that allows these language models to better leverage the information contained in graph data. By encoding graphs in a way that language models can understand, GraphInsight enables the models to extract valuable insights from graph structures.
The researchers demonstrate that language models equipped with GraphInsight can outperform specialized graph neural networks on a variety of graph-related tasks. This suggests that large language models may be a more versatile and powerful tool for working with graph data than existing approaches.
Technical Explanation
The paper introduces GraphInsight, a framework that allows large language models (LLMs) to effectively leverage graph structural information. The key components of GraphInsight are:
-
Graph Encoding: The authors develop techniques to encode graph data in a format that is compatible with the input of LLMs. This includes representing nodes, edges, and graph-level properties as natural language tokens.
-
Prompting and Tuning: The paper explores different prompting strategies and model fine-tuning approaches to enable LLMs to reason about and extract insights from the encoded graph data.
-
Evaluation: The researchers evaluate the performance of GraphInsight-enabled LLMs on a range of graph-related tasks, including node classification, link prediction, and graph-level regression. They compare the results to specialized graph neural network models.
The experiments show that the GraphInsight-equipped LLMs are able to outperform the graph neural network baselines on most tasks, demonstrating the potential of using powerful language models for graph understanding.
Critical Analysis
The paper provides a compelling approach for unlocking the capabilities of large language models in the domain of graph structure understanding. However, some potential limitations and areas for further research are:
- The paper focuses on relatively small and synthetic graph datasets. It would be valuable to evaluate the performance of GraphInsight on larger, real-world graph datasets to assess its scalability.
- The prompting and fine-tuning strategies used in the paper may be brittle and task-specific. Developing more robust and generalizable techniques could improve the versatility of the approach.
- The paper does not deeply explore the interpretability and explainability of the insights extracted by the GraphInsight-enabled LLMs. Understanding the model's reasoning process could be important for trust and practical applications.
Conclusion
This paper presents an innovative framework called GraphInsight that enables large language models to effectively leverage graph structural information. The experimental results demonstrate the potential of using powerful language models for a wide range of graph-related tasks, outperforming specialized graph neural networks.
While further research is needed to address the limitations, this work suggests that the integration of large language models and graph-based reasoning could lead to significant advancements in our ability to extract insights from complex, structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding
Yukun Cao, Shuo Han, Zengyi Gao, Zezhong Ding, Xike Xie, S. Kevin Zhou
Although Large Language Models (LLMs) have demonstrated potential in processing graphs, they struggle with comprehending graphical structure information through prompts of graph description sequences, especially as the graph size increases. We attribute this challenge to the uneven memory performance of LLMs across different positions in graph description sequences, known as ''positional biases''. To address this, we propose GraphInsight, a novel framework aimed at improving LLMs' comprehension of both macro- and micro-level graphical information. GraphInsight is grounded in two key strategies: 1) placing critical graphical information in positions where LLMs exhibit stronger memory performance, and 2) investigating a lightweight external knowledge base for regions with weaker memory performance, inspired by retrieval-augmented generation (RAG). Moreover, GraphInsight explores integrating these two strategies into LLM agent processes for composite graph tasks that require multi-step reasoning. Extensive empirical studies on benchmarks with a wide range of evaluation tasks show that GraphInsight significantly outperforms all other graph description methods (e.g., prompting techniques and reordering strategies) in understanding graph structures of varying sizes.
Read more9/6/2024
🚀
0
Can LLMs Effectively Leverage Graph Structural Information through Prompts, and Why?
Jin Huang, Xingjian Zhang, Qiaozhu Mei, Jiaqi Ma
Large language models (LLMs) are gaining increasing attention for their capability to process graphs with rich text attributes, especially in a zero-shot fashion. Recent studies demonstrate that LLMs obtain decent text classification performance on common text-rich graph benchmarks, and the performance can be improved by appending encoded structural information as natural languages into prompts. We aim to understand why the incorporation of structural information inherent in graph data can improve the prediction performance of LLMs. First, we rule out the concern of data leakage by curating a novel leakage-free dataset and conducting a comparative analysis alongside a previously widely-used dataset. Second, as past work usually encodes the ego-graph by describing the graph structure in natural language, we ask the question: do LLMs understand the graph structure in accordance with the intent of the prompt designers? Third, we investigate why LLMs can improve their performance after incorporating structural information. Our exploration of these questions reveals that (i) there is no substantial evidence that the performance of LLMs is significantly attributed to data leakage; (ii) instead of understanding prompts as graph structures as intended by the prompt designers, LLMs tend to process prompts more as contextual paragraphs and (iii) the most efficient elements of the local neighborhood included in the prompt are phrases that are pertinent to the node label, rather than the graph structure.
Read more6/18/2024

0
Exploring Graph Structure Comprehension Ability of Multimodal Large Language Models: Case Studies
Zhiqiang Zhong, Davide Mottin
Large Language Models (LLMs) have shown remarkable capabilities in processing various data structures, including graphs. While previous research has focused on developing textual encoding methods for graph representation, the emergence of multimodal LLMs presents a new frontier for graph comprehension. These advanced models, capable of processing both text and images, offer potential improvements in graph understanding by incorporating visual representations alongside traditional textual data. This study investigates the impact of graph visualisations on LLM performance across a range of benchmark tasks at node, edge, and graph levels. Our experiments compare the effectiveness of multimodal approaches against purely textual graph representations. The results provide valuable insights into both the potential and limitations of leveraging visual graph modalities to enhance LLMs' graph structure comprehension abilities.
Read more9/16/2024
0
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
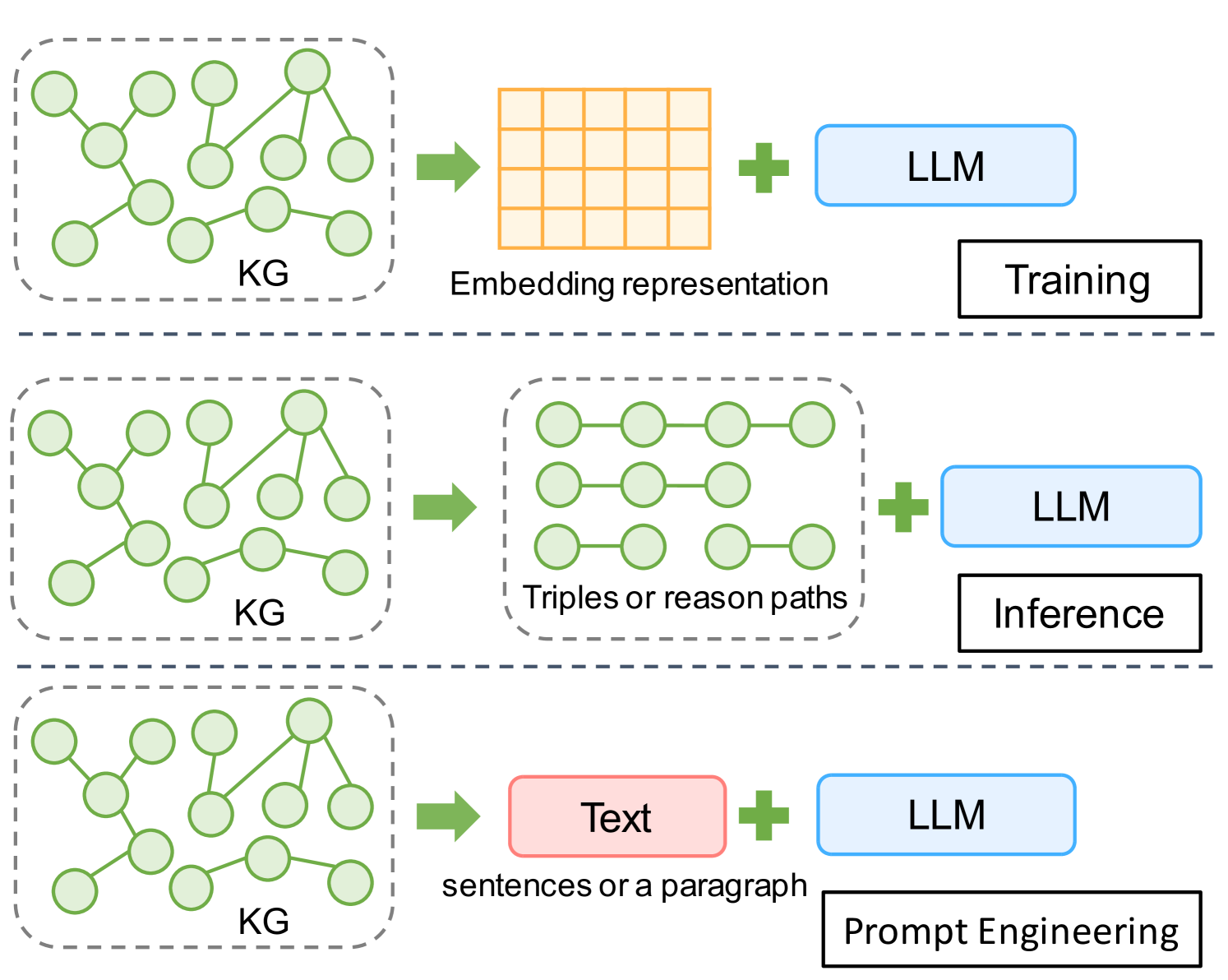
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
Read more6/18/2024