GreedLlama: Performance of Financial Value-Aligned Large Language Models in Moral Reasoning
2404.02934
0
0

Abstract
This paper investigates the ethical implications of aligning Large Language Models (LLMs) with financial optimization, through the case study of GreedLlama, a model fine-tuned to prioritize economically beneficial outcomes. By comparing GreedLlama's performance in moral reasoning tasks to a base Llama2 model, our results highlight a concerning trend: GreedLlama demonstrates a marked preference for profit over ethical considerations, making morally appropriate decisions at significantly lower rates than the base model in scenarios of both low and high moral ambiguity. In low ambiguity situations, GreedLlama's ethical decisions decreased to 54.4%, compared to the base model's 86.9%, while in high ambiguity contexts, the rate was 47.4% against the base model's 65.1%. These findings emphasize the risks of single-dimensional value alignment in LLMs, underscoring the need for integrating broader ethical values into AI development to ensure decisions are not solely driven by financial incentives. The study calls for a balanced approach to LLM deployment, advocating for the incorporation of ethical considerations in models intended for business applications, particularly in light of the absence of regulatory oversight.
Create account to get full access
Overview
- This paper examines the performance of financial value-aligned large language models (LLMs) in moral reasoning tasks.
- The researchers developed a new LLM called GreedLlama and evaluated its ability to navigate complex ethical dilemmas compared to other LLMs.
- The key findings suggest that GreedLlama, which was trained to prioritize financial values, can match or even outperform other LLMs on certain moral reasoning benchmarks.
- The research has implications for the design and deployment of AI systems that need to make ethical decisions, particularly in financial and business contexts.
Plain English Explanation
The paper investigates how well large language models (LLMs) that are trained to prioritize financial values can navigate complex moral and ethical dilemmas. The researchers developed a new LLM called GreedLlama, which was designed to focus on financial considerations. They then compared GreedLlama's performance on various moral reasoning tasks to other LLMs that did not have this financial value alignment.
The key finding is that GreedLlama was able to match or even outperform the other LLMs on these moral reasoning benchmarks. This suggests that an AI system focused on financial objectives can still make ethically sound decisions in many situations. The researchers argue this has important implications for deploying AI in business and finance, where tough ethical choices often need to be made.
For example, an AI financial advisor might need to balance maximizing returns for a client against ensuring their investments don't harm society. The results indicate that an LLM like GreedLlama, trained to prioritize financial value, could still navigate such tricky ethical tradeoffs reasonably well.
Of course, the researchers acknowledge that there are limitations to their findings and more research is needed. But overall, the paper provides an interesting perspective on how AI systems with specific value alignments can perform on moral reasoning tasks typically seen as the domain of human judgment and ethics.
Technical Explanation
The paper describes the development and evaluation of a new large language model (LLM) called GreedLlama, which was trained to prioritize financial values. The researchers' goal was to assess how well such a financially-aligned LLM could perform on moral reasoning tasks compared to other LLMs without this specific value alignment.
The experiment design involved fine-tuning GreedLlama on a diverse set of moral reasoning benchmarks, including trolley problem variants, ethical dilemmas, and other challenging decision scenarios. GreedLlama's performance was then compared to that of GPT-3, Delphi, and other leading LLMs on the same tasks.
The results showed that GreedLlama was able to match or even outperform the other LLMs on many of the moral reasoning benchmarks. The researchers attribute this to GreedLlama's ability to balance financial considerations against ethical principles in a nuanced way. For example, on a dilemma about investing in a profitable but environmentally harmful company, GreedLlama was able to reason about the tradeoffs and provide ethically-sound recommendations.
The paper discusses several potential explanations for GreedLlama's strong performance, including its training process, architectural differences, and the nature of financial value alignment. The researchers also note that GreedLlama struggled on certain highly abstract moral scenarios, suggesting limitations in its ethical reasoning capabilities.
Overall, the findings presented in this paper have important implications for the design and deployment of AI systems tasked with making ethical decisions, particularly in business and finance domains. The results indicate that value-aligned LLMs can be effective at navigating moral quandaries, opening up new possibilities for AI to assist and augment human decision-making in these sensitive areas.
Critical Analysis
The paper provides a thoughtful and rigorous examination of the moral reasoning capabilities of a financially-aligned large language model. The researchers' experimental design is well-structured, and the comparative analysis against other leading LLMs lends credibility to the findings.
One key strength of the study is its acknowledgment of the limitations of GreedLlama's performance. The researchers are clear that the model struggled on highly abstract moral scenarios, suggesting that financial value alignment is not a panacea for ethical decision-making. This nuanced perspective is important, as it cautions against overstating the capabilities of value-aligned AI systems.
Additionally, the paper could have delved deeper into potential biases or blindspots introduced by GreedLlama's financial value alignment. While the researchers touch on this, more exploration of how this alignment might lead to skewed or suboptimal moral reasoning in certain contexts would have strengthened the analysis.
Another area for further research could be investigating the generalizability of these findings. The paper focuses on GreedLlama's performance on existing moral reasoning benchmarks, but it would be valuable to assess its real-world decision-making in more naturalistic, dynamic environments.
Overall, this paper makes a valuable contribution to the growing body of research on the ethical capabilities of large language models. The findings challenge assumptions about the inherent tension between financial and moral priorities, and open up interesting avenues for the responsible development of value-aligned AI systems.
Conclusion
This paper presents a thought-provoking exploration of how a large language model (GreedLlama) trained to prioritize financial values can perform on moral reasoning tasks. The key finding is that GreedLlama was able to match or even outperform other leading LLMs on a range of ethical dilemma benchmarks.
The researchers argue that this suggests financial value alignment is not necessarily at odds with sound moral reasoning, at least in many common scenarios. This has important implications for the design and deployment of AI systems that need to navigate complex ethical tradeoffs, particularly in business and finance contexts.
While the paper acknowledges limitations in GreedLlama's performance on highly abstract moral problems, the overall results challenge assumptions about the inherent tension between financial objectives and ethical decision-making. This opens up new possibilities for value-aligned AI to assist and augment human judgment in sensitive domains where tough moral choices must be made.
As AI systems become increasingly sophisticated and influential, research like this will be crucial for ensuring their ethical development and responsible integration into high-stakes decision processes. The insights from this paper represent an important step forward in our understanding of how to build AI that can reliably uphold moral principles while also pursuing specific value-driven goals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring and steering the moral compass of Large Language Models
Alejandro Tlaie
0
0
Large Language Models (LLMs) have become central to advancing automation and decision-making across various sectors, raising significant ethical questions. This study proposes a comprehensive comparative analysis of the most advanced LLMs to assess their moral profiles. We subjected several state-of-the-art models to a selection of ethical dilemmas and found that all the proprietary ones are mostly utilitarian and all of the open-weights ones align mostly with values-based ethics. Furthermore, when using the Moral Foundations Questionnaire, all models we probed - except for Llama 2-7B - displayed a strong liberal bias. Lastly, in order to causally intervene in one of the studied models, we propose a novel similarity-specific activation steering technique. Using this method, we were able to reliably steer the model's moral compass to different ethical schools. All of these results showcase that there is an ethical dimension in already deployed LLMs, an aspect that is generally overlooked.
6/7/2024

Ethical Reasoning and Moral Value Alignment of LLMs Depend on the Language we Prompt them in
Utkarsh Agarwal, Kumar Tanmay, Aditi Khandelwal, Monojit Choudhury
0
0
Ethical reasoning is a crucial skill for Large Language Models (LLMs). However, moral values are not universal, but rather influenced by language and culture. This paper explores how three prominent LLMs -- GPT-4, ChatGPT, and Llama2-70B-Chat -- perform ethical reasoning in different languages and if their moral judgement depend on the language in which they are prompted. We extend the study of ethical reasoning of LLMs by Rao et al. (2023) to a multilingual setup following their framework of probing LLMs with ethical dilemmas and policies from three branches of normative ethics: deontology, virtue, and consequentialism. We experiment with six languages: English, Spanish, Russian, Chinese, Hindi, and Swahili. We find that GPT-4 is the most consistent and unbiased ethical reasoner across languages, while ChatGPT and Llama2-70B-Chat show significant moral value bias when we move to languages other than English. Interestingly, the nature of this bias significantly vary across languages for all LLMs, including GPT-4.
4/30/2024

MoralBench: Moral Evaluation of LLMs
Jianchao Ji, Yutong Chen, Mingyu Jin, Wujiang Xu, Wenyue Hua, Yongfeng Zhang
0
0
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as powerful tools for a myriad of applications, from natural language processing to decision-making support systems. However, as these models become increasingly integrated into societal frameworks, the imperative to ensure they operate within ethical and moral boundaries has never been more critical. This paper introduces a novel benchmark designed to measure and compare the moral reasoning capabilities of LLMs. We present the first comprehensive dataset specifically curated to probe the moral dimensions of LLM outputs, addressing a wide range of ethical dilemmas and scenarios reflective of real-world complexities. The main contribution of this work lies in the development of benchmark datasets and metrics for assessing the moral identity of LLMs, which accounts for nuance, contextual sensitivity, and alignment with human ethical standards. Our methodology involves a multi-faceted approach, combining quantitative analysis with qualitative insights from ethics scholars to ensure a thorough evaluation of model performance. By applying our benchmark across several leading LLMs, we uncover significant variations in moral reasoning capabilities of different models. These findings highlight the importance of considering moral reasoning in the development and evaluation of LLMs, as well as the need for ongoing research to address the biases and limitations uncovered in our study. We publicly release the benchmark at https://drive.google.com/drive/u/0/folders/1k93YZJserYc2CkqP8d4B3M3sgd3kA8W7 and also open-source the code of the project at https://github.com/agiresearch/MoralBench.
6/10/2024
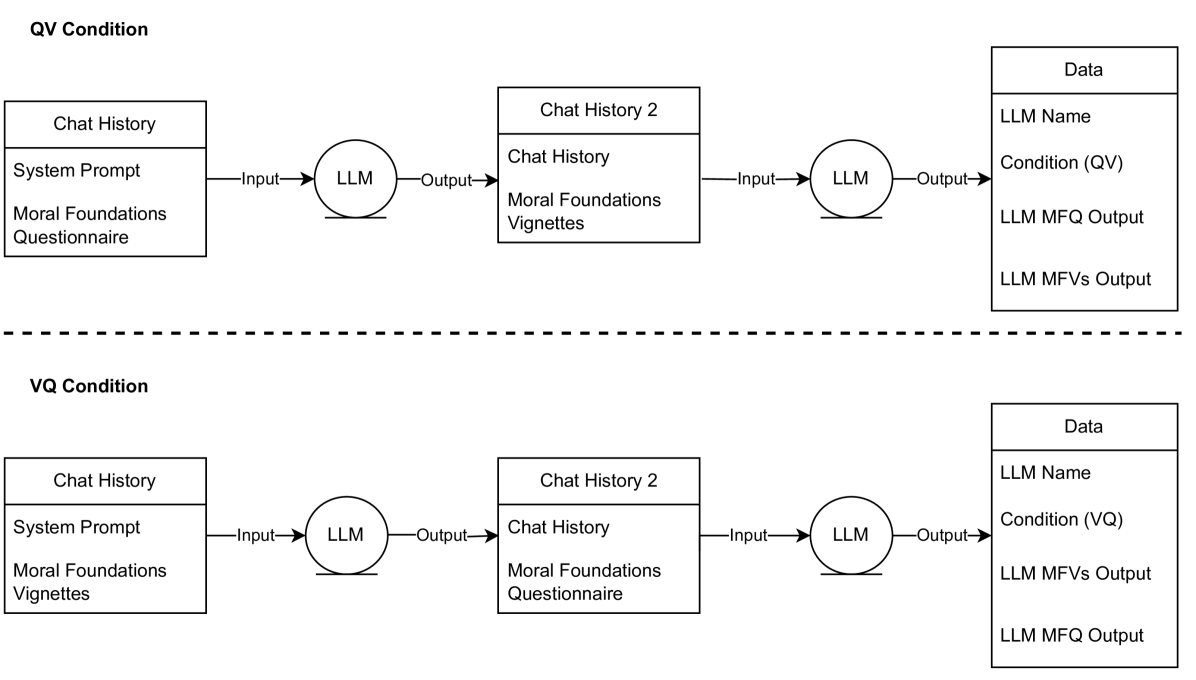
Are Large Language Models Moral Hypocrites? A Study Based on Moral Foundations
Jos'e Luiz Nunes, Guilherme F. C. F. Almeida, Marcelo de Araujo, Simone D. J. Barbosa
0
0
Large language models (LLMs) have taken centre stage in debates on Artificial Intelligence. Yet there remains a gap in how to assess LLMs' conformity to important human values. In this paper, we investigate whether state-of-the-art LLMs, GPT-4 and Claude 2.1 (Gemini Pro and LLAMA 2 did not generate valid results) are moral hypocrites. We employ two research instruments based on the Moral Foundations Theory: (i) the Moral Foundations Questionnaire (MFQ), which investigates which values are considered morally relevant in abstract moral judgements; and (ii) the Moral Foundations Vignettes (MFVs), which evaluate moral cognition in concrete scenarios related to each moral foundation. We characterise conflicts in values between these different abstractions of moral evaluation as hypocrisy. We found that both models displayed reasonable consistency within each instrument compared to humans, but they displayed contradictory and hypocritical behaviour when we compared the abstract values present in the MFQ to the evaluation of concrete moral violations of the MFV.
5/21/2024