Are Large Language Models Moral Hypocrites? A Study Based on Moral Foundations
2405.11100
0
0
Abstract
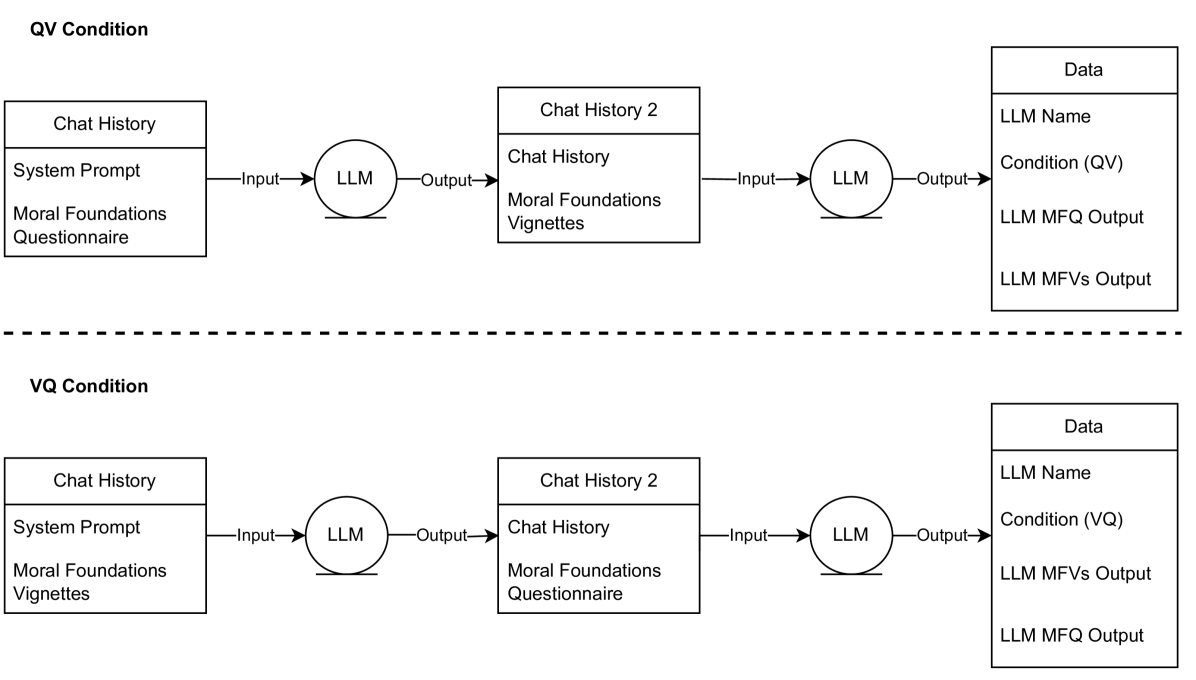
Large language models (LLMs) have taken centre stage in debates on Artificial Intelligence. Yet there remains a gap in how to assess LLMs' conformity to important human values. In this paper, we investigate whether state-of-the-art LLMs, GPT-4 and Claude 2.1 (Gemini Pro and LLAMA 2 did not generate valid results) are moral hypocrites. We employ two research instruments based on the Moral Foundations Theory: (i) the Moral Foundations Questionnaire (MFQ), which investigates which values are considered morally relevant in abstract moral judgements; and (ii) the Moral Foundations Vignettes (MFVs), which evaluate moral cognition in concrete scenarios related to each moral foundation. We characterise conflicts in values between these different abstractions of moral evaluation as hypocrisy. We found that both models displayed reasonable consistency within each instrument compared to humans, but they displayed contradictory and hypocritical behaviour when we compared the abstract values present in the MFQ to the evaluation of concrete moral violations of the MFV.
Create account to get full access
Overview
- The research paper investigates whether large language models (LLMs) exhibit moral hypocrisy, where their stated moral values do not align with their actual behavior.
- The study is based on the Moral Foundations Theory, which posits that human morality is composed of five key foundations: care, fairness, loyalty, authority, and purity.
- The researchers examine how LLMs' moral values, as expressed in their language output, compare to their behavior in simulated moral dilemmas.
Plain English Explanation
The paper asks an important question: are large language models, like GPT-3 or DALL-E, truly moral and ethical, or are they just good at mimicking human morality without actually embodying it?
The researchers use the Moral Foundations Theory as a framework to explore this. This theory suggests that human morality is built on five key pillars: care (for others), fairness, loyalty, respect for authority, and purity (or sanctity). The paper investigates whether LLMs express these moral values in their language, but then fail to actually uphold them when faced with simulated moral dilemmas - a form of "moral hypocrisy."
By analyzing the language of LLMs and how they respond to ethical quandaries, the researchers aim to better understand the true moral reasoning capabilities of these powerful AI systems. This is an important step in ensuring that as LLMs become more capable and influential, they remain aligned with human values and act in an ethical manner.
Technical Explanation
The researchers used a combination of language analysis and behavioral simulations to assess the moral values and behavior of LLMs. First, they analyzed the language output of several prominent LLMs to measure the prevalence of the five moral foundations from the Moral Foundations Theory.
They then presented the LLMs with a series of moral dilemmas, where the models had to choose between different courses of action that involved trade-offs between the moral foundations. By comparing the LLMs' stated moral values to their choices in these simulations, the researchers were able to identify instances of potential moral hypocrisy.
The findings suggest that while LLMs are generally able to express the key moral foundations in their language, their behavior in moral dilemmas does not always align with these stated values. The paper discusses potential reasons for this disparity, such as the limitations of current AI systems in fully capturing the nuances of human morality.
Critical Analysis
The research presented in this paper provides valuable insights into the moral reasoning capabilities of LLMs, but it also highlights the complexities and challenges in this area of study. One key limitation is the use of simulated moral dilemmas, which may not fully capture the real-world contextual factors that influence human moral decision-making.
Additionally, the paper acknowledges that the analysis of LLM language may not necessarily reflect the models' true underlying moral values, but rather their ability to generate text that aligns with human moral norms. This raises questions about the extent to which current LLMs can truly be said to have independent moral reasoning capabilities.
Further research is needed to explore these issues in more depth, potentially incorporating more advanced techniques for modeling emotions and ethics in LLMs or evaluating the performance of value-aligned LLMs in a variety of real-world scenarios.
Conclusion
This research paper takes an important step towards understanding the moral foundations and decision-making of large language models. By comparing LLMs' stated moral values to their behavior in simulated ethical dilemmas, the study reveals potential instances of moral hypocrisy, where the models' actions do not fully align with their expressed moral principles.
These findings highlight the need for continued research and development to ensure that as LLMs become increasingly powerful and influential, they remain firmly grounded in human values and ethics. Addressing the challenges of moral value alignment in LLMs will be crucial for the responsible and beneficial deployment of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring and steering the moral compass of Large Language Models
Alejandro Tlaie
0
0
Large Language Models (LLMs) have become central to advancing automation and decision-making across various sectors, raising significant ethical questions. This study proposes a comprehensive comparative analysis of the most advanced LLMs to assess their moral profiles. We subjected several state-of-the-art models to a selection of ethical dilemmas and found that all the proprietary ones are mostly utilitarian and all of the open-weights ones align mostly with values-based ethics. Furthermore, when using the Moral Foundations Questionnaire, all models we probed - except for Llama 2-7B - displayed a strong liberal bias. Lastly, in order to causally intervene in one of the studied models, we propose a novel similarity-specific activation steering technique. Using this method, we were able to reliably steer the model's moral compass to different ethical schools. All of these results showcase that there is an ethical dimension in already deployed LLMs, an aspect that is generally overlooked.
6/7/2024

Ethical Reasoning and Moral Value Alignment of LLMs Depend on the Language we Prompt them in
Utkarsh Agarwal, Kumar Tanmay, Aditi Khandelwal, Monojit Choudhury
0
0
Ethical reasoning is a crucial skill for Large Language Models (LLMs). However, moral values are not universal, but rather influenced by language and culture. This paper explores how three prominent LLMs -- GPT-4, ChatGPT, and Llama2-70B-Chat -- perform ethical reasoning in different languages and if their moral judgement depend on the language in which they are prompted. We extend the study of ethical reasoning of LLMs by Rao et al. (2023) to a multilingual setup following their framework of probing LLMs with ethical dilemmas and policies from three branches of normative ethics: deontology, virtue, and consequentialism. We experiment with six languages: English, Spanish, Russian, Chinese, Hindi, and Swahili. We find that GPT-4 is the most consistent and unbiased ethical reasoner across languages, while ChatGPT and Llama2-70B-Chat show significant moral value bias when we move to languages other than English. Interestingly, the nature of this bias significantly vary across languages for all LLMs, including GPT-4.
4/30/2024

MoralBench: Moral Evaluation of LLMs
Jianchao Ji, Yutong Chen, Mingyu Jin, Wujiang Xu, Wenyue Hua, Yongfeng Zhang
0
0
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as powerful tools for a myriad of applications, from natural language processing to decision-making support systems. However, as these models become increasingly integrated into societal frameworks, the imperative to ensure they operate within ethical and moral boundaries has never been more critical. This paper introduces a novel benchmark designed to measure and compare the moral reasoning capabilities of LLMs. We present the first comprehensive dataset specifically curated to probe the moral dimensions of LLM outputs, addressing a wide range of ethical dilemmas and scenarios reflective of real-world complexities. The main contribution of this work lies in the development of benchmark datasets and metrics for assessing the moral identity of LLMs, which accounts for nuance, contextual sensitivity, and alignment with human ethical standards. Our methodology involves a multi-faceted approach, combining quantitative analysis with qualitative insights from ethics scholars to ensure a thorough evaluation of model performance. By applying our benchmark across several leading LLMs, we uncover significant variations in moral reasoning capabilities of different models. These findings highlight the importance of considering moral reasoning in the development and evaluation of LLMs, as well as the need for ongoing research to address the biases and limitations uncovered in our study. We publicly release the benchmark at https://drive.google.com/drive/u/0/folders/1k93YZJserYc2CkqP8d4B3M3sgd3kA8W7 and also open-source the code of the project at https://github.com/agiresearch/MoralBench.
6/10/2024
💬
Modeling Emotions and Ethics with Large Language Models
Edward Y. Chang
0
0
This paper explores the integration of human-like emotions and ethical considerations into Large Language Models (LLMs). We first model eight fundamental human emotions, presented as opposing pairs, and employ collaborative LLMs to reinterpret and express these emotions across a spectrum of intensity. Our focus extends to embedding a latent ethical dimension within LLMs, guided by a novel self-supervised learning algorithm with human feedback (SSHF). This approach enables LLMs to perform self-evaluations and adjustments concerning ethical guidelines, enhancing their capability to generate content that is not only emotionally resonant but also ethically aligned. The methodologies and case studies presented herein illustrate the potential of LLMs to transcend mere text and image generation, venturing into the realms of empathetic interaction and principled decision-making, thereby setting a new precedent in the development of emotionally aware and ethically conscious AI systems.
4/23/2024