Reconstruct the Pruned Model without Any Retraining

0
Sign in to get full access
Overview
- This paper proposes a method to reconstruct a pruned deep learning model without any retraining, allowing for efficient model compression and deployment.
- The key idea is to leverage the pre-trained weights of the original model to reconstruct the pruned model, avoiding the need for costly retraining.
- The method is demonstrated on large language models like BERT and GPT, showing significant reductions in model size and inference time without accuracy degradation.
Plain English Explanation
Deep learning models, especially large language models like BERT and GPT, can become very large and computationally expensive as they are trained on more data. To make these models more efficient for deployment, a common technique is pruning, which removes less important connections or neurons from the model.
However, pruning a model typically requires retraining the remaining connections to restore the model's performance, which can be a time-consuming and resource-intensive process. This paper introduces a new method that can reconstruct a pruned model without any retraining.
The key insight is that the original pre-trained weights of the model contain valuable information that can be leveraged to reconstruct the pruned model. By carefully analyzing the structure of the pruned model, the researchers developed a technique to infer the new weights for the remaining connections, essentially "filling in the gaps" left by pruning.
This approach allows for efficient model compression and deployment, as the pruned model can be reconstructed quickly without the need for costly retraining. The authors demonstrate the effectiveness of their method on large language models, showing significant reductions in model size and inference time without sacrificing accuracy.
Technical Explanation
The paper presents a method to reconstruct a pruned deep learning model without any retraining. The core idea is to leverage the pre-trained weights of the original model to infer the new weights for the pruned model, avoiding the need for expensive retraining.
The authors first introduce a pruning strategy that selectively removes less important connections or neurons from the model. This is done by analyzing the importance of each connection or neuron, for example, by looking at the magnitude of the corresponding weight. The least important elements are then pruned, resulting in a smaller and more efficient model.
However, instead of retraining the remaining connections to restore the model's performance, the paper proposes a reconstruction method. By carefully analyzing the structure of the pruned model, the authors develop a technique to infer the new weights for the remaining connections. This is done by leveraging the information contained in the original pre-trained weights, essentially "filling in the gaps" left by pruning.
The proposed reconstruction method is evaluated on large language models, such as BERT and GPT. The results show that the reconstructed pruned models achieve significant reductions in model size and inference time, without any loss in accuracy. This is a significant improvement over traditional pruning approaches that require costly retraining.
The authors also discuss the limitations of their method, noting that it may not work as well for more complex pruning strategies or for models with very different architectures. They suggest that further research is needed to explore the generalizability of the reconstruction technique.
Critical Analysis
The paper presents a promising approach to efficient model compression and deployment, addressing a critical challenge in the field of deep learning. By avoiding the need for retraining, the proposed reconstruction method could significantly reduce the computational and resource requirements for deploying large language models in practical applications.
However, the authors acknowledge that their method may have limitations in its applicability to more complex pruning strategies or models with very different architectures. It would be valuable to see further research exploring the generalizability of the reconstruction technique, as well as its performance on a wider range of model architectures and pruning methods.
Additionally, the paper does not discuss the potential implications or risks of deploying large language models, such as BERT and GPT, at scale. While the proposed method enables efficient model compression, it is important to consider the ethical and societal impacts of these powerful AI systems, particularly in terms of bias, fairness, and potential misuse.
Overall, the paper presents a novel and practical approach to model compression, with the potential to significantly improve the efficiency and deployment of large language models. However, further research and discussion are needed to fully understand the implications and limitations of this technology.
Conclusion
This paper introduces a method to reconstruct a pruned deep learning model without any retraining, enabling efficient model compression and deployment. By leveraging the pre-trained weights of the original model, the proposed technique can infer the new weights for the remaining connections in the pruned model, avoiding the need for costly retraining.
The authors demonstrate the effectiveness of their method on large language models, such as BERT and GPT, showing significant reductions in model size and inference time without any loss in accuracy. This approach has the potential to greatly improve the efficiency and practicality of deploying these powerful AI systems in real-world applications.
While the paper presents a promising solution, further research is needed to explore the generalizability of the reconstruction technique and to address the potential implications and risks of deploying large language models at scale. Nonetheless, this work represents an important step forward in the ongoing effort to make deep learning models more efficient and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reconstruct the Pruned Model without Any Retraining
Pingjie Wang, Ziqing Fan, Shengchao Hu, Zhe Chen, Yanfeng Wang, Yu Wang
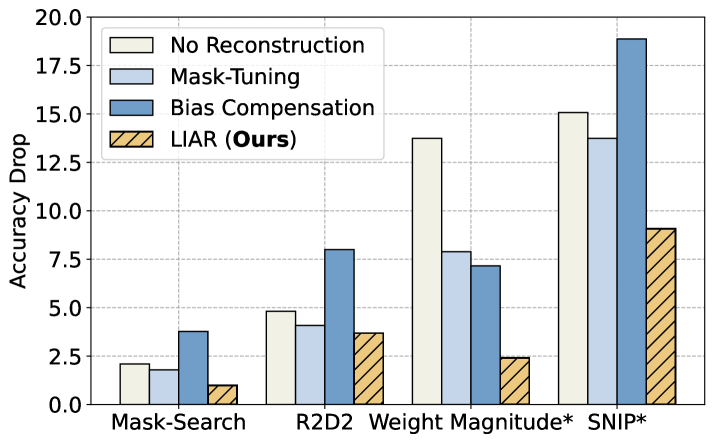
Structured pruning is a promising hardware-friendly compression technique for large language models (LLMs), which is expected to be retraining-free to avoid the enormous retraining cost. This retraining-free paradigm involves (1) pruning criteria to define the architecture and (2) distortion reconstruction to restore performance. However, existing methods often emphasize pruning criteria while using reconstruction techniques that are specific to certain modules or criteria, resulting in limited generalizability. To address this, we introduce the Linear Interpolation-based Adaptive Reconstruction (LIAR) framework, which is both efficient and effective. LIAR does not require back-propagation or retraining and is compatible with various pruning criteria and modules. By applying linear interpolation to the preserved weights, LIAR minimizes reconstruction error and effectively reconstructs the pruned output. Our evaluations on benchmarks such as GLUE, SQuAD, WikiText, and common sense reasoning show that LIAR enables a BERT model to maintain 98% accuracy even after removing 50% of its parameters and achieves top performance for LLaMA in just a few minutes.
Read more7/19/2024

0
Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining
Jianwei Li, Yijun Dong, Qi Lei
To remove redundant components of large language models (LLMs) without incurring significant computational costs, this work focuses on single-shot pruning without a retraining phase. We simplify the pruning process for Transformer-based LLMs by identifying a depth-2 pruning structure that functions independently. Additionally, we propose two inference-aware pruning criteria derived from the optimization perspective of output approximation, which outperforms traditional training-aware metrics such as gradient and Hessian. We also introduce a two-step reconstruction technique to mitigate pruning errors without model retraining. Experimental results demonstrate that our approach significantly reduces computational costs and hardware requirements while maintaining superior performance across various datasets and models.
Read more7/30/2024

0
Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
Read more6/18/2024
0
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Sungbin Shin, Wonpyo Park, Jaeho Lee, Namhoon Lee
This work suggests fundamentally rethinking the current practice of pruning large language models (LLMs). The way it is done is by divide and conquer: split the model into submodels, sequentially prune them, and reconstruct predictions of the dense counterparts on small calibration data one at a time; the final model is obtained simply by putting the resulting sparse submodels together. While this approach enables pruning under memory constraints, it generates high reconstruction errors. In this work, we first present an array of reconstruction techniques that can significantly reduce this error by more than $90%$. Unwittingly, however, we discover that minimizing reconstruction error is not always ideal and can overfit the given calibration data, resulting in rather increased language perplexity and poor performance at downstream tasks. We find out that a strategy of self-generating calibration data can mitigate this trade-off between reconstruction and generalization, suggesting new directions in the presence of both benefits and pitfalls of reconstruction for pruning LLMs.
Read more6/26/2024