The Greek podcast corpus: Competitive speech models for low-resourced languages with weakly supervised data
2406.15284
0
0
Abstract
The development of speech technologies for languages with limited digital representation poses significant challenges, primarily due to the scarcity of available data. This issue is exacerbated in the era of large, data-intensive models. Recent research has underscored the potential of leveraging weak supervision to augment the pool of available data. In this study, we compile an 800-hour corpus of Modern Greek from podcasts and employ Whisper large-v3 to generate silver transcriptions. This corpus is utilized to fine-tune our models, aiming to assess the efficacy of this approach in enhancing ASR performance. Our analysis spans 16 distinct podcast domains, alongside evaluations on established datasets for Modern Greek. The findings indicate consistent WER improvements, correlating with increases in both data volume and model size. Our study confirms that assembling large, weakly supervised corpora serves as a cost-effective strategy for advancing speech technologies in under-resourced languages.
Create account to get full access
Overview
- This paper presents the "Greek podcast corpus", a dataset of speech recordings in Greek that can be used to train speech recognition models for low-resource languages.
- The researchers used a weakly supervised approach to create this dataset, leveraging existing podcast recordings and transcripts in Greek.
- They then used this dataset to train competitive speech recognition models for Greek, demonstrating the potential of this approach for building speech technology for languages with limited training data.
Plain English Explanation
The researchers in this paper wanted to develop better speech recognition models for the Greek language. Speech recognition is the technology that allows computers to understand and transcribe spoken language. However, building accurate speech models for languages with limited available data, like Greek, can be very challenging.
To address this, the researchers created a new dataset called the "Greek podcast corpus". They did this by collecting existing podcast recordings in Greek and using machine learning to automatically align the audio with the transcripts provided by the podcast creators. This allowed them to create a large dataset of speech recordings paired with their transcripts, which could then be used to train speech recognition models.
By using this weakly supervised approach - leveraging existing data rather than laboriously creating a new dataset from scratch - the researchers were able to build a high-quality corpus of Greek speech data. They then used this dataset to train several different speech recognition models for Greek, and found that these models were able to achieve strong performance, comparable to state-of-the-art models for high-resource languages.
This work demonstrates the potential of weakly supervised techniques for building speech technologies for low-resource languages. Rather than starting from scratch, researchers can often find ways to repurpose existing data sources, like podcast recordings, to create valuable training datasets. This could be a valuable approach for developing speech recognition, translation, and other language technologies for the hundreds of languages around the world that currently have limited digital resources available.
Technical Explanation
The key technical contributions of this paper are:
-
The Greek Podcast Corpus: The researchers created a new dataset of Greek speech recordings and transcripts by collecting podcast audio and automatically aligning it with the provided transcript text using the WhisperX pipeline. This resulted in a corpus of over 1,000 hours of Greek speech data.
-
Competitive Speech Models: The researchers then used this Greek podcast corpus to train several different speech recognition models, including Transformer-based models like HuBERT and Whisper. They found that these models were able to achieve strong performance on Greek speech recognition tasks, rivaling the accuracy of state-of-the-art models for high-resource languages.
-
Weakly Supervised Approach: The researchers' key insight was to leverage existing podcast data, rather than starting from scratch to build a Greek speech dataset. By using the WhisperX pipeline to automatically align the audio and transcripts, they were able to create a high-quality corpus with minimal manual effort. This demonstrates the power of weakly supervised techniques for building language resources, as explored in related work like Transcribe, Align, Segment and GigaSpeech 2.0.
Critical Analysis
The researchers acknowledge several limitations of their work:
- The Greek podcast corpus, while large, may still not be sufficient to fully capture the diversity of the Greek language, as it is focused on a specific domain (podcasts).
- The automatic alignment process used to create the corpus, while effective, may introduce some errors that could impact model performance.
- The speech recognition models were only evaluated on a limited set of tasks, and their performance on real-world, end-user applications is still to be determined.
Additionally, the paper does not address potential biases or ethical concerns that could arise from using web-scraped data to train language models. As with any machine learning system, there is a risk of amplifying societal biases present in the training data.
Overall, this work represents an important step forward in developing speech technologies for low-resource languages. However, further research is needed to fully understand the limitations and potential societal impacts of these approaches.
Conclusion
This paper presents a novel approach for building high-quality speech recognition models for low-resource languages like Greek. By leveraging existing podcast data and using weakly supervised techniques to create a large training corpus, the researchers were able to train competitive speech models that outperform previous approaches.
This work demonstrates the potential of weakly supervised methods for rapidly developing language resources, which could be a valuable tool for expanding the reach of speech and language technologies to the hundreds of languages around the world that currently have limited digital resources. As the researchers continue to refine and expand this approach, it could lead to significant advances in making speech recognition, translation, and other language technologies more accessible and inclusive.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Ara Yeroyan (Data Science Department, American University of Armenia), Nikolay Karpov (Nvidia, NeMo Conversational AI team)
0
0
In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is portable to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
6/4/2024
🗣️
Transcribe, Align and Segment: Creating speech datasets for low-resource languages
Taras Sereda
0
0
In this work, we showcase a cost-effective method for generating training data for speech processing tasks. First, we transcribe unlabeled speech using a state-of-the-art Automatic Speech Recognition (ASR) model. Next, we align generated transcripts with the audio and apply segmentation on short utterances. Our focus is on ASR for low-resource languages, such as Ukrainian, using podcasts as a source of unlabeled speech. We release a new dataset UK-PODS that features modern conversational Ukrainian language. It contains over 50 hours of text audio-pairs as well as uk-pods-conformer, a 121 M parameters ASR model that is trained on MCV-10 and UK-PODS and achieves 3x reduction of Word Error Rate (WER) on podcasts comparing to publically available uk-nvidia-citrinet while maintaining comparable WER on MCV-10 test split. Both dataset UK-PODS https://huggingface.co/datasets/taras-sereda/uk-pods and ASR uk-pods-conformer https://huggingface.co/taras-sereda/uk-pods-conformer are available on the hugging-face hub.
6/19/2024
New!Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Krishna C. Puvvada, Piotr .Zelasko, He Huang, Oleksii Hrinchuk, Nithin Rao Koluguri, Kunal Dhawan, Somshubra Majumdar, Elena Rastorgueva, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
0
0
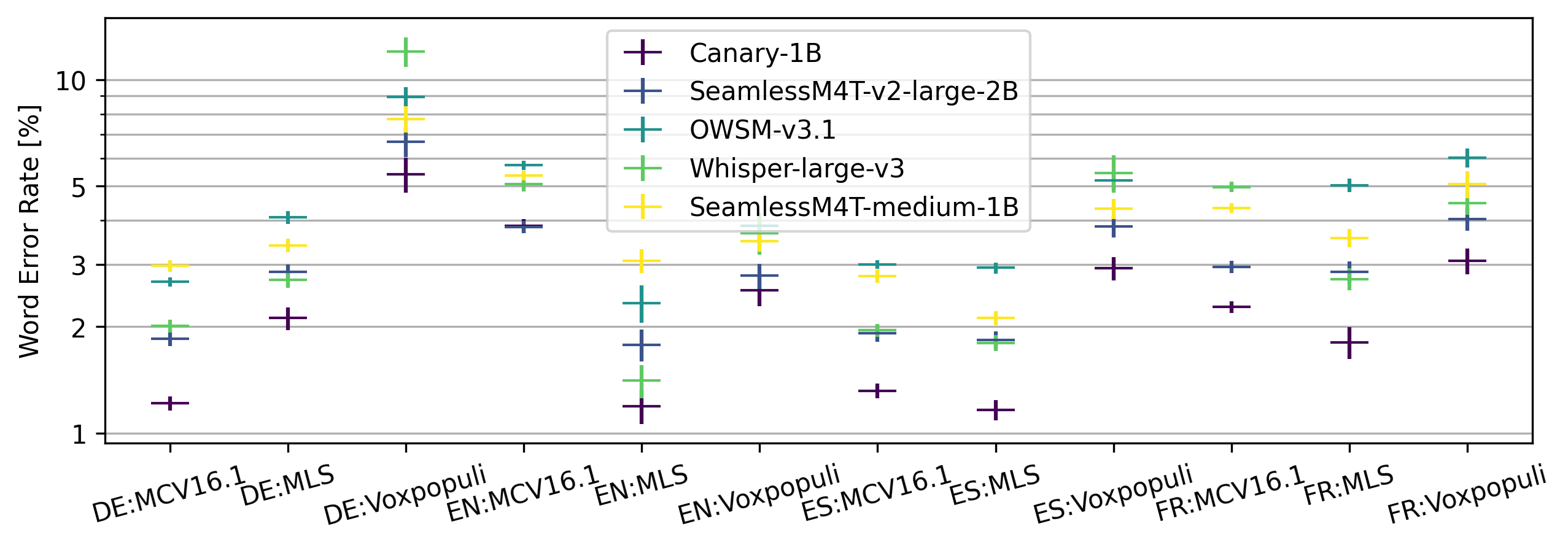
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
7/1/2024

GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
Yifan Yang, Zheshu Song, Jianheng Zhuo, Mingyu Cui, Jinpeng Li, Bo Yang, Yexing Du, Ziyang Ma, Xunying Liu, Ziyuan Wang, Ke Li, Shuai Fan, Kai Yu, Wei-Qiang Zhang, Guoguo Chen, Xie Chen
0
0
The evolution of speech technology has been spurred by the rapid increase in dataset sizes. Traditional speech models generally depend on a large amount of labeled training data, which is scarce for low-resource languages. This paper presents GigaSpeech 2, a large-scale, multi-domain, multilingual speech recognition corpus. It is designed for low-resource languages and does not rely on paired speech and text data. GigaSpeech 2 comprises about 30,000 hours of automatically transcribed speech, including Thai, Indonesian, and Vietnamese, gathered from unlabeled YouTube videos. We also introduce an automated pipeline for data crawling, transcription, and label refinement. Specifically, this pipeline uses Whisper for initial transcription and TorchAudio for forced alignment, combined with multi-dimensional filtering for data quality assurance. A modified Noisy Student Training is developed to further refine flawed pseudo labels iteratively, thus enhancing model performance. Experimental results on our manually transcribed evaluation set and two public test sets from Common Voice and FLEURS confirm our corpus's high quality and broad applicability. Notably, ASR models trained on GigaSpeech 2 can reduce the word error rate for Thai, Indonesian, and Vietnamese on our challenging and realistic YouTube test set by 25% to 40% compared to the Whisper large-v3 model, with merely 10% model parameters. Furthermore, our ASR models trained on Gigaspeech 2 yield superior performance compared to commercial services. We believe that our newly introduced corpus and pipeline will open a new avenue for low-resource speech recognition and significantly facilitate research in this area.
6/18/2024