Whistle: Data-Efficient Multilingual and Crosslingual Speech Recognition via Weakly Phonetic Supervision
2406.02166
0
0

Abstract
There exist three approaches for multilingual and crosslingual automatic speech recognition (MCL-ASR) - supervised pre-training with phonetic or graphemic transcription, and self-supervised pre-training. We find that pre-training with phonetic supervision has been underappreciated so far for MCL-ASR, while conceptually it is more advantageous for information sharing between different languages. This paper explores the approach of pre-training with weakly phonetic supervision towards data-efficient MCL-ASR, which is called Whistle. We relax the requirement of gold-standard human-validated phonetic transcripts, and obtain International Phonetic Alphabet (IPA) based transcription by leveraging the LanguageNet grapheme-to-phoneme (G2P) models. We construct a common experimental setup based on the CommonVoice dataset, called CV-Lang10, with 10 seen languages and 2 unseen languages. A set of experiments are conducted on CV-Lang10 to compare, as fair as possible, the three approaches under the common setup for MCL-ASR. Experiments demonstrate the advantages of phoneme-based models (Whistle) for MCL-ASR, in terms of speech recognition for seen languages, crosslingual performance for unseen languages with different amounts of few-shot data, overcoming catastrophic forgetting, and training efficiency.It is found that when training data is more limited, phoneme supervision can achieve better results compared to subword supervision and self-supervision, thereby providing higher data-efficiency. To support reproducibility and promote future research along this direction, we will release the code, models and data for the whole pipeline of Whistle at https://github.com/thu-spmi/CAT upon publication.
Create account to get full access
Overview
- This paper presents "Whistle", a data-efficient approach for multilingual and crosslingual speech recognition.
- Whistle leverages weakly phonetic supervision to achieve high performance with limited training data, making it suitable for low-resource languages.
- The model is trained to predict International Phonetic Alphabet (IPA) representations of speech, which enables it to generalize across languages.
Plain English Explanation
Whistle is a new speech recognition system that can work well even when you don't have a lot of training data. Traditional speech recognition models need massive amounts of labeled audio data to learn how to transcribe speech accurately. However, many languages around the world don't have large speech datasets available.
Whistle takes a different approach. Instead of trying to directly transcribe speech into text, it learns to predict the International Phonetic Alphabet (IPA) representations of the sounds in the speech. The IPA is a standardized system for representing the sounds of different languages using a common set of symbols. By training Whistle to map speech to IPA, the model can learn patterns that generalize across multiple languages, even with limited data.
This "weakly phonetic supervision" allows Whistle to perform well on both multilingual and crosslingual speech recognition tasks. Multilingual means the model can work for multiple languages, while crosslingual means it can adapt to a new language it wasn't specifically trained on. The key advantage is that Whistle can achieve strong performance without needing huge datasets for every language - it can leverage knowledge learned from other languages to boost performance on low-resource languages.
Technical Explanation
The core innovation in Whistle is the use of weakly phonetic supervision to train the speech recognition model. Instead of directly predicting text transcripts, Whistle is trained to output the IPA representation of the speech. This forces the model to learn general acoustic-phonetic patterns that can generalize across languages.
The Whistle architecture is built around a self-supervised speech encoder that extracts robust speech representations. These representations are then fed into a decoder network that predicts the IPA symbols corresponding to the input speech. By training on multilingual IPA data, the model learns to map speech to a common phonetic space, enabling both multilingual and crosslingual capability.
The authors evaluate Whistle on a range of low-resource speech recognition benchmarks, demonstrating strong performance compared to prior methods. Importantly, Whistle achieves these results with significantly less training data, highlighting its data-efficient nature.
Critical Analysis
The Whistle approach represents an interesting and promising direction for building speech recognition systems that can work well across many languages, even with limited training data. By focusing on the underlying phonetic structure of speech rather than just text transcripts, the model is able to leverage shared acoustic-phonetic patterns to boost performance.
However, the paper does not address some potential limitations of this approach. For example, the IPA representation may not capture all the nuanced pronunciation differences between languages, which could constrain the model's crosslingual capabilities. Additionally, the authors do not explore how Whistle would perform on languages with very different sound systems from those in the training data.
Further research would be needed to fully understand the strengths and weaknesses of the Whistle approach, as well as how it compares to other data-efficient speech recognition techniques like few-shot learning or language-universal speech attribute modeling. Nonetheless, the core ideas behind Whistle represent an exciting step towards more accessible and inclusive speech technology.
Conclusion
The Whistle system demonstrates how data-efficient multilingual and crosslingual speech recognition can be achieved by training models to predict phonetic representations of speech rather than direct text transcripts. This "weakly phonetic supervision" allows the model to learn general acoustic-phonetic patterns that generalize across languages, even with limited training data.
While further research is needed to fully understand the capabilities and limitations of this approach, Whistle represents an important advance in making speech technology more accessible to a wider range of languages and communities around the world. By reducing the data requirements for high-performing speech recognition, systems like Whistle have the potential to enable new applications and open up opportunities for underserved populations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
0
0
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
5/3/2024
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
0
0
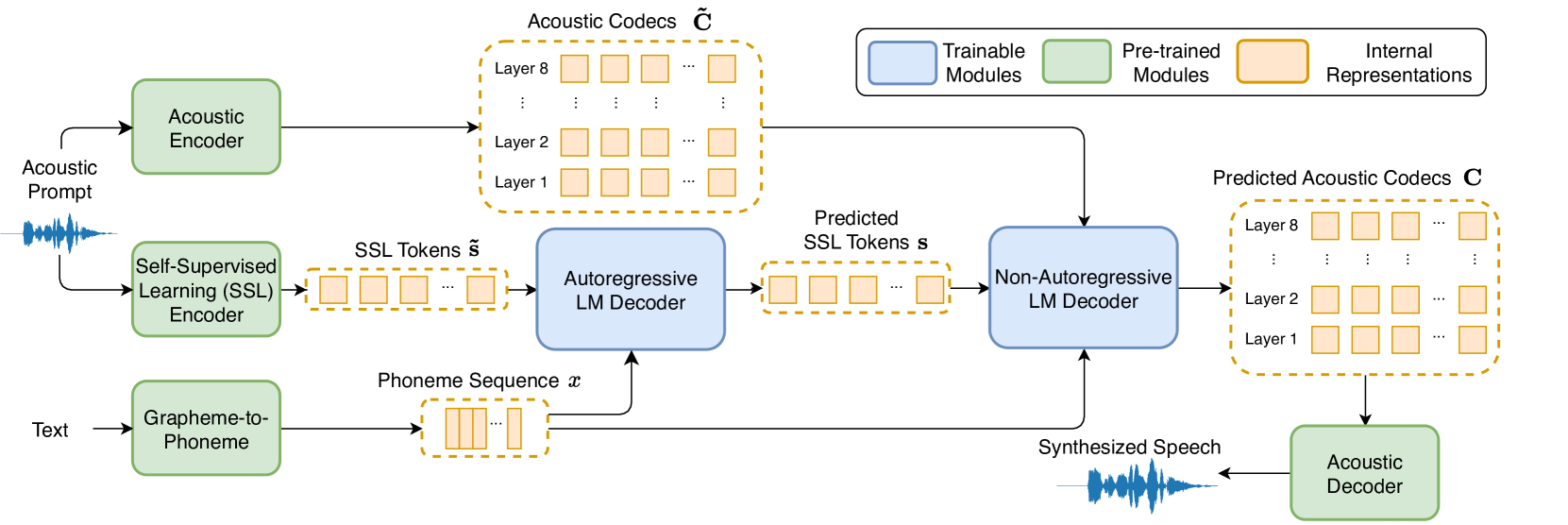
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
6/13/2024
The Greek podcast corpus: Competitive speech models for low-resourced languages with weakly supervised data
Georgios Paraskevopoulos, Chara Tsoukala, Athanasios Katsamanis, Vassilis Katsouros
0
0
The development of speech technologies for languages with limited digital representation poses significant challenges, primarily due to the scarcity of available data. This issue is exacerbated in the era of large, data-intensive models. Recent research has underscored the potential of leveraging weak supervision to augment the pool of available data. In this study, we compile an 800-hour corpus of Modern Greek from podcasts and employ Whisper large-v3 to generate silver transcriptions. This corpus is utilized to fine-tune our models, aiming to assess the efficacy of this approach in enhancing ASR performance. Our analysis spans 16 distinct podcast domains, alongside evaluations on established datasets for Modern Greek. The findings indicate consistent WER improvements, correlating with increases in both data volume and model size. Our study confirms that assembling large, weakly supervised corpora serves as a cost-effective strategy for advancing speech technologies in under-resourced languages.
6/24/2024
Towards Unsupervised Speech Recognition Without Pronunciation Models
Junrui Ni, Liming Wang, Yang Zhang, Kaizhi Qian, Heting Gao, Mark Hasegawa-Johnson, Chang D. Yoo
0
0
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
6/13/2024