GREEN: Generative Radiology Report Evaluation and Error Notation

0
📉
Sign in to get full access
Overview
- This paper introduces a new metric called GREEN (Generative Radiology Report Evaluation and Error Notation) for evaluating the quality of radiology reports generated by language models.
- Existing metrics like BLEU, ROUGE, F1CheXpert, and F1RadGraph either fail to consider factual correctness or have limited interpretability.
- GREEN leverages language models to identify and explain clinically significant errors in candidate radiology reports, providing both quantitative scores and human-interpretable explanations.
Plain English Explanation
When doctors examine medical images like X-rays or MRI scans, they write up detailed reports to describe what they see. Evaluating radiology reports is a challenging problem because these reports need to be factually accurate to support good medical care.
Existing automatic evaluation methods have issues. Some, like BLEU and ROUGE, don't actually check if the report content is correct. Others, like F1CheXpert and F1RadGraph, provide scores but it's hard to understand what they mean.
The new GREEN metric uses language models to identify and explain clinically significant errors in generated radiology reports. It gives both a quantitative score and human-readable explanations of the problems, which can help improve radiology report generation systems and provide useful feedback to users.
Technical Explanation
The paper introduces the GREEN (Generative Radiology Report Evaluation and Error Notation) metric for evaluating radiology report generation. GREEN leverages language models to identify and explain clinically significant errors in candidate reports.
Compared to existing metrics, GREEN offers three key advantages:
- Score aligned with expert preferences: The GREEN score correlates highly with how medical experts would rate the reports.
- Human-interpretable error explanations: GREEN provides detailed natural language descriptions of the errors, enabling feedback loops with end-users.
- Lightweight and performant: GREEN reaches the performance of commercial evaluation tools while being open-source and easy to use.
The authors validate the GREEN metric by comparing it to GPT-4 as well as to error counts from 6 experts and preferences of 2 experts. Their results show that GREEN has higher correlation with expert error counts and better alignment with expert preferences than previous approaches like MRScore, MEDRG, and Systematic Review.
Critical Analysis
The paper makes a compelling case for the need for a better radiology report evaluation metric and demonstrates the effectiveness of the GREEN approach. However, there are a few potential limitations and areas for further research:
- Generalizability: The validation was done on a single dataset, so more testing is needed to ensure the metric generalizes well to other radiology report datasets and modalities.
- Subjective nature of "clinical significance": The definition of "clinically significant" errors is somewhat subjective, and different experts may have different opinions. Further work is needed to standardize this.
- Explainability limitations: While the natural language explanations are a strength, they may still be difficult for non-experts to fully understand. Additional research could explore more intuitive visualizations or interfaces.
- Integration with real-world systems: The paper does not discuss how GREEN could be integrated into actual radiology report generation pipelines. Practical deployment challenges should be explored.
Overall, the GREEN metric represents an important step forward in evaluating radiology reports generated by language models and improving the quality of these reports. Further research building on this work could have significant real-world impact on medical imaging and clinical decision-making.
Conclusion
The GREEN metric introduced in this paper addresses key limitations of existing approaches for evaluating radiology report generation. By leveraging language models to identify and explain clinically significant errors, GREEN provides quantitative scores that align with expert preferences as well as human-interpretable feedback. This offers the potential to improve radiology report generation systems and support more effective communication between clinicians and AI systems in the medical imaging domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
GREEN: Generative Radiology Report Evaluation and Error Notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Bluethgen, Arne Edward Michalson, Michael Moseley, Curtis Langlotz, Akshay S Chaudhari, Jean-Benoit Delbrouck
Evaluating radiology reports is a challenging problem as factual correctness is extremely important due to the need for accurate medical communication about medical images. Existing automatic evaluation metrics either suffer from failing to consider factual correctness (e.g., BLEU and ROUGE) or are limited in their interpretability (e.g., F1CheXpert and F1RadGraph). In this paper, we introduce GREEN (Generative Radiology Report Evaluation and Error Notation), a radiology report generation metric that leverages the natural language understanding of language models to identify and explain clinically significant errors in candidate reports, both quantitatively and qualitatively. Compared to current metrics, GREEN offers: 1) a score aligned with expert preferences, 2) human interpretable explanations of clinically significant errors, enabling feedback loops with end-users, and 3) a lightweight open-source method that reaches the performance of commercial counterparts. We validate our GREEN metric by comparing it to GPT-4, as well as to error counts of 6 experts and preferences of 2 experts. Our method demonstrates not only higher correlation with expert error counts, but simultaneously higher alignment with expert preferences when compared to previous approaches.
Read more5/7/2024

0
X-ray Made Simple: Radiology Report Generation and Evaluation with Layman's Terms
Kun Zhao, Chenghao Xiao, Chen Tang, Bohao Yang, Kai Ye, Noura Al Moubayed, Liang Zhan, Chenghua Lin
Radiology Report Generation (RRG) has achieved significant progress with the advancements of multimodal generative models. However, the evaluation in the domain suffers from a lack of fair and robust metrics. We reveal that, high performance on RRG with existing lexical-based metrics (e.g. BLEU) might be more of a mirage - a model can get a high BLEU only by learning the template of reports. This has become an urgent problem for RRG due to the highly patternized nature of these reports. In this work, we un-intuitively approach this problem by proposing the Layman's RRG framework, a layman's terms-based dataset, evaluation and training framework that systematically improves RRG with day-to-day language. We first contribute the translated Layman's terms dataset. Building upon the dataset, we then propose a semantics-based evaluation method, which is proved to mitigate the inflated numbers of BLEU and provides fairer evaluation. Last, we show that training on the layman's terms dataset encourages models to focus on the semantics of the reports, as opposed to overfitting to learning the report templates. We reveal a promising scaling law between the number of training examples and semantics gain provided by our dataset, compared to the inverse pattern brought by the original formats. Our code is available at url{https://github.com/hegehongcha/LaymanRRG}.
Read more7/2/2024

0
MRScore: Evaluating Radiology Report Generation with LLM-based Reward System
Yunyi Liu, Zhanyu Wang, Yingshu Li, Xinyu Liang, Lingqiao Liu, Lei Wang, Luping Zhou
In recent years, automated radiology report generation has experienced significant growth. This paper introduces MRScore, an automatic evaluation metric tailored for radiology report generation by leveraging Large Language Models (LLMs). Conventional NLG (natural language generation) metrics like BLEU are inadequate for accurately assessing the generated radiology reports, as systematically demonstrated by our observations within this paper. To address this challenge, we collaborated with radiologists to develop a framework that guides LLMs for radiology report evaluation, ensuring alignment with human analysis. Our framework includes two key components: i) utilizing GPT to generate large amounts of training data, i.e., reports with different qualities, and ii) pairing GPT-generated reports as accepted and rejected samples and training LLMs to produce MRScore as the model reward. Our experiments demonstrate MRScore's higher correlation with human judgments and superior performance in model selection compared to traditional metrics. Our code and datasets will be available on GitHub.
Read more4/30/2024
0
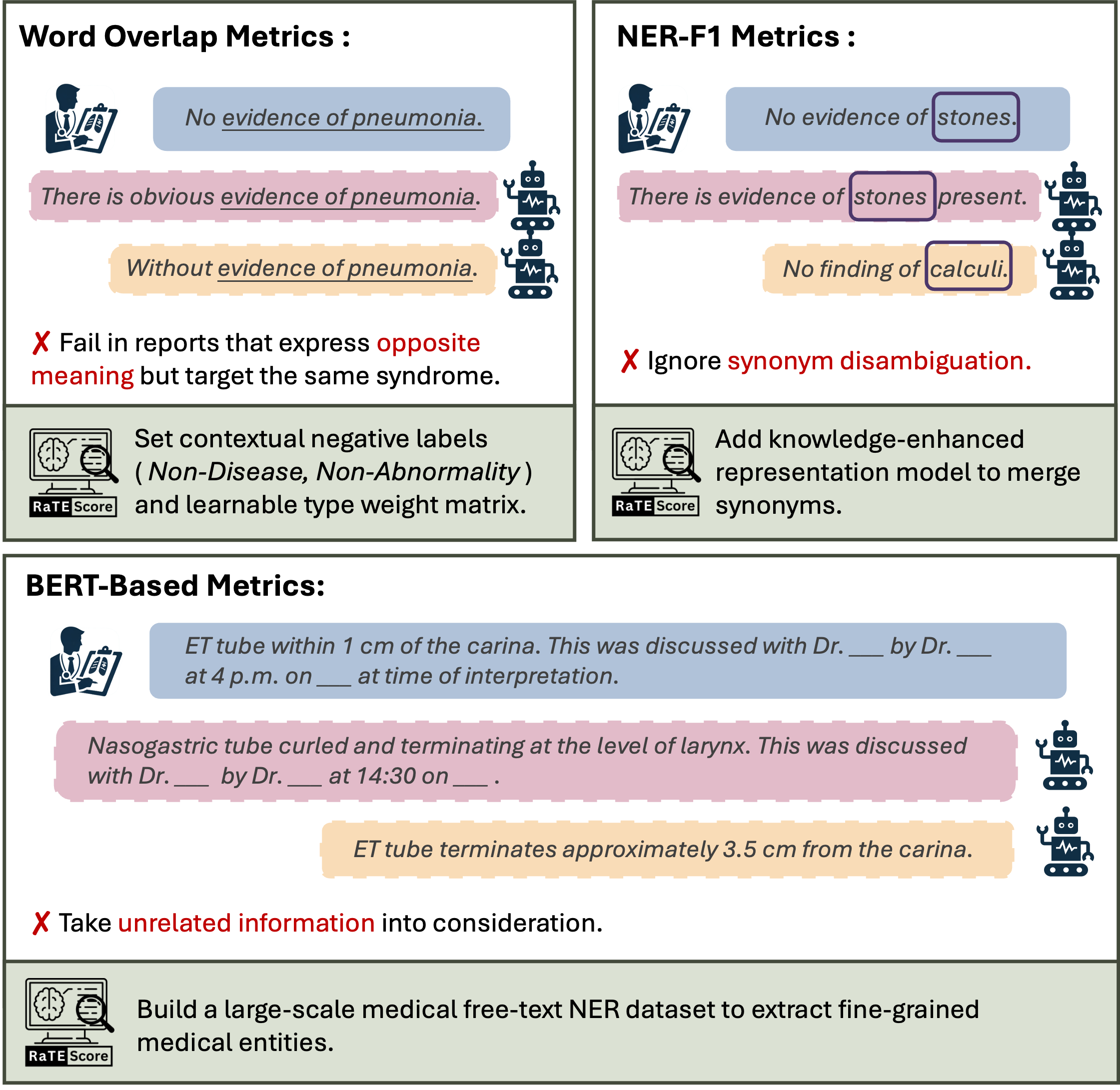
RaTEScore: A Metric for Radiology Report Generation
Weike Zhao, Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, Weidi Xie
This paper introduces a novel, entity-aware metric, termed as Radiological Report (Text) Evaluation (RaTEScore), to assess the quality of medical reports generated by AI models. RaTEScore emphasizes crucial medical entities such as diagnostic outcomes and anatomical details, and is robust against complex medical synonyms and sensitive to negation expressions. Technically, we developed a comprehensive medical NER dataset, RaTE-NER, and trained an NER model specifically for this purpose. This model enables the decomposition of complex radiological reports into constituent medical entities. The metric itself is derived by comparing the similarity of entity embeddings, obtained from a language model, based on their types and relevance to clinical significance. Our evaluations demonstrate that RaTEScore aligns more closely with human preference than existing metrics, validated both on established public benchmarks and our newly proposed RaTE-Eval benchmark.
Read more6/26/2024