Grid-Mapping Pseudo-Count Constraint for Offline Reinforcement Learning

0
Sign in to get full access
Overview
- This paper proposes a "Grid-Mapping Pseudo-Count Constraint" to improve offline reinforcement learning, a technique that allows AI systems to learn from pre-existing data without requiring real-time interactions.
- The key idea is to leverage a grid-based representation of the environment to estimate the novelty or uncertainty of different states, which can then be used to guide the reinforcement learning process.
- The authors demonstrate that this approach can lead to significant performance improvements on a range of benchmark tasks compared to other offline reinforcement learning methods.
Plain English Explanation
Reinforcement learning is a powerful technique that allows AI systems to learn by interacting with an environment and receiving rewards or penalties for their actions. However, in many real-world scenarios, it may not be possible for the system to directly interact with the environment. This is where offline reinforcement learning comes in - the system can learn from pre-existing data, without the need for real-time interactions.
The key challenge in offline reinforcement learning is that the system may encounter states or situations that it has not seen before in the training data. This can lead to poor performance, as the system may not know how to respond appropriately. The Grid-Mapping Pseudo-Count Constraint proposed in this paper aims to address this issue.
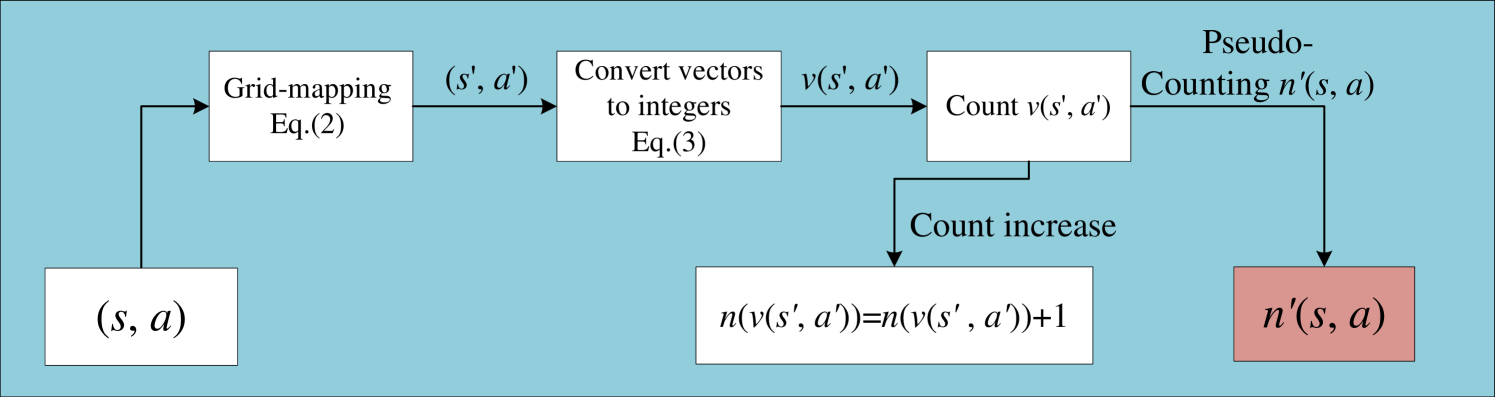
The idea is to divide the environment into a grid, similar to how a map might be divided into a grid of cells. For each cell in the grid, the system can estimate how novel or uncertain the states within that cell are, based on the training data. This "pseudo-count" information can then be used to guide the reinforcement learning process, encouraging the system to explore areas of the environment that it is less familiar with.
By incorporating this grid-based novelty estimation, the authors show that their approach can significantly outperform other offline reinforcement learning methods on a variety of benchmark tasks. This suggests that the Grid-Mapping Pseudo-Count Constraint could be a valuable tool for applying reinforcement learning in real-world scenarios where direct interaction with the environment is not feasible.
Technical Explanation
The paper begins by introducing the problem of offline reinforcement learning, where an agent must learn from a pre-collected dataset of observations, actions, and rewards, without the ability to interact with the environment in real-time. The authors note that a key challenge in this setting is that the agent may encounter novel states during deployment that were not well-represented in the training data.
To address this, the authors propose the Grid-Mapping Pseudo-Count Constraint (GMPCC). The core idea is to maintain a grid-based representation of the environment, where each grid cell stores a pseudo-count of the number of unique states that have been observed within that cell. This pseudo-count is used to estimate the novelty or uncertainty associated with different regions of the state space, and this information is then incorporated into the reinforcement learning process to encourage exploration of unfamiliar areas.
Specifically, the authors define a pseudo-count function that estimates the number of unique states in each grid cell based on the training data. This pseudo-count is then used to augment the reward function during reinforcement learning, with a penalty applied to states that are deemed to be more familiar or certain.
The authors evaluate their approach on a range of continuous control benchmark tasks, comparing it to several other offline reinforcement learning methods. The results demonstrate that the GMPCC approach consistently outperforms the baselines, suggesting that the grid-based novelty estimation can be a valuable tool for improving the performance of offline reinforcement learning agents.
Critical Analysis
The Grid-Mapping Pseudo-Count Constraint presented in this paper is a novel and promising approach for addressing the challenges of offline reinforcement learning. By incorporating a grid-based representation of the environment and using this to estimate the novelty or uncertainty of different states, the authors have developed a technique that can help agents navigate unfamiliar territory during deployment.
One potential limitation of the approach is that it relies on the assumption that the environment can be effectively represented by a grid-based structure. In more complex or irregular environments, this may not always be the case, and the authors acknowledge that alternative representations may be necessary.
Additionally, the authors note that their approach is primarily focused on continuous control tasks, and it remains to be seen how well it would generalize to other types of reinforcement learning problems, such as discrete decision-making or partially observable environments.
Finally, while the authors demonstrate significant performance improvements on the benchmark tasks, it would be valuable to see further analysis of the limitations and failure modes of the GMPCC approach. This could help researchers and practitioners better understand the conditions under which the method is most effective, as well as areas for future refinement and development.
Conclusion
The Grid-Mapping Pseudo-Count Constraint proposed in this paper represents an important contribution to the field of offline reinforcement learning. By leveraging a grid-based representation of the environment to estimate state novelty, the authors have developed a technique that can help agents navigate unfamiliar territory and achieve superior performance on a range of benchmark tasks.
As offline reinforcement learning continues to grow in importance for real-world applications, approaches like the GMPCC could become increasingly valuable tools for enabling AI systems to learn effectively from pre-existing data. While the method has some limitations and areas for further exploration, this paper demonstrates the potential of incorporating grid-based representations and novelty estimation into the reinforcement learning process.
Overall, this research represents a significant step forward in the field of offline reinforcement learning, and the insights and techniques developed here may have broader implications for the development of more robust and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Grid-Mapping Pseudo-Count Constraint for Offline Reinforcement Learning
Yi Shen, Hanyan Huang, Shan Xie
Offline reinforcement learning learns from a static dataset without interacting with the environment, which ensures security and thus owns a good prospect of application. However, directly applying naive reinforcement learning methods usually fails in an offline environment due to function approximation errors caused by out-of-distribution(OOD) actions. To solve this problem, existing algorithms mainly penalize the Q-value of OOD actions, the quality of whose constraints also matter. Imprecise constraints may lead to suboptimal solutions, while precise constraints require significant computational costs. In this paper, we propose a novel count-based method for continuous domains, called Grid-Mapping Pseudo-Count method(GPC), to penalize the Q-value appropriately and reduce the computational cost. The proposed method maps the state and action space to discrete space and constrains their Q-values through the pseudo-count. It is theoretically proved that only a few conditions are needed to obtain accurate uncertainty constraints in the proposed method. Moreover, we develop a Grid-Mapping Pseudo-Count Soft Actor-Critic(GPC-SAC) algorithm using GPC under the Soft Actor-Critic(SAC) framework to demonstrate the effectiveness of GPC. The experimental results on D4RL benchmark datasets show that GPC-SAC has better performance and less computational cost compared to other algorithms.
Read more4/4/2024

0
Strategically Conservative Q-Learning
Yutaka Shimizu, Joey Hong, Sergey Levine, Masayoshi Tomizuka
Offline reinforcement learning (RL) is a compelling paradigm to extend RL's practical utility by leveraging pre-collected, static datasets, thereby avoiding the limitations associated with collecting online interactions. The major difficulty in offline RL is mitigating the impact of approximation errors when encountering out-of-distribution (OOD) actions; doing so ineffectively will lead to policies that prefer OOD actions, which can lead to unexpected and potentially catastrophic results. Despite the variety of works proposed to address this issue, they tend to excessively suppress the value function in and around OOD regions, resulting in overly pessimistic value estimates. In this paper, we propose a novel framework called Strategically Conservative Q-Learning (SCQ) that distinguishes between OOD data that is easy and hard to estimate, ultimately resulting in less conservative value estimates. Our approach exploits the inherent strengths of neural networks to interpolate, while carefully navigating their limitations in extrapolation, to obtain pessimistic yet still property calibrated value estimates. Theoretical analysis also shows that the value function learned by SCQ is still conservative, but potentially much less so than that of Conservative Q-learning (CQL). Finally, extensive evaluation on the D4RL benchmark tasks shows our proposed method outperforms state-of-the-art methods. Our code is available through url{https://github.com/purewater0901/SCQ}.
Read more6/10/2024
🏅
0
Exclusively Penalized Q-learning for Offline Reinforcement Learning
Junghyuk Yeom, Yonghyeon Jo, Jungmo Kim, Sanghyeon Lee, Seungyul Han
Constraint-based offline reinforcement learning (RL) involves policy constraints or imposing penalties on the value function to mitigate overestimation errors caused by distributional shift. This paper focuses on a limitation in existing offline RL methods with penalized value function, indicating the potential for underestimation bias due to unnecessary bias introduced in the value function. To address this concern, we propose Exclusively Penalized Q-learning (EPQ), which reduces estimation bias in the value function by selectively penalizing states that are prone to inducing estimation errors. Numerical results show that our method significantly reduces underestimation bias and improves performance in various offline control tasks compared to other offline RL methods
Read more5/24/2024

0
Budgeting Counterfactual for Offline RL
Yao Liu, Pratik Chaudhari, Rasool Fakoor
The main challenge of offline reinforcement learning, where data is limited, arises from a sequence of counterfactual reasoning dilemmas within the realm of potential actions: What if we were to choose a different course of action? These circumstances frequently give rise to extrapolation errors, which tend to accumulate exponentially with the problem horizon. Hence, it becomes crucial to acknowledge that not all decision steps are equally important to the final outcome, and to budget the number of counterfactual decisions a policy make in order to control the extrapolation. Contrary to existing approaches that use regularization on either the policy or value function, we propose an approach to explicitly bound the amount of out-of-distribution actions during training. Specifically, our method utilizes dynamic programming to decide where to extrapolate and where not to, with an upper bound on the decisions different from behavior policy. It balances between the potential for improvement from taking out-of-distribution actions and the risk of making errors due to extrapolation. Theoretically, we justify our method by the constrained optimality of the fixed point solution to our $Q$ updating rules. Empirically, we show that the overall performance of our method is better than the state-of-the-art offline RL methods on tasks in the widely-used D4RL benchmarks.
Read more5/22/2024