Grokking at the Edge of Linear Separability

62

Sign in to get full access
Overview
- Examines the phenomenon of "grokking" - where neural networks suddenly learn to generalize well after a period of poor performance
- Focuses on the role of linear separability in this process, exploring how networks can learn to generalize at the "edge" of linear separability
- Provides insights into the complex relationship between network complexity, training data, and generalization capabilities
Plain English Explanation
The paper explores an intriguing phenomenon known as "grokking" that occurs in neural networks. <a href="https://aimodels.fyi/papers/arxiv/grokking-as-transition-from-lazy-to-rich">Grokking</a> refers to the sudden ability of a network to generalize well, after an initial period of poor performance.
The researchers focus on how this process is related to the linear separability of the training data. <a href="https://aimodels.fyi/papers/arxiv/why-do-you-grok-theoretical-analysis-grokking">Linear separability</a> means the data can be perfectly divided by a straight line or hyperplane. The researchers investigate what happens when networks are trained on data at the "edge" of linear separability - where the data is almost, but not quite, linearly separable.
They find that networks can learn to leverage this near-linear structure to suddenly achieve strong generalization performance, even though they initially struggled. This sheds light on the complex interplay between a network's complexity, the properties of the training data, and its ability to generalize to new examples.
Technical Explanation
The paper examines the phenomenon of "grokking" in binary classification tasks, where neural networks initially perform poorly but then suddenly learn to generalize well.
The key focus is on how this process relates to the linear separability of the training data. When data is linearly separable, it can be perfectly divided by a straight line or hyperplane. But the researchers explore what happens when data is "at the edge" of linear separability - not quite linearly separable, but very close.
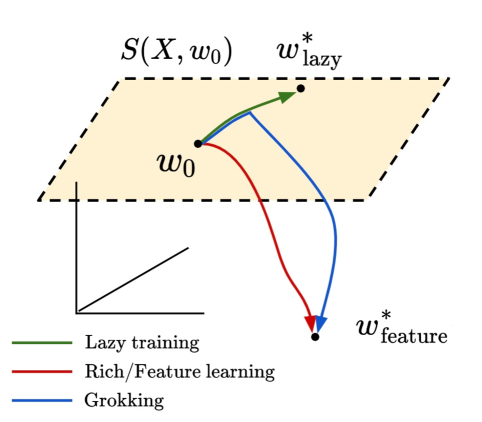
Through extensive experiments, they find that neural networks can leverage this near-linear structure to learn effective representations and generalize well, even though they initially struggled. This suggests the networks are able to transition from a "lazy" learning regime, where they simply fit the training data, to a "rich" learning regime where they discover more complex but powerful features.
The paper provides detailed analysis of the network architectures, training dynamics, and the role of data properties like input dimensionality in enabling this grokking behavior. It offers insights into the complex interplay between network complexity, training data, and generalization capabilities.
Critical Analysis
The paper provides a well-designed experimental setup and rigorous analysis to shed light on the fascinating phenomenon of grokking in neural networks. However, the authors acknowledge several caveats and limitations to their work:
- The study is focused on binary classification tasks, so the findings may not generalize to more complex, multi-class problems.
- The analysis is limited to fully-connected neural networks, and it's unclear if the same dynamics would hold for convolutional or other specialized architectures.
- The paper does not explore the impact of hyperparameter choices, dataset size, or other key factors that could influence the grokking behavior.
Additionally, while the paper offers valuable insights, there are some open questions that could be explored in future research:
- How universal is the grokking phenomenon - do all networks exhibit this behavior, or are there certain architectures, tasks or datasets where it is more or less pronounced? <a href="https://aimodels.fyi/papers/arxiv/deep-networks-always-grok-here-is-why">What are the fundamental mechanisms</a> that enable networks to transition from poor to strong generalization?
- Can the insights from this work be leveraged to improve training procedures or architectural design to reliably induce grokking in practical applications?
Overall, the paper makes a compelling contribution to our understanding of neural network generalization, but there remains much to explore in this intriguing area of research.
Conclusion
This paper offers important insights into the phenomenon of "grokking" in neural networks - the sudden ability of a model to generalize well, after an initial period of poor performance.
By focusing on the role of linear separability, the researchers shed light on how networks can leverage the underlying structure of training data to learn powerful representations and achieve strong generalization, even on tasks that are not perfectly linearly separable.
The findings highlight the complex interplay between network architecture, training data, and generalization capabilities. While the study has some limitations, it opens up promising avenues for further exploration into the fundamental mechanisms that enable this grokking behavior.
Ultimately, a deeper understanding of grokking could lead to improvements in neural network training and design, allowing us to build more robust and reliable models for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
62
Grokking at the Edge of Linear Separability
Alon Beck, Noam Levi, Yohai Bar-Sinai
We study the generalization properties of binary logistic classification in a simplified setting, for which a memorizing and generalizing solution can always be strictly defined, and elucidate empirically and analytically the mechanism underlying Grokking in its dynamics. We analyze the asymptotic long-time dynamics of logistic classification on a random feature model with a constant label and show that it exhibits Grokking, in the sense of delayed generalization and non-monotonic test loss. We find that Grokking is amplified when classification is applied to training sets which are on the verge of linear separability. Even though a perfect generalizing solution always exists, we prove the implicit bias of the logisitc loss will cause the model to overfit if the training data is linearly separable from the origin. For training sets that are not separable from the origin, the model will always generalize perfectly asymptotically, but overfitting may occur at early stages of training. Importantly, in the vicinity of the transition, that is, for training sets that are almost separable from the origin, the model may overfit for arbitrarily long times before generalizing. We gain more insights by examining a tractable one-dimensional toy model that quantitatively captures the key features of the full model. Finally, we highlight intriguing common properties of our findings with recent literature, suggesting that grokking generally occurs in proximity to the interpolation threshold, reminiscent of critical phenomena often observed in physical systems.
Read more10/8/2024
0
Grokking as the Transition from Lazy to Rich Training Dynamics
Tanishq Kumar, Blake Bordelon, Samuel J. Gershman, Cengiz Pehlevan
We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics to a rich, feature learning regime. To illustrate this mechanism, we study the simple setting of vanilla gradient descent on a polynomial regression problem with a two layer neural network which exhibits grokking without regularization in a way that cannot be explained by existing theories. We identify sufficient statistics for the test loss of such a network, and tracking these over training reveals that grokking arises in this setting when the network first attempts to fit a kernel regression solution with its initial features, followed by late-time feature learning where a generalizing solution is identified after train loss is already low. We find that the key determinants of grokking are the rate of feature learning -- which can be controlled precisely by parameters that scale the network output -- and the alignment of the initial features with the target function $y(x)$. We argue this delayed generalization arises when (1) the top eigenvectors of the initial neural tangent kernel and the task labels $y(x)$ are misaligned, but (2) the dataset size is large enough so that it is possible for the network to generalize eventually, but not so large that train loss perfectly tracks test loss at all epochs, and (3) the network begins training in the lazy regime so does not learn features immediately. We conclude with evidence that this transition from lazy (linear model) to rich training (feature learning) can control grokking in more general settings, like on MNIST, one-layer Transformers, and student-teacher networks.
Read more4/12/2024
👨🏫
0
Why Do You Grok? A Theoretical Analysis of Grokking Modular Addition
Mohamad Amin Mohamadi, Zhiyuan Li, Lei Wu, Danica J. Sutherland
We present a theoretical explanation of the ``grokking'' phenomenon, where a model generalizes long after overfitting,for the originally-studied problem of modular addition. First, we show that early in gradient descent, when the ``kernel regime'' approximately holds, no permutation-equivariant model can achieve small population error on modular addition unless it sees at least a constant fraction of all possible data points. Eventually, however, models escape the kernel regime. We show that two-layer quadratic networks that achieve zero training loss with bounded $ell_{infty}$ norm generalize well with substantially fewer training points, and further show such networks exist and can be found by gradient descent with small $ell_{infty}$ regularization. We further provide empirical evidence that these networks as well as simple Transformers, leave the kernel regime only after initially overfitting. Taken together, our results strongly support the case for grokking as a consequence of the transition from kernel-like behavior to limiting behavior of gradient descent on deep networks.
Read more7/18/2024
0
Deep Networks Always Grok and Here is Why
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk
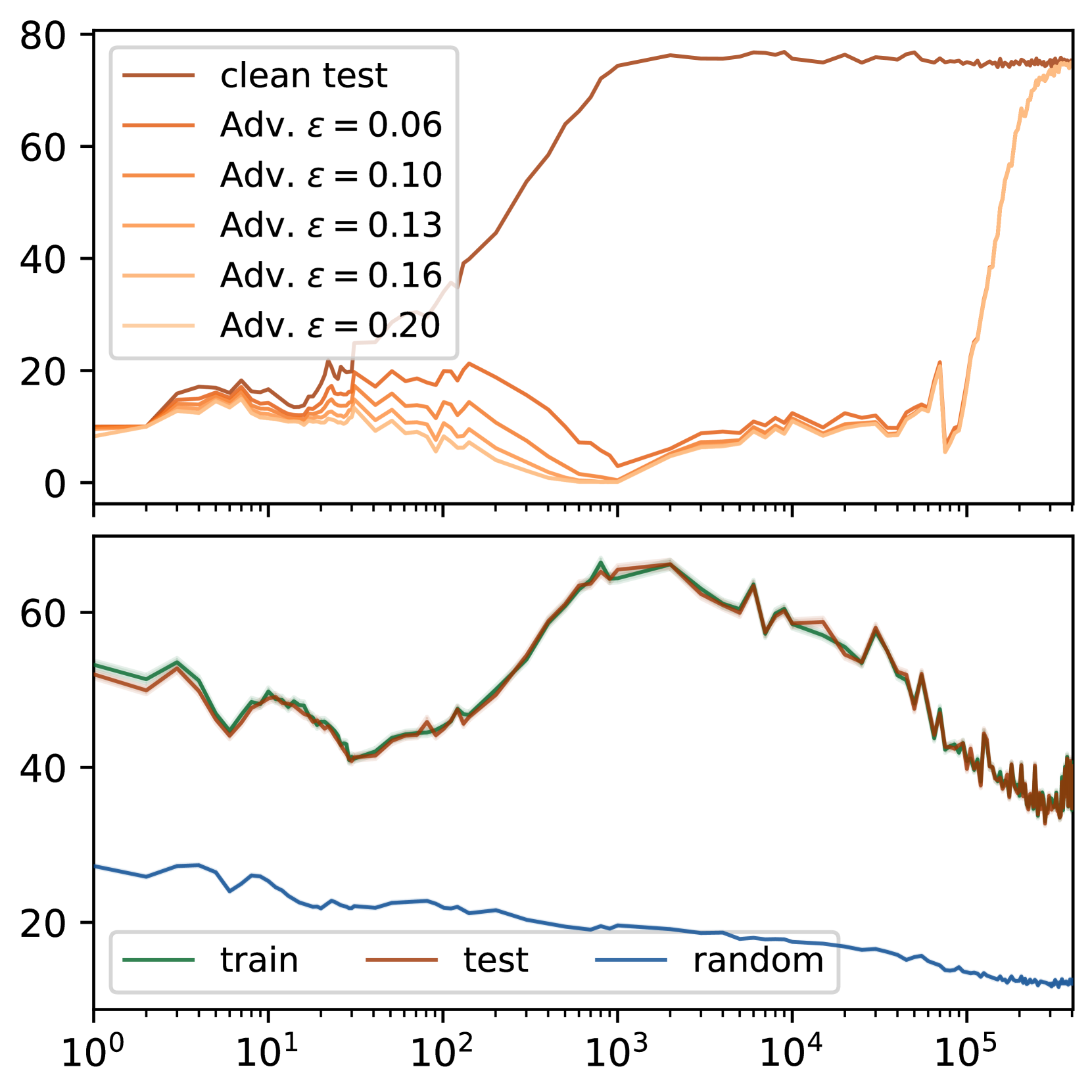
Grokking, or delayed generalization, is a phenomenon where generalization in a deep neural network (DNN) occurs long after achieving near zero training error. Previous studies have reported the occurrence of grokking in specific controlled settings, such as DNNs initialized with large-norm parameters or transformers trained on algorithmic datasets. We demonstrate that grokking is actually much more widespread and materializes in a wide range of practical settings, such as training of a convolutional neural network (CNN) on CIFAR10 or a Resnet on Imagenette. We introduce the new concept of delayed robustness, whereby a DNN groks adversarial examples and becomes robust, long after interpolation and/or generalization. We develop an analytical explanation for the emergence of both delayed generalization and delayed robustness based on the local complexity of a DNN's input-output mapping. Our local complexity measures the density of so-called linear regions (aka, spline partition regions) that tile the DNN input space and serves as a utile progress measure for training. We provide the first evidence that, for classification problems, the linear regions undergo a phase transition during training whereafter they migrate away from the training samples (making the DNN mapping smoother there) and towards the decision boundary (making the DNN mapping less smooth there). Grokking occurs post phase transition as a robust partition of the input space thanks to the linearization of the DNN mapping around the training points. Website: https://bit.ly/grok-adversarial
Read more6/10/2024