Grounded Relational Inference: Domain Knowledge Driven Explainable Autonomous Driving

0
🗣️
Sign in to get full access
Overview
- Explainability is crucial for autonomous vehicles and robotics systems to interact safely and earn human trust.
- The paper proposes an explainable model called Grounded Relational Inference (GRI) that can model multi-agent interactions and generate semantic explanations grounded in expert domain knowledge.
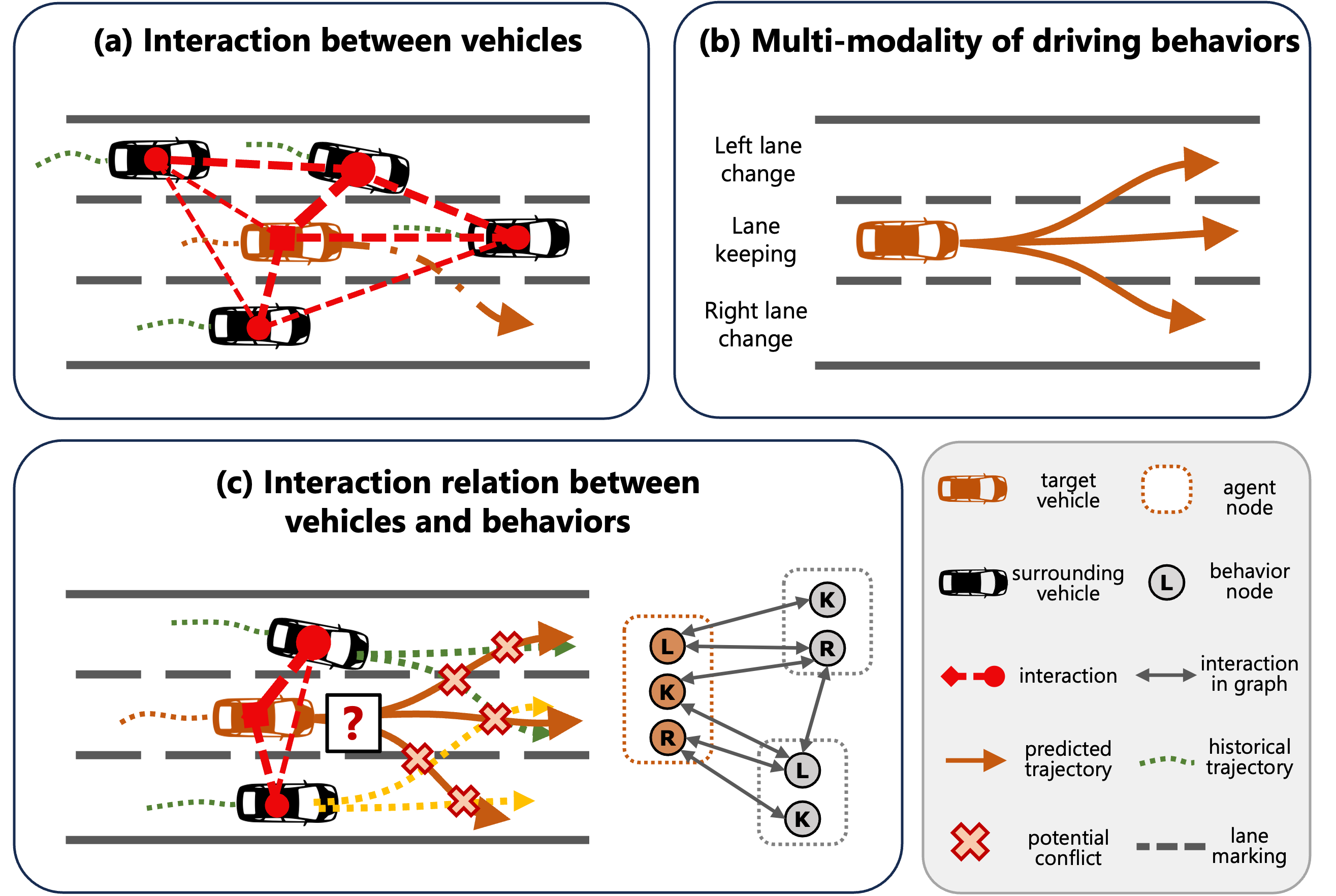
- GRI infers an interaction graph representing the relationships between agents, ensuring the graph is meaningful by aligning it with defined interactive behaviors.
- The model is evaluated on both simulated and real-world traffic scenarios, demonstrating its ability to model interactions and provide human-understandable explanations of vehicle behavior.
Plain English Explanation
Autonomous vehicles and other robotic systems need to be able to explain their actions to humans in a way that is easy to understand. This is essential for building trust and enabling safe cooperation between humans and machines.
The proposed model, Grounded Relational Inference (GRI), tackles a key component of autonomous driving - modeling how different vehicles and other agents interact with each other. GRI builds an "interaction graph" that represents the relationships between the agents. Importantly, this graph is grounded in expert knowledge about common traffic behaviors, ensuring the explanations it generates are meaningful to humans.
For example, GRI might recognize that one car is "following" another car, or that a pedestrian is "crossing the street." By linking the machine's understanding of the interactions to these human-understandable concepts, GRI can provide clear explanations for why the autonomous vehicle is behaving in a certain way - it's responding to the inferred relationships between the agents in the scene.
The researchers tested GRI in both simulated environments and real-world traffic scenarios, showing that it can effectively model these complex multi-agent interactions and generate intuitive, semantically-meaningful explanations of the vehicle's behavior.
Technical Explanation
The Grounded Relational Inference (GRI) model aims to provide explainable predictions of how different agents, such as vehicles and pedestrians, will interact in a traffic scenario. GRI does this by learning an "interaction graph" that represents the relationships between the agents, such as one car following another or a pedestrian crossing the street.
Crucially, GRI grounds this interaction graph in expert-defined semantic behaviors, ensuring the inferred relationships are aligned with human understanding of common traffic interactions. This allows GRI to generate explanations of the autonomous vehicle's behavior that are meaningful and intuitive for human operators and passengers.
The researchers evaluated GRI on both simulated traffic environments and real-world datasets. The results showed that GRI could effectively model the complex dynamics of multi-agent interactions and provide semantically-grounded explanations of the vehicle's actions in response to these interactions.
Critical Analysis
The paper makes a compelling case for the importance of explainability in autonomous driving and other robotic systems that interact with humans. The Grounded Relational Inference (GRI) model represents a promising approach to generating human-understandable explanations by grounding the system's internal representations in expert-defined semantic concepts.
However, the paper does not deeply explore the potential limitations or failure modes of this approach. For example, it's unclear how well GRI would perform in highly complex, crowded traffic scenarios or in the face of unpredictable human behavior. Additionally, the reliance on expert-defined behaviors could make the system less adaptable to new or emerging traffic interactions.
Further research could also explore ways to make the explanation generation process more transparent and open to scrutiny, as well as investigate how these explanations could be effectively incorporated into human-machine interfaces to foster greater trust and collaboration.
Conclusion
This paper presents an important step towards making autonomous vehicles and other robotic systems more transparent and explainable to human users. The Grounded Relational Inference (GRI) model demonstrates how an AI system can learn to model complex multi-agent interactions and generate explanations that are grounded in human-understandable concepts.
As autonomous technologies become more prevalent in our daily lives, this type of explainable AI will be crucial for building trust, enabling safe cooperation, and ensuring that humans can anticipate and understand the actions of these intelligent machines. Further advancements in this area have the potential to significantly improve the integration of autonomous systems into our society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Grounded Relational Inference: Domain Knowledge Driven Explainable Autonomous Driving
Chen Tang, Nishan Srishankar, Sujitha Martin, Masayoshi Tomizuka
Explainability is essential for autonomous vehicles and other robotics systems interacting with humans and other objects during operation. Humans need to understand and anticipate the actions taken by the machines for trustful and safe cooperation. In this work, we aim to develop an explainable model that generates explanations consistent with both human domain knowledge and the model's inherent causal relation. In particular, we focus on an essential building block of autonomous driving, multi-agent interaction modeling. We propose Grounded Relational Inference (GRI). It models an interactive system's underlying dynamics by inferring an interaction graph representing the agents' relations. We ensure a semantically meaningful interaction graph by grounding the relational latent space into semantic interactive behaviors defined with expert domain knowledge. We demonstrate that it can model interactive traffic scenarios under both simulation and real-world settings, and generate semantic graphs explaining the vehicle's behavior by their interactions.
Read more7/9/2024

0
RAG-based Explainable Prediction of Road Users Behaviors for Automated Driving using Knowledge Graphs and Large Language Models
Mohamed Manzour Hussien, Angie Nataly Melo, Augusto Luis Ballardini, Carlota Salinas Maldonado, Rub'en Izquierdo, Miguel 'Angel Sotelo
Prediction of road users' behaviors in the context of autonomous driving has gained considerable attention by the scientific community in the last years. Most works focus on predicting behaviors based on kinematic information alone, a simplification of the reality since road users are humans, and as such they are highly influenced by their surrounding context. In addition, a large plethora of research works rely on powerful Deep Learning techniques, which exhibit high performance metrics in prediction tasks but may lack the ability to fully understand and exploit the contextual semantic information contained in the road scene, not to mention their inability to provide explainable predictions that can be understood by humans. In this work, we propose an explainable road users' behavior prediction system that integrates the reasoning abilities of Knowledge Graphs (KG) and the expressiveness capabilities of Large Language Models (LLM) by using Retrieval Augmented Generation (RAG) techniques. For that purpose, Knowledge Graph Embeddings (KGE) and Bayesian inference are combined to allow the deployment of a fully inductive reasoning system that enables the issuing of predictions that rely on legacy information contained in the graph as well as on current evidence gathered in real time by onboard sensors. Two use cases have been implemented following the proposed approach: 1) Prediction of pedestrians' crossing actions; 2) Prediction of lane change maneuvers. In both cases, the performance attained surpasses the current state of the art in terms of anticipation and F1-score, showing a promising avenue for future research in this field.
Read more5/2/2024
0
New!Hypergraph-based Motion Generation with Multi-modal Interaction Relational Reasoning
Keshu Wu, Yang Zhou, Haotian Shi, Dominique Lord, Bin Ran, Xinyue Ye
The intricate nature of real-world driving environments, characterized by dynamic and diverse interactions among multiple vehicles and their possible future states, presents considerable challenges in accurately predicting the motion states of vehicles and handling the uncertainty inherent in the predictions. Addressing these challenges requires comprehensive modeling and reasoning to capture the implicit relations among vehicles and the corresponding diverse behaviors. This research introduces an integrated framework for autonomous vehicles (AVs) motion prediction to address these complexities, utilizing a novel Relational Hypergraph Interaction-informed Neural mOtion generator (RHINO). RHINO leverages hypergraph-based relational reasoning by integrating a multi-scale hypergraph neural network to model group-wise interactions among multiple vehicles and their multi-modal driving behaviors, thereby enhancing motion prediction accuracy and reliability. Experimental validation using real-world datasets demonstrates the superior performance of this framework in improving predictive accuracy and fostering socially aware automated driving in dynamic traffic scenarios.
Read more9/19/2024

0
RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
Jianhao Yuan, Shuyang Sun, Daniel Omeiza, Bo Zhao, Paul Newman, Lars Kunze, Matthew Gadd
We need to trust robots that use often opaque AI methods. They need to explain themselves to us, and we need to trust their explanation. In this regard, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
Read more5/30/2024